SegviGen 是一种将预训练 3D 生成模型重新利用于 3D 零件分割(Part Segmentation)的统一多任务框架。该方法通过将分割任务重构为“零件着色”(Part Colorization)问题,利用生成模型内部丰富的结构与纹理先验,在极少量监督数据下实现了 SOTA 性能。
TL;DR
SegviGen 提出了一种颠覆性的视角:不再将 3D 分割视为枯燥的分类标签预测,而是将其重构为 3D 生成模型擅长的着色任务(Colorization)。通过榨取大规模 3D 生成模型内部积累的结构先验,SegviGen 在仅需 0.32% 标注数据的情况下,将交互式分割准确率提升了 40%,彻底打破了 3D 分割对海量标注的依赖。
痛点深挖:2D 提升 vs 原生 3D 的困局
在 3D 领域,获取精准的“零件级”标注(如椅子的扶手、瓶子的盖子)简直是研究者的噩梦。
- 2D-to-3D Lifting 的无奈:利用 SAM 等强力 2D 模型进行多视角投影再聚合,虽然不需要训练,但经常因为视角遮挡和投影误差导致分割边界模糊、跨视角不一致。
- 原生 3D 判别模型的重负载:像 P3-SAM 这种直接在 3D 空间预测的方法,虽然推断快,但需要“喂”海量的 3D 标注数据,且对未知类别的泛化性极差。
作者的直觉(Insight):大规模 3D 生成模型(如基于 DiT 的 TRELLIS)在学习如何“创造”一个物体时,已经通过几何与纹理的联合建模,在内部掌握了物体的物理边界。如果我们让模型去“画”出这些零件,分割不就自然完成了吗?
方法论详解:分割即着色
SegviGen 的核心在于将分割标签映射到颜色空间。在一个统一的流匹配(Flow-matching)框架下,模型根据不同的输入指令进行“创作”:
1. 任务重构
- 交互式分割:给定一个点击点,模型将目标零件涂成白色,其余涂成黑色。
- 全自动分割:模型自动从一个调色板中选颜色,为不同零件上色(色彩顺序无关紧要,只要分得开)。
- 2D 引导分割:这是 SegviGen 的杀手锏,支持将 2D 参考图的分割粒度直接迁移到 3D 资产上。
2. 架构解析
模型由三个关键部分组成:
- 几何潜变量(Geometry Latent):由冻结的 3D VAE 提取,提供形状基础。
- 任务嵌入(Task Embedding):通过 Sinusoidal 编码告诉模型现在是做“交互式”还是“全自动”模式。
- Sparse Flow Transformer:核心大脑,负责在 3D 空间中根据条件进行颜色生成。
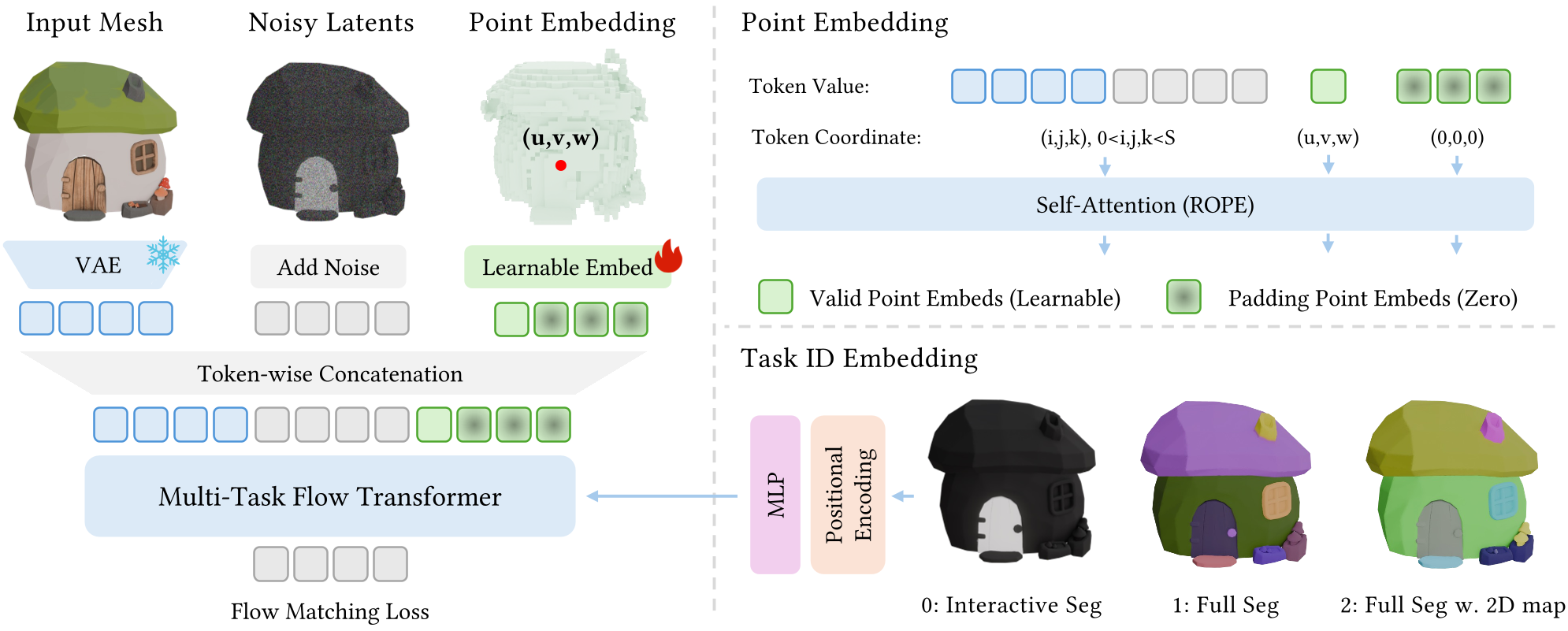 图 1:SegviGen 整体流程,展示了如何将几何潜变量、噪声颜色潜变量以及任务提示词融合在一起进行流匹配训练。
图 1:SegviGen 整体流程,展示了如何将几何潜变量、噪声颜色潜变量以及任务提示词融合在一起进行流匹配训练。
实验与结果:降维打击的效率
SegviGen 的表现可以用“四两拨千斤”来形容。
强大的 Few-shot 分割能力
在交互式分割(Interactive Part-segmentation)中,单次点击(IoU@1)的效果至关重要。
- PartNext 数据集:SegviGen 达到了 54.86% 的 IoU,而此前的 SOTA 方法 Point-SAM 仅为 23.90%。
- 这意味着 SegviGen 只需看一眼点击位置,就能凭借深厚的生成先验通过“想象”补全整个零件的结构。
精准的边界处理
相比于传统方法,SegviGen 生成的分割边界由于得益于生成模型的纹理建模,显得极其锐利(Sharp),避免了常见的“锯齿”或“溢出”问题。
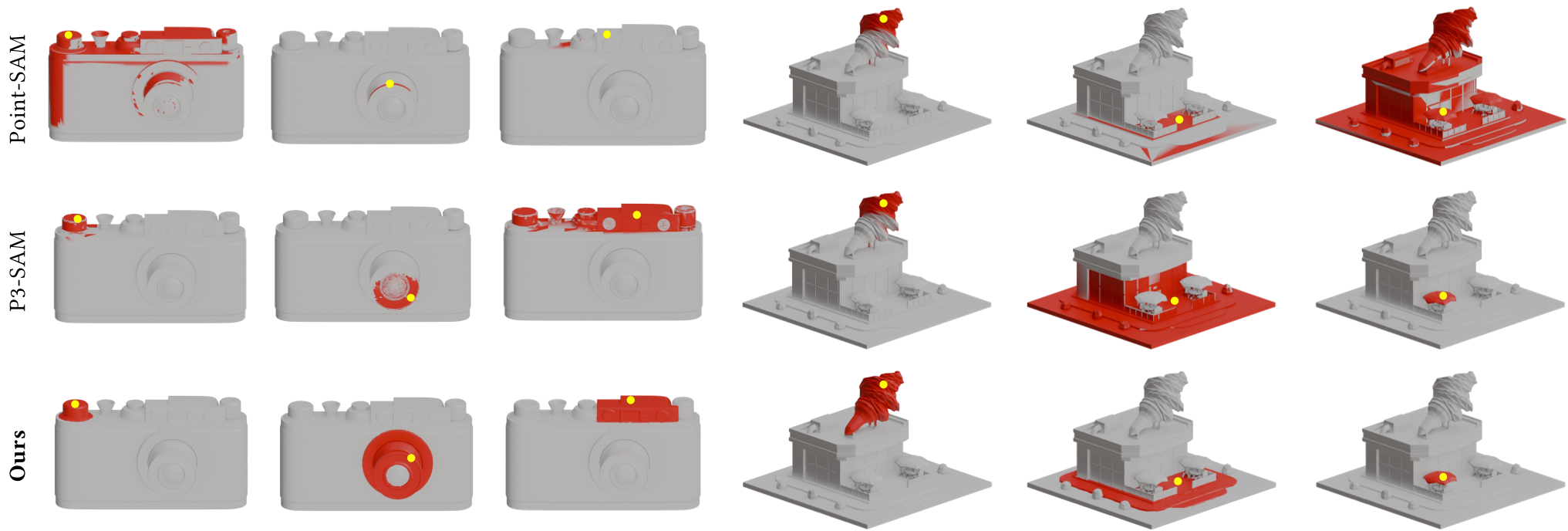 图 2:SegviGen 与 Point-SAM, P3-SAM 的定性对比。注意红色的分割区域,SegviGen 的边界对齐更加精准,尤其是复杂零件的转折处。
图 2:SegviGen 与 Point-SAM, P3-SAM 的定性对比。注意红色的分割区域,SegviGen 的边界对齐更加精准,尤其是复杂零件的转折处。
深度洞察:为什么 3D 生成先验这么灵?
传统的分割模型是“分类器”,它在学特征到标签的映射;而 SegviGen 借用的生成模型是“世界模型”。它通过海量的非监督 3D 资产学习了真实的拉普拉斯平滑、几何连续性和物理材质分布。
局限性分析: 尽管效果惊人,但 SegviGen 的推理依赖于流匹配的多步迭代(本文建议 12 步),在实时性要求极高的场景下,推理延迟(约 2.6 秒/物体)可能需要通过更高效的离散化方案或蒸馏技术来进一步缩减。
总结
SegviGen 的成功预示着 3D 领域的一个趋势:生成模型正在从“玩具”变为“工具”。当我们将生成先验注入感知任务,原本需要“大数据量、大算力”堆砌的高门槛任务,正变得触手可及。
 图 3:SegviGen 在下游 3D 编辑任务中的应用示例,精准的分割是高质量 3D 修改的前提。
图 3:SegviGen 在下游 3D 编辑任务中的应用示例,精准的分割是高质量 3D 修改的前提。