本文提出了 Tempo,一个针对长视频理解的高效查询感知压缩框架。该方法结合小型视觉语言模型(SVLM)作为局部压缩器,通过自适应令牌分配(ATA)技术,在 6B 参数规模下实现了对小时级视频的精准捕捉,并在 LVBench 等长视频榜单上超越了 GPT-4o 和 Gemini 1.5 Pro。
TL;DR
Meta 与 KAUST 的研究者们推出了 Tempo,一个能将小时级视频进行“意图对齐”压缩的高效框架。它通过一个小巧的 2B 视觉语言模型(SVLM)作为前置过滤器,仅保留对回答问题有用的画面细节。即使整体参数仅 6B,其在长视频理解能力(LVBench)上却大比分超越了拥有庞大窗口的商用闭源模型。
背景定位:这是针对 MLLM 长视频推理效率的一次精巧重构,属于通过“智能路由”解决计算瓶颈的 SOTA 级工作。
痛点深挖:为什么长视频总是“看了后面忘前面”?
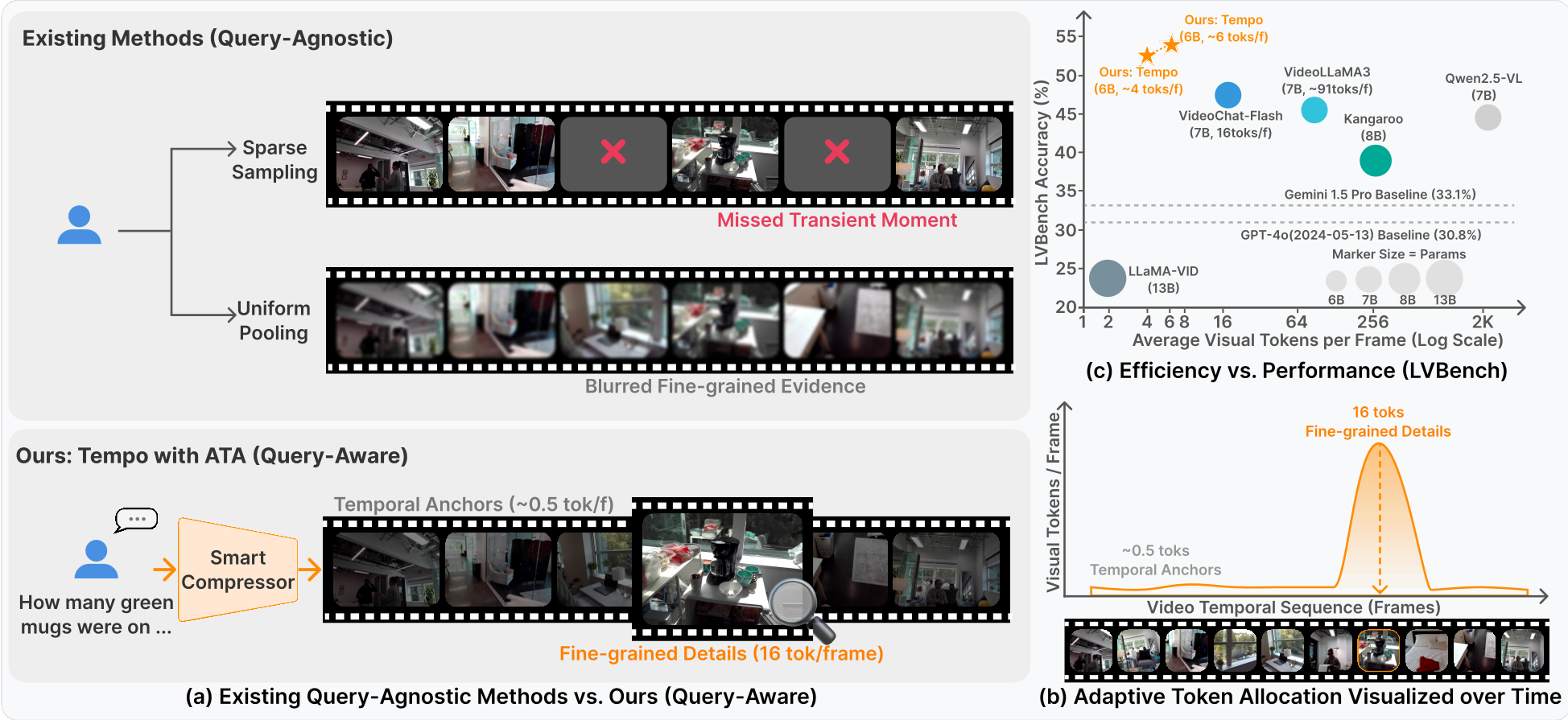
传统的多模态大模型(MLLM)处理长视频通常采用两种妥协方案:
- 稀疏采样:每隔几十秒抽一帧,但这很容易漏掉关键的转瞬即逝的动作。
- 均匀压缩:通过 Pooling 或合并 Token 减少数据量,但这是一种“盲目”的行为——模型在不知道用户想问什么的情况下,把精彩片段和枯燥背景一视同仁地模糊化了。
这导致了严重的 Lost-in-the-middle 现象:模型被数万个视觉 Token 淹没,真正支撑答案的那几帧证据被淹没在噪声中。
核心逻辑:把视频压缩变成“跨模态蒸馏”
Tempo 的核心直觉是:如果我先知道你要问什么,我就能决定每一帧该留多少信息。
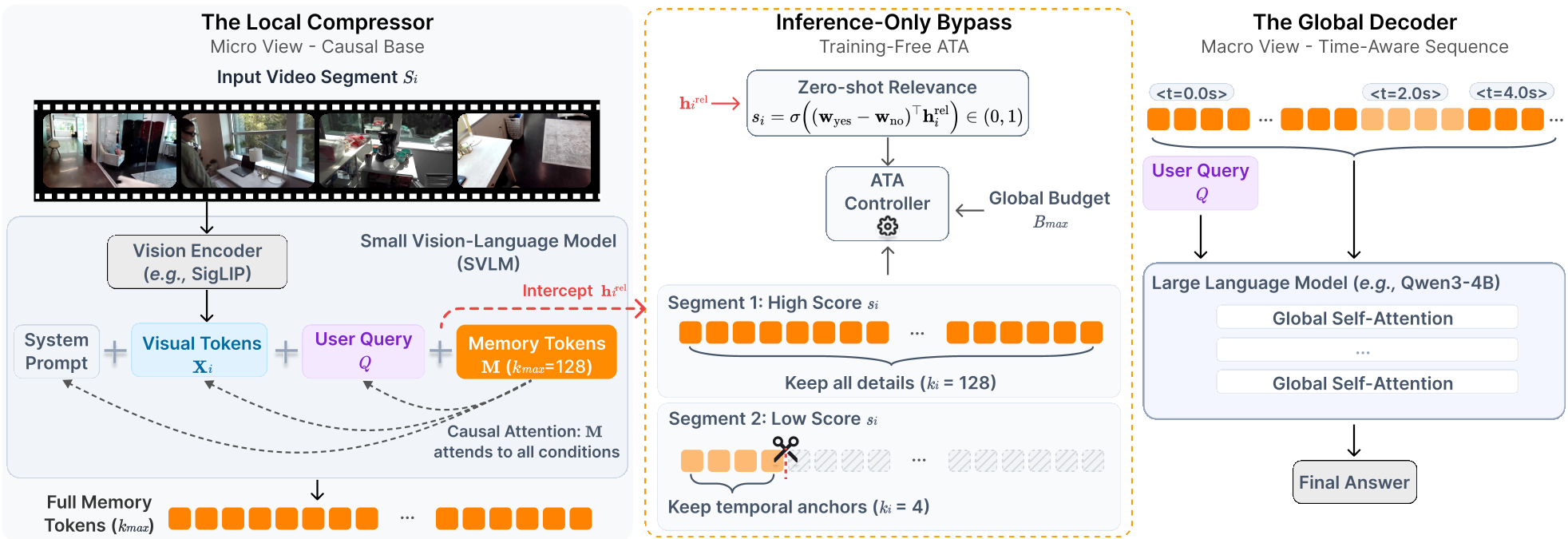
1. 局部压缩器 (Local Compressor)
Tempo 使用一个轻量级的 SVLM(如 Qwen3-VL-2B)。它的输入包括:系统指令 + 原始视觉 Token + 用户查询 (Query)。通过 Causal Attention(因果注意力),模型会将所有的上下文信息蒸馏到少量的响应令牌(Memory Tokens)中。
2. ATA:自适应令牌分配
这是本文最精妙的设计。作者发现 SVLM 天生具备 Zero-shot Relevance Prior(零样本相关性先验)。
- 动态路由:模型在处理每个片段时,会预判“这一段跟问题相关吗?”,并给出一个相关性分数。
- 节奏控制:ATA 根据分数分配带宽。相关片段分配高带宽(最高 16 tokens/frame),无关背景则只保留最低限度的“时间锚点”(如 0.5 tokens/frame),以保证时间线的连续性。
- 物理直觉:由于因果注意力的特性,最重要的信息总是倾向于聚集在序列的最前端。因此,Tempo 采用 O(1) 的头部截断(Head Truncation) 来实现精确压缩,完全没有额外的计算开销。
实验战绩:“少即是多”的胜利
在 LVBench(平均时长超过 1 小时)的测试中,Tempo 表演了惊人的“逆袭”:
- 性能提升:在严格的 8K Token 限制下,Tempo 得分 52.3,远超专业长视频模型 VideoChat-Flash (48.2) 和 GPT-4o (30.8)。
- 效率奇迹:即便给 Tempo 12K 的预算,它在实际处理中往往只用到更少的 Token,因为它只在“有必要”的地方浪费空间。
消融实验揭秘:作者发现,强制实施 4K 预算的表现有时竟然优于 8K。这验证了在长视频任务中,主动去噪(Filtering)比被动接受(Scaling)更重要。
深度洞察与展望
Tempo 的成功证明了:真正的长视频理解不在于无限膨胀的上下文窗口,而在于意图驱动的效率。
局限性与思考
- 推理延迟:虽然压缩减少了 LLM 的压力,但 SVLM 的预处理仍是一笔开销。
- 多轮对话:目前的压缩是针对单次查询的。如果用户改了问题,可能需要重新进行局部压缩(虽然作者在讨论中提出了分层按需蒸馏的构想)。
总结
Tempo 展示了 SLM(小模型)与 LLM(大模型)协同的一种理想范式:让 SLM 处理高密度、低语义的原始数据流,而让 LLM 专注于高层级的逻辑推理。这种“意图驱动”的资源分配策略,是多模态模型走向实用化的必经之路。