本文提出了 SelfTTS,这是一个基于 VITS 架构的端到端文本转语音(TTS)模型,专门用于跨说话人情感风格迁移。该模型通过显式解耦策略和自增强(Self-Augmentation)机制,无需预训练的外部编码器即可在保持目标说话人音色的同时,实现自然且高强度情感的生成。
TL;DR
在情感语音合成(Expressive TTS)领域,如何将 A 的情感“移植”到只有中性录音的 B 身上,一直是极具挑战的任务。SelfTTS 提出了一种无需外部预训练模型(如情感预测器或 speaker encoder)的自包含框架。通过多正类对比学习(MPCL)和基于余弦相似度的显式解耦,SelfTTS 成功解决了“说话人泄露”痛点,并在情感自然度(eMOS)上达到了 SOTA 水平。
痛点深挖:为什么你的风格迁移会“变声”?
传统的跨说话人风格迁移模型通常依赖一个 Reference Encoder 来提取风格嵌入(Style Embedding)。然而,由于训练数据中特定情感往往与特定说话人绑定,模型极易产生音色泄露(Speaker Leakage):当你想要迁移动作片式的愤怒情感时,合成出的语音往往既带有愤怒,也带有了那位愤怒配音员的音色。
现有的解决方法(如普通的对抗训练 GRL)往往在大规模、不平衡的数据集上表现乏力。如果模型不能在表征空间(Embedding Space)上真正实现情感与音色的“桥归桥,路归路”,这种泄露就无法避免。
核心机制:SelfTTS 的解耦三板斧
1. 多正类对比学习 (MPCL)
为了让情感和音色的表征更加清晰,作者引入了 MPCL 损失。与传统交叉熵(CE)不同,MPCL 强制要求相同标签的样本在向量空间中靠拢,不同标签的推开。这种归纳偏置(Inductive Bias)使得模型生成的 Style Space 具有极强的聚类性。
2. 显式嵌入解耦 (Explicit Embedding Disentanglement)
这是本文的精髓。作者不仅在隐含层 zp 使用了 GRL,还直接在情感嵌入 (e) 和 音色嵌入 (g) 之间应用了基于余弦相似度的 GRL。
- 逻辑直觉:通过最小化 e 和 g 映射后的余弦相似度,强制模型在提取情感时“抹除”任何能识别出说话人身份的特征,反之亦然。
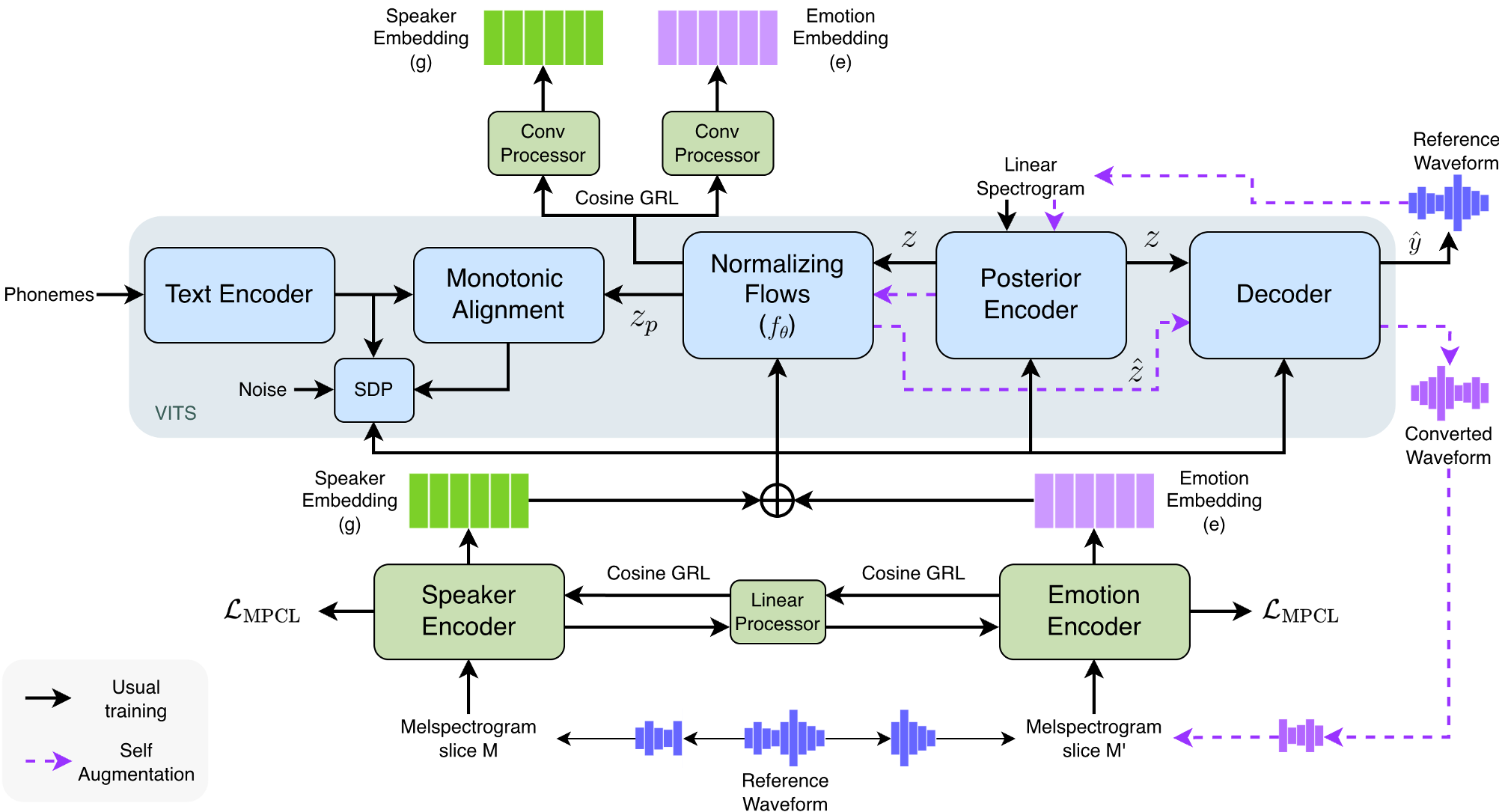 图 1:SelfTTS 架构。紫色虚线展示了利用自身 VC 能力进行自增强的流程。
图 1:SelfTTS 架构。紫色虚线展示了利用自身 VC 能力进行自增强的流程。
3. 自增强 (Self-Augmentation)
模型在训练后期,利用其自身的语音转换(Voice Conversion)能力生成“伪数据”。例如,用 A 的音色合成 B 的情感语音,再将这些合成样本喂回模型训练。这不仅增加了训练的多样性,还进一步强化了模型对不同音色下情感表现的理解。
实验战绩:全方位领跑
在 ESD 数据集上的对比实验显示,SelfTTS 在核心指标 eMOS(情感感知评分)上表现惊人。
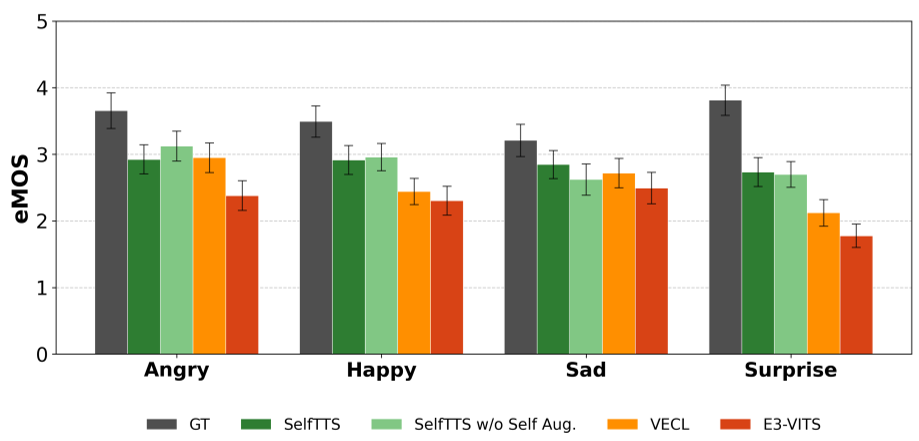 图 2:eMOS 评分对比。SelfTTS 在“惊讶”和“快乐”等高强度情感上的表现远超 VECL 等基线。
图 2:eMOS 评分对比。SelfTTS 在“惊讶”和“快乐”等高强度情感上的表现远超 VECL 等基线。
关键发现:
- 聚类效果显著:UMAP 可视化(图 3)显示,SelfTTS 生成的情感簇(Cluster)极其紧凑且互不重叠,而基线模型如 E3-VITS 则呈现混乱交织状。
- 消融验证:如果不使用自增强(w/o Self-Aug.),模型的自然度会显著下降(nMOS 从 2.74 掉到 2.22),证明了“自产自销”数据的精炼价值。
 图 3:SelfTTS 的情感表征空间。清晰的聚类是稳定风格迁移的基石。
图 3:SelfTTS 的情感表征空间。清晰的聚类是稳定风格迁移的基石。
深度洞察与总结
SelfTTS 的成功在于其对“表征质量”的执着追求。它通过 MPCL 解决“聚得拢”的问题,通过余弦 GRL 解决“分得开”的问题,最后通过自增强解决“说得像”的问题。
局限性与挑战: 虽然在同语料库内表现完美,但模型在**跨语料库(Cross-corpus)**场景下(如从 ESD 迁移到 LJSpeech)的单词错误率(WER)仍然偏高。这说明声学环境(录音设备、底噪)的干扰仍然是情感解耦中一个未被完全攻克的变量。
未来启示: SelfTTS 证明了即使没有海量预训练模型,通过巧妙设计的损失函数和闭环自增强,也能在垂直领域(如特定情感 TTS)实现极高质量的生成效果。这对于追求模型小型化、私有化部署的企业具有重要的借鉴意义。