本文提出了 Simulation Distillation (SimDist),一种基于世界模型(World Model)的机器人 sim-to-real 迁移框架。该方法通过在仿真阶段蒸馏结构化先验,并在真实世界中仅对潜在动力学(Latent Dynamics)进行监督微调,实现了在复杂操纵与四足足式任务中的快速适配,取得了显著超越 SOTA 方法的性能。
TL;DR
传统的机器人 Sim-to-Real 迁移往往在“适配”阶段面临训练不稳定、表现崩溃等顽疾。本文提出的 SimDist (Simulation Distillation) 框架通过将决策分解为“不变的全局结构”(奖励、价值、表示)和“可变的局部动力学”,使得真实世界中的适配从恐怖的强化学习降维打击成了简单的监督动力学微调。仅需 15 分钟实操,即可让四足机器人学会走上特氟龙打滑斜坡。
核心速览:世界模型是最佳的抽象层
在机器人领域,研究者们一直试图从仿真(Simulation)中获益。然而,仿真环境的物理参数与现实总有落差。本文的核心论点是:世界模型,而非端到端 Policy,才是 Sim-to-Real 迁移的最佳载体。
其逻辑在于:
- 全局结构不变性:无论是在仿真还是现实中,插销任务的“目标”、物体的“语义角色”以及“距离目标的远近”(价值函数)基本一致。
- 局部动力学差异性:接触力、摩擦系数、电机延迟在两界之间大相径庭。
SimDist 抓住这一点,让模型只学习它该学习的部分。
痛点深挖:为什么直接 Finetune Policy 总是失败?
现有的 Model-free RL(如 SAC, PPO)在适配时,需要从头开始进行复杂的探测和信用分配。但在真实机器人上,数据极度匮乏且带有噪声,这种“牵一发而动全身”的梯度更新极易导致模型忘掉在仿真中学到的宝贵物理常识,甚至导致硬件损坏。
关键方法论:SimDist 的三步走策略
1. 仿真中的“结构蒸馏”
作者并不只是收集专家轨迹(Expert trajectories),而是故意在仿真中加入动作预测偏差和子优策略。这一步至关重要,它让世界模型见识过“失败”和“恢复”,从而学到一个鲁棒的潜在表示空间 以及覆盖面极广的价值函数 。
2. 模型架构设计
SimDist 采用了 Planning-Oriented 的架构,包含了 Transformer 驱动的潜在动力学(Latent Dynamics)。其特点是:
- Chunked Prediction:一次前向传播预测未来 个状态,极大提升了 MPPI 采样规划的效率。
- Seq-to-Seq Return Modeling:不再独立看每个时间步,而是用 Transformer 评估整条轨迹的期望。
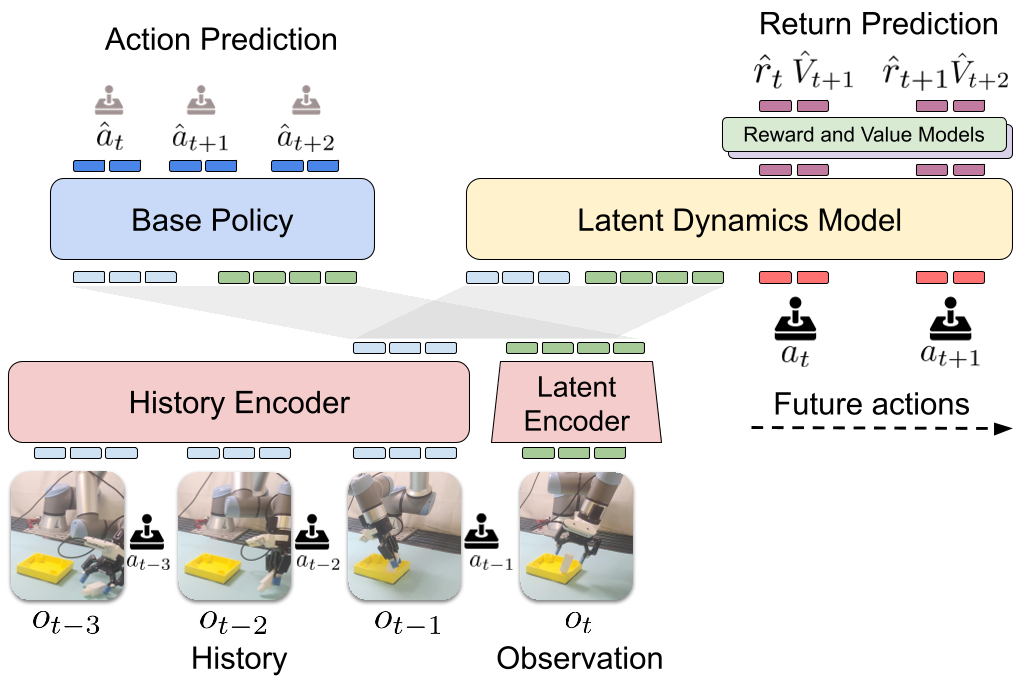 图 1: SimDist 整体架构。注意到部署阶段(Step 4b),大部分模块被冻结,仅 Dynamics 模块可更。
图 1: SimDist 整体架构。注意到部署阶段(Step 4b),大部分模块被冻结,仅 Dynamics 模块可更。
3. 部署:监督式系统辨识
在真实世界部署时,SimDist 冻结了状态编码器 、奖励模型 和价值估计 。机器人通过 MPPI 在线规划动作。当它遇到未曾预料的物理现象(如打滑)时,它只更新动力学模型 ,使其预测更贴近真实观测。这本质上是把 RL 问题降级为监督学习(Supervised Learning)。
实验战绩:让四足机器人“预知”风险
在最具代表性的 Slippery Slope 实验中,预训练模型原本预测机器人会稳定接触,导致实操时在特氟龙表面滑倒。但通过几轮 Finetune,动力学模型成功学到了“这里会滑”的物理属性。
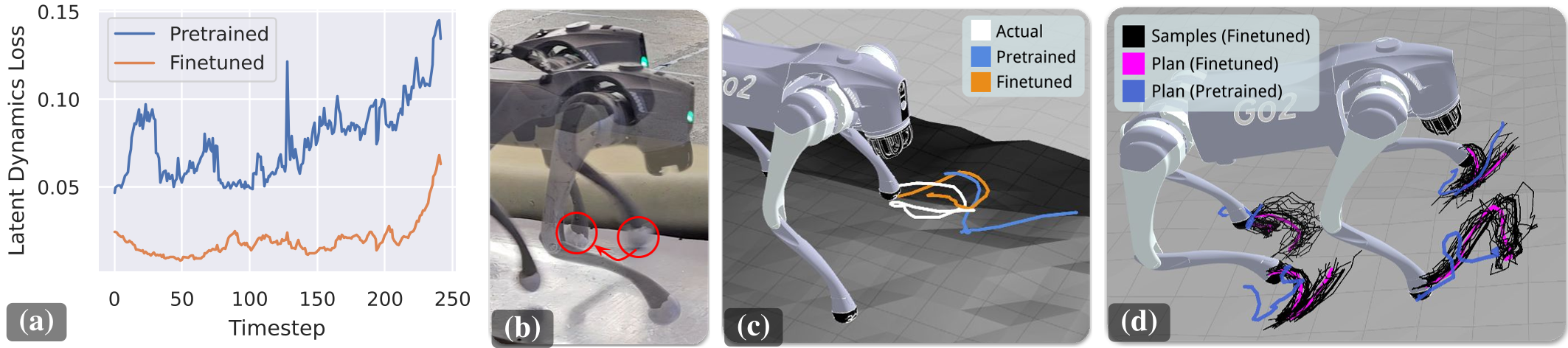 图 2: 在微调前(Pretrained),模型无法预测滑行轨迹;微调后,模型能精准预测足尖位移,从而使规划器选出更稳健的步伐。
图 2: 在微调前(Pretrained),模型无法预测滑行轨迹;微调后,模型能精准预测足尖位移,从而使规划器选出更稳健的步伐。
在操作任务中,SimDist 表现同样出色。在 Wide-range 的 Peg Insertion(广域插销)任务中,其成功率是 Diffusion Policy 的两倍以上。
| 任务项 | SimDist (Ours) | RLPD (Baseline) | Diffusion Policy | | :--- | :---: | :---: | :---: | | Peg Insertion | 0.90 | 0.32 | 0.50 | | 四足前进进度 | 1.82m | 0.35m | - |
深度洞察与总结
SimDist 的成功揭示了机器人研究的一个重要趋势:不要试图在一个统一的黑盒里学所有东西。
核心价值 (Takeaway):
- 冷启动与稳定性:由于奖励和价值模型是零样本迁移(Zero-shot Transfer),机器人从第一秒起就展现出了“有目的”的行为,避免了 RL 常见的无序探索。
- 纯净的微调目标:只修补动力学漏洞,不破坏任务认知。
局限性与展望:
目前该工作仍依赖于高质量的仿真器和定义明确的奖励函数。未来如果能将 SimDist 与大规模视频预训练(Video World Models)结合,通过真实世界的无监督数据进一步增强全局结构先验,机器人将拥有在野外环境(In the wild)下秒速适配的恐怖能力。