本文提出了 SG-VLA,一种专门为移动操作(Mobile Manipulation)设计的空间对齐愿景-语言-动作模型。通过引入多视图 RGB-D 输入和一组辅助预测任务(Auxiliary Tasks),该模型在复杂的家庭重排任务中显著提升了空间推理与长程操作能力,在 ManiSkill-HAB 基准测试中将平均成功率从 60% 提升至 73%。
TL;DR
移动机器人不仅需要会“听”指令,更要能“看”懂空间。本文提出的 SG-VLA 通过强化多视图深度感知和引入 5 种辅助监督任务(如关节角、物体位姿预测),解决了传统 VLA 模型在家庭复杂场景下“视觉盲点多”和“控制精度低”的问题。在 1.3B 的轻量级参数下,其表现远超 7B 规模的 OpenVLA 变体。
痛点深挖:为什么 VLA 玩不转“移动操作”?
目前的 Vision-Language-Action (VLA) 模型在桌面上抓个方块已经很溜了,但一旦让它进厨房开冰箱、拿罐头,性能就会断崖式下跌。核心矛盾在于:
- 视野局限性:单视角 RGB 无法同时兼顾全身导航和局部精细抓取。
- 空间理解缺失:Transformer 擅长语义关联,但对物体的 3D 距离、机器人的关节构型(Kinematics)缺乏物理直觉。
- 监督信号薄弱:仅靠“指令->动作”的模仿学习,模型难以在海量 latent 表征中习得对操作至关重要的几何特征。
方法论详解:空间对齐(Spatial Grounding)
SG-VLA 并不是盲目堆砌参数,而是通过精准的“外科手术”式改进提升了模型的空间感。
1. 多模态感知的“全家桶”
研究团队为模型配备了头载相机(Head Camera)和手部相机(Hand Camera),并强制引入了经过归一化处理的 Depth(深度) 信息。实验证明,深度信息的加入比单纯增加图像分辨率更能提升放置(Place)任务的准确度。
2. 五大辅助解码器(Auxiliary Decoders)
为了让中间层表征(Latent Features)更具“物理意义”,SG-VLA 在训练阶段并行预测以下任务:
- Global Pose:机器人在地图上的 (x, y) 坐标。
- Joint Pose (qpos):12 维机器人关节角(采用 Transformer 架构预测)。
- Grasp Success:二分类判断是否成功抓取。
- Object Pose & Mask:目标的 7D 位姿及像素级分割掩码。
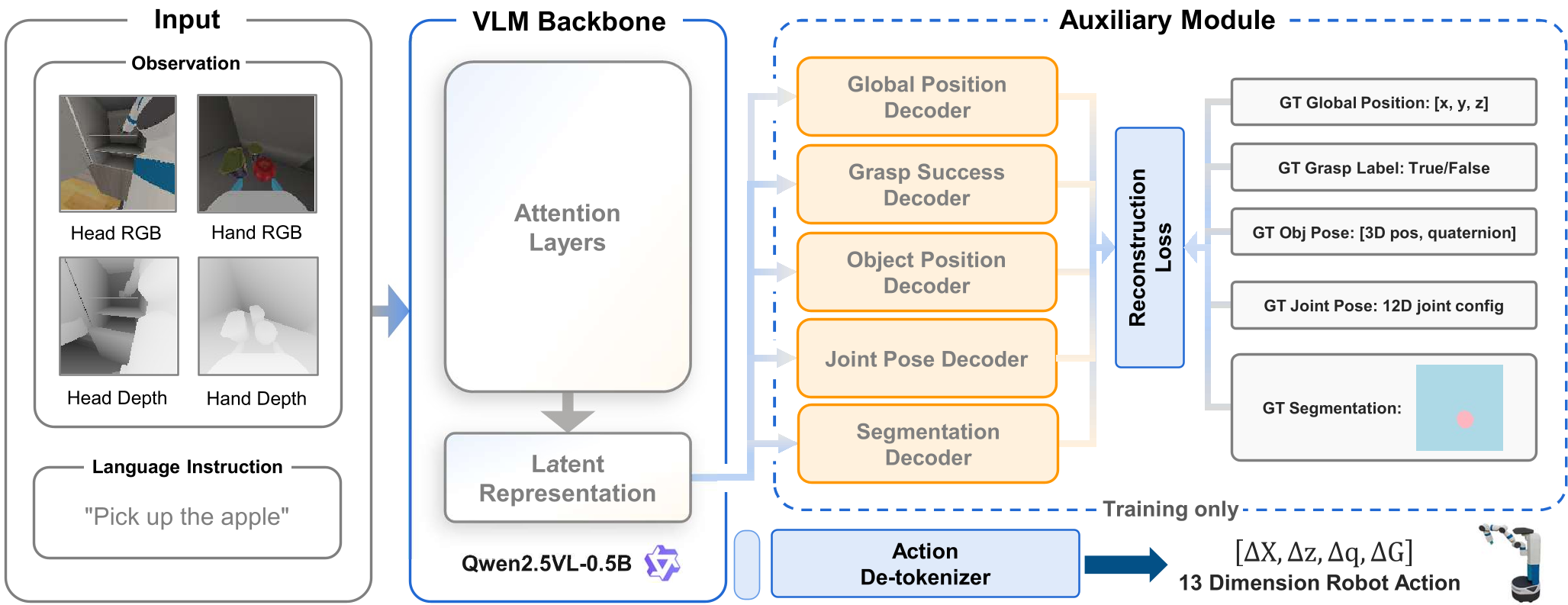
3. 两阶段渐进式训练(Two-Stage Progressive Training)
直接训练辅助任务会导致梯度噪声严重干扰预训练 VLM 的表征。作者机智地采用了:
- 第一阶段(适配期):冻结 VLM,让解码器去“对齐”现有的视觉特征。
- 第二阶段(炼金期):打通梯度,全链路联合微调,让辅助任务反哺视觉表征。
实验与结果:全线飘红的战绩
在大型家务基准 ManiSkill-HAB 上,SG-VLA 展示了统治级的表现。
- 感知增益:将 OpenVLA 升级为多视图+深度输入后,平均成功率从 0.04 直接飙升至 0.32。
- 对齐增益:加入辅助任务后,成功率进一步推高至 0.73。
- 任务分析:预测关节角(qpos)对抽屉开关任务提升最大;预测分割掩码(Mask)则让放置任务的成功率在 TidyHouse 场景下翻了近一倍。
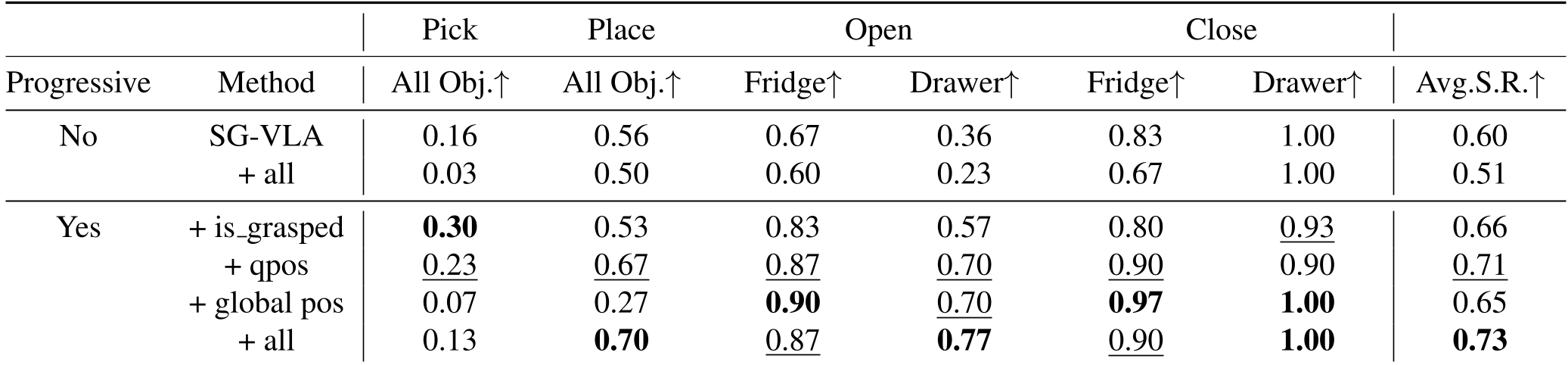
深度洞察:关于连续动作(Action Head)的思考
论文中一个有趣的细节是:引入 Flow Matching 连续动作专家后,Pick 任务(抓取)的成功率从 0.13 倍增至 0.27,但 Open 任务(开门/抽屉)反而下降了。 这揭示了一个真理: 抓取需要精细的连续控制(Fine-grained),而移动、推门等大动作可能更依赖于离散的语义决策(Decision-making)。这为未来“混合动作空间”的研究指明了方向。
总结与局限
SG-VLA 证明了空间对齐是 VLA 走向通用的必经之路。尽管它在模拟器中表现惊人,但现实世界中的深度传感器噪声、实时计算延迟仍是挑战。不过,这种“语义+几何辅助”的思路,无疑是目前 scaling 机器人大模型最具性价比的路线之一。
本文由资深学术技术主编重构。原文参考:Tu et al. "SG-VLA: Learning Spatially-Grounded Vision-Language-Action Models for Mobile Manipulation"