The paper introduces SlotVTG, an object-centric adapter framework for Generalizable Video Temporal Grounding (VTG) using Multimodal Large Language Models (MLLMs). It utilizes a lightweight Slot Adapter and a Slot Alignment Loss to decompose video tokens into entity-level representations, achieving state-of-the-art Out-of-Domain (OOD) generalization.
TL;DR
Current Multimodal Large Language Models (MLLMs) are surprisingly bad at generalizing in Video Temporal Grounding (VTG). They tend to "cheat" by memorizing dataset biases rather than looking at the video. SlotVTG fixes this by introducing a lightweight Slot Adapter that forces the model to perceive videos as a collection of semantic objects (slots), rather than an undifferentiated blob of pixels. This simple change leads to massive improvements in zero-shot transfer across different video domains.
The "Shortcut" Problem: Why MLLMs Fail at Generalization
In the world of Video Temporal Grounding, the goal is simple: find the start and end times of an event described in text. However, the authors discovered a disturbing trend: fine-tuned MLLMs often ignore the actual visual content on Out-of-Domain (OOD) data.
Through a "Noise Perturbation" experiment, they found that if you blur out the ground-truth segment in a video, the model's accuracy on OOD data barely changes compared to blurring a random part of the video. This proves the model isn't truly "grounding" the query—it's guessing based on statistical shortcuts learned during training.
Methodology: Perception through Decomposition
To force the MLLM to be "honest," the authors introduce SlotVTG. The architecture relies on two key components:
1. The Slot Adapter
Instead of passing visual tokens directly into the LLM, they pass them through a bottleneck. Inside this bottleneck, a set of learnable Slots compete via Slot Attention to explain the visual features. This forces the model to disentangle the scene into discrete entities (e.g., "person," "cup," "background").
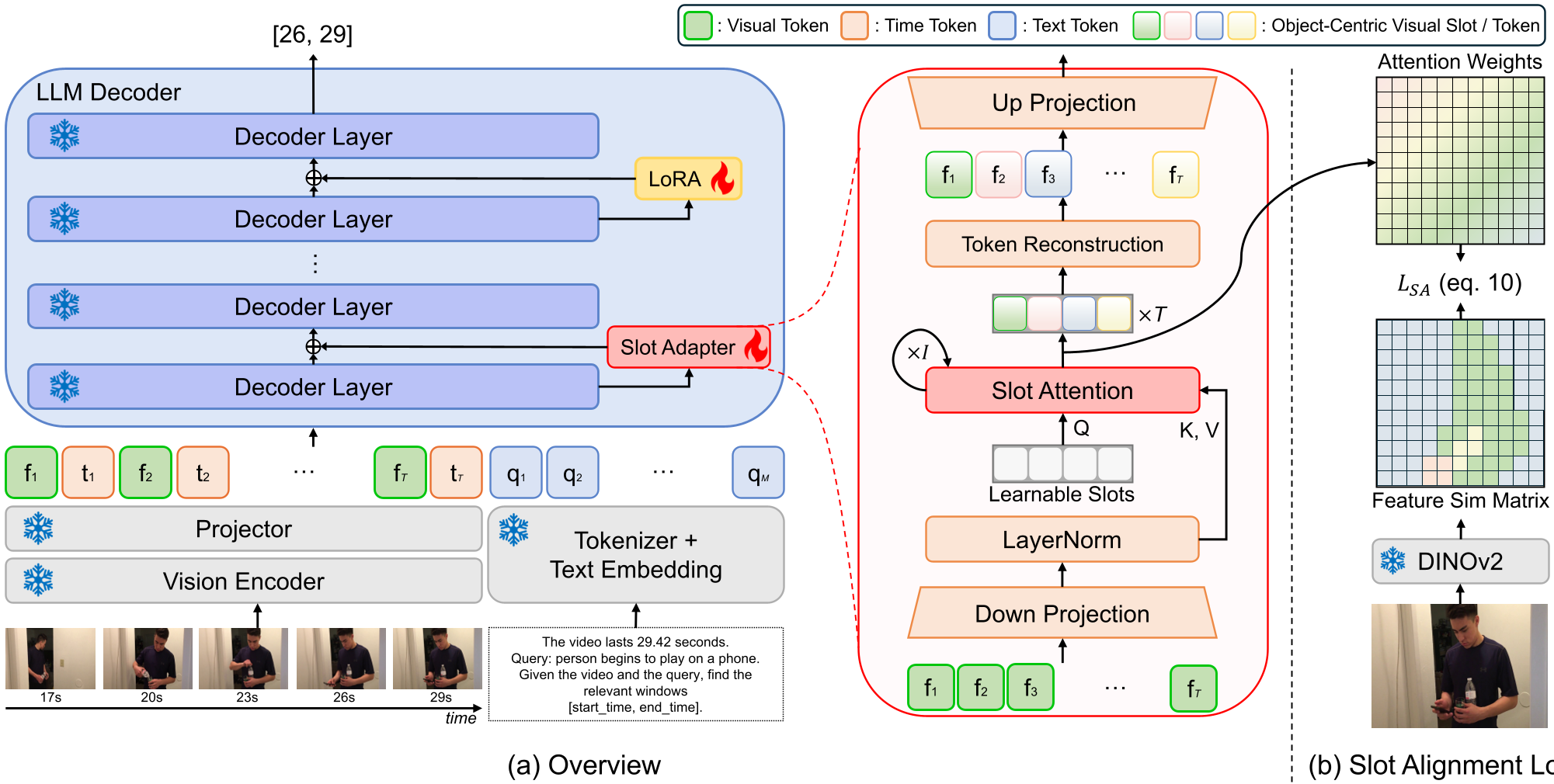
2. Slot Alignment Loss (SA Loss)
How do we ensure these slots actually correspond to objects? The authors use DINOv2—a self-supervised model known for its emergent object-aware features. By aligning the slot attention maps with DINOv2's feature similarity, the model is guided to group semantically coherent pixels into the same slot without needing explicit object bounding boxes.
Experimental Results: Generalization is Real
The results across three major benchmarks (Charades-STA, QVHighlights, ActivityNet) show that SlotVTG consistently outperforms standard fine-tuning (Chrono-Qwen) in OOD settings.
| Source Target | Method | R1@0.5 (OOD) | Improvement | | :--- | :--- | :--- | :--- | | Charades QVH | Baseline | 43.6 | - | | Charades QVH | SlotVTG | 47.9 | +4.3% | | Charades ANet | Baseline | 26.3 | - | | Charades ANet | SlotVTG | 28.7 | +2.4% |
These gains are achieved using only ~7.6M to 23.3M trainable parameters, representing a tiny fraction of the base 3B or 7B models.
 Visualizing slots: The model successfully segments "people" and "objects" even in unseen video environments, providing a domain-invariant "vocabulary" for the LLM.
Visualizing slots: The model successfully segments "people" and "objects" even in unseen video environments, providing a domain-invariant "vocabulary" for the LLM.
Critical Insight & Conclusion
The core takeaway is that Object-Centricity is a robust prior for generalization. By compressing high-dimensional visual tokens into a few semantic slots, we create a bottleneck that filters out domain-specific "noise" (like lighting or resolution) and keeps the "entities" that are essential for reasoning.
While SlotVTG shows impressive OOD gains, the challenge remains for very complex scenes where more than 4-8 slots might be needed. Future work will likely explore dynamic slot allocation to handle increasingly cluttered video environments.
For practitioners looking to improve MLLM robustness, SlotVTG provides a clear blueprint: Don't just fine-tune—decompose.