本文提出了 SegVGGT,这是一个统一的端到端前馈框架,能够直接从非位姿多视图 RGB 图像中同步实现 3D 场景重建与实例分割。该方法通过将 Object Queries 深度集成到视觉几何接地 Transformer (VGGT) 中,在 ScanNetv2/200 等基准测试中达到了 SOTA 性能。
TL;DR
长期以来,3D 实例分割一直深受“多阶段流程”之苦:必须先进行相机配准、深度融合、点云去噪,最后才能谈分割。SegVGGT 横空出世,打破了这一僵局。它采用统一的 前馈 Transformer 架构,仅需一组无位姿的 RGB 图片,就能在一次前向传播中同时输出高精度 3D 几何和实例掩码。其核心 FADA 策略更是巧妙地解决了长序列图像带来的注意力分散难题。
背景定位:从“碎片化”到“端到端”
在 3D 场景理解领域,现有的 SOTA 方法(如 Mask3D, OneFormer3D)大多假设输入是“完美的点云”。然而在现实中,获取这样的点云需要昂贵的深度传感器和复杂的后期处理。
SegVGGT 的定位非常明确:它是首个将 3D 重建的底层几何特征与实例分割的高层语义 Query 深度耦合的统一框架。 相比于简单的“重建+分割”二阶段流水线,这种架构能够让语义信息反哺几何表达,使得模型对重建噪声具有极强的鲁棒性。
痛点深挖:为何“缝合”模型效果不佳?
作者在文中指出了两个关键痛点:
- 对噪声的脆弱性:点云模型在干净的数据上表现完美,但面对前馈重建产生的带有噪点和位姿偏移的原始数据,性能会断崖式下降(ScanNet200 mAP 从 30.2 掉到 2.5)。
- 注意力色散(Attention Dispersion):在多视图 Transformer 中,图像 Token 数量通常高达 。Object Queries 在这片海量的 token 中由于缺乏引导,很难精准锁定某个特定实例所在的帧,导致收敛缓慢且精度低下。
核心方法:几何感知 Query 与 FADA 策略
1. 深度耦合的架构
SegVGGT 扩展了 VGGT 架构。它在每一层 Transformer 中都加入了 Object Queries。
- Image Tokens:负责捕捉多视图几何信息。
- Object Queries:跨层与图像 Token 进行 Cross-attention,从底层几何空间到高层抽象特征进行演化。
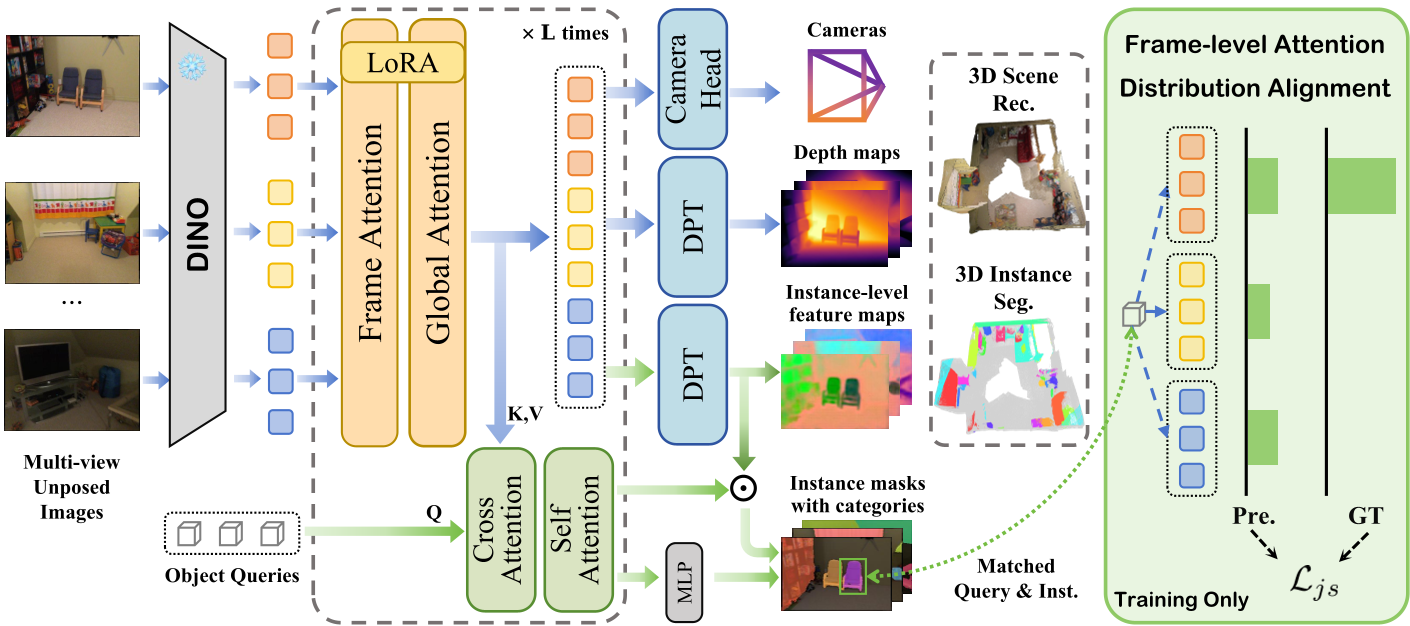
2. 帧级注意力分布对齐 (FADA)
这是本文的神来之笔。为了解决注意力色散,作者提出了 FADA (Frame-level Attention Distribution Alignment)。
- 直觉:一个 3D 物体通常只在少数几帧中可见。
- 法子:计算 Query 在各帧上的注意力权重分布,然后用 JS 散度 强制该分布与物体实际在各帧中出现的像素面积比例(Visibility Prior)一致。
- 优势:这相当于在训练时给了 Queries 一张“地图”,告诉它们去哪里找物体,而在推理时没有任何额外开销。
实验结果:全方位的跨越
1. 惊人的鲁棒性
在 ScanNet200 验证集上,SegVGGT 表现出的性能令人震撼。即便只给它 RGB 图像,其 mAP 依然能与那些拿着“标准点云金标准”的方法(如 Relation3D)一较高下,甚至在处理长尾类别时更胜一筹。

2. 泛化能力:零样本杀入 ScanNet++
最具说服力的是:SegVGGT 在 ScanNet200 上训练,直接去测 ScanNet++,结果竟然超过了那些在 ScanNet++ 训练集上练过的竞争对手(IGGT)。这说明 Query 机制确实抓住了 3D 空间的交互本质。
3. FADA 模块的消融
通过可视化(下图),我们可以清晰地看到:没有 FADA 时,注意力散落在全场;有了 FADA 后,Query 精准地“钉”在了电视机所在的帧和区域。

总结与见解
SegVGGT 的价值在于证明了 几何与语义不需要“分家”。通过集成 Query 机制和设计巧妙的注意力约束,我们可以在极其混乱的原始 RGB 数据中直接“生长”出结构化的 3D 语义世界。
局限性: 尽管强大,该模型目前还无法恢复绝对的度量尺度(Metric Scale),且在面对全新的开放域类别时仍有提升空间。
未来启示: 这种“一边重建、一边理解”的架构,极有可能是通向 Embodied AI(具身智能)的核心感知基石,因为它更接近人类视觉系统的运作逻辑。