This paper introduces a mechanistic interpretability pipeline for Vision-Language-Action (VLA) models using Sparse Autoencoders (SAEs) to decompose complex neural activations into human-interpretable features. By applying SAEs to models like π0.5 and OpenVLA, the authors identify specific latent directions that function as "motion primitives" or "semantic markers," achieving the first causal evidence of steerable, generalizable features in robotic transformer policies.
Executive Summary
TL;DR: Researchers from Stanford have applied Sparse Autoencoders (SAEs) to Vision-Language-Action (VLA) models to "peek under the hood" of robotic brains. They discovered that while most VLAs are massive "memorization machines," they do contain hidden, steerable levers—specific neural directions—that correspond to general concepts like "grasping" or "transporting." By nudging these "General Features," they can causally control a robot's behavior across different tasks.
Background: This work sits at the intersection of Mechanistic Interpretability and Robot Learning. It moves the field beyond treating VLAs as "black boxes" that either work or fail, providing a diagnostic tool to measure true generalization versus rote memorization.
The Problem: The "Brittle" Robot Paradox
Current VLA models (like RT-2 or OpenVLA) are impressive but fragile. A model might have a 90% success rate in a lab but drop to 0% if you change the color of a bowl. The community suspected Supervised Fine-Tuning (SFT) on small datasets was causing "trajectory-level memorization," but they lacked the tools to prove it—until now.
Methodology: Decomposing the Residual Stream
The authors use SAEs to project the dense, "messy" activations of the VLA's transformer layers into a high-dimensional sparse space.
The SAE Pipeline
- Activation Collection: They hook into the "residual stream" (the highway of data in a transformer).
- Sparse Dictionary Learning: Use a TopK SAE to find a set of basis vectors.
- Classification: They developed a logistic regression classifier based on Episode Coverage (how many different tasks a feature appears in) and Onset Count (how "bursty" the feature is).
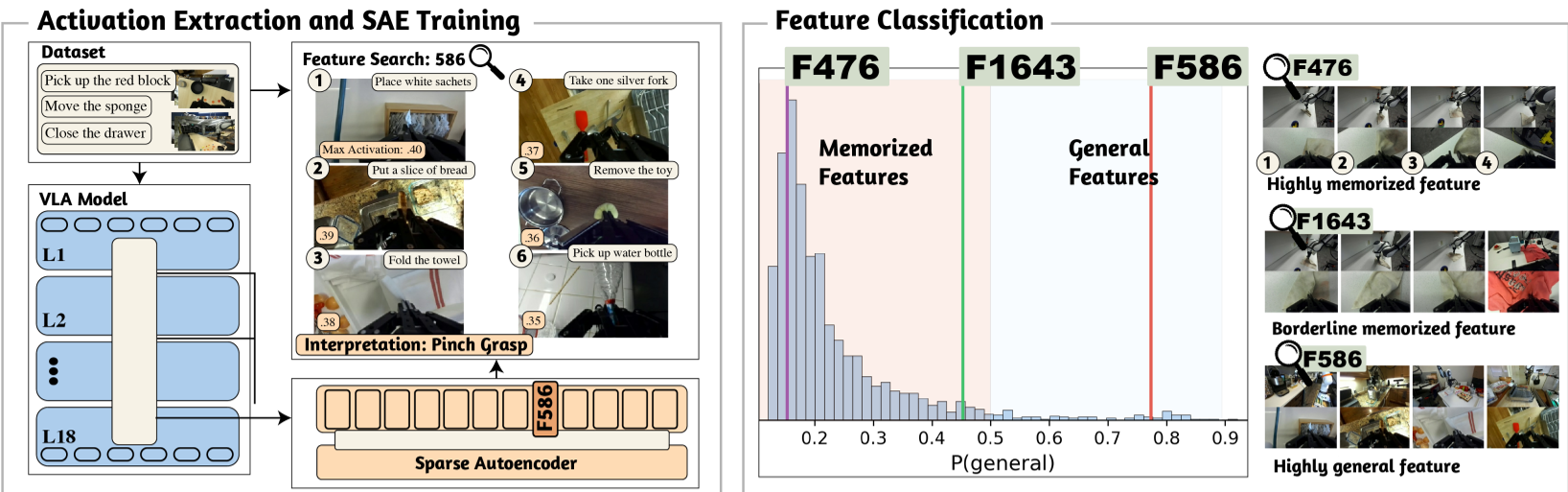
Key Insights: General vs. Memorized Features
The authors categorized features into two camps:
- Memorized Features: High "Relative Run Length" (they stay on the whole time) and low "Episode Coverage." These represent the model's "script" for a specific scene.
- General Features: High "Onset Count" (they trigger at specific events) and high "Episode Coverage."
Visual Evidence of General Features
In the image below, you can see features like F158 (Sub-task checkpoint) activating across wildly different DROID episodes, from picking up bottles to moving plates. This is the "Generalization" we've been looking for.

Experiments: Steering the Robot
To prove these features weren't just artifacts, the researchers performed Feature Steering. By adding a "Pre-grasp alignment" vector (F128) back into the model during inference, they could force the robot to stop and hover over objects instead of completing a grasp. This confirms the feature has a causal influence on the robot's physical actions.
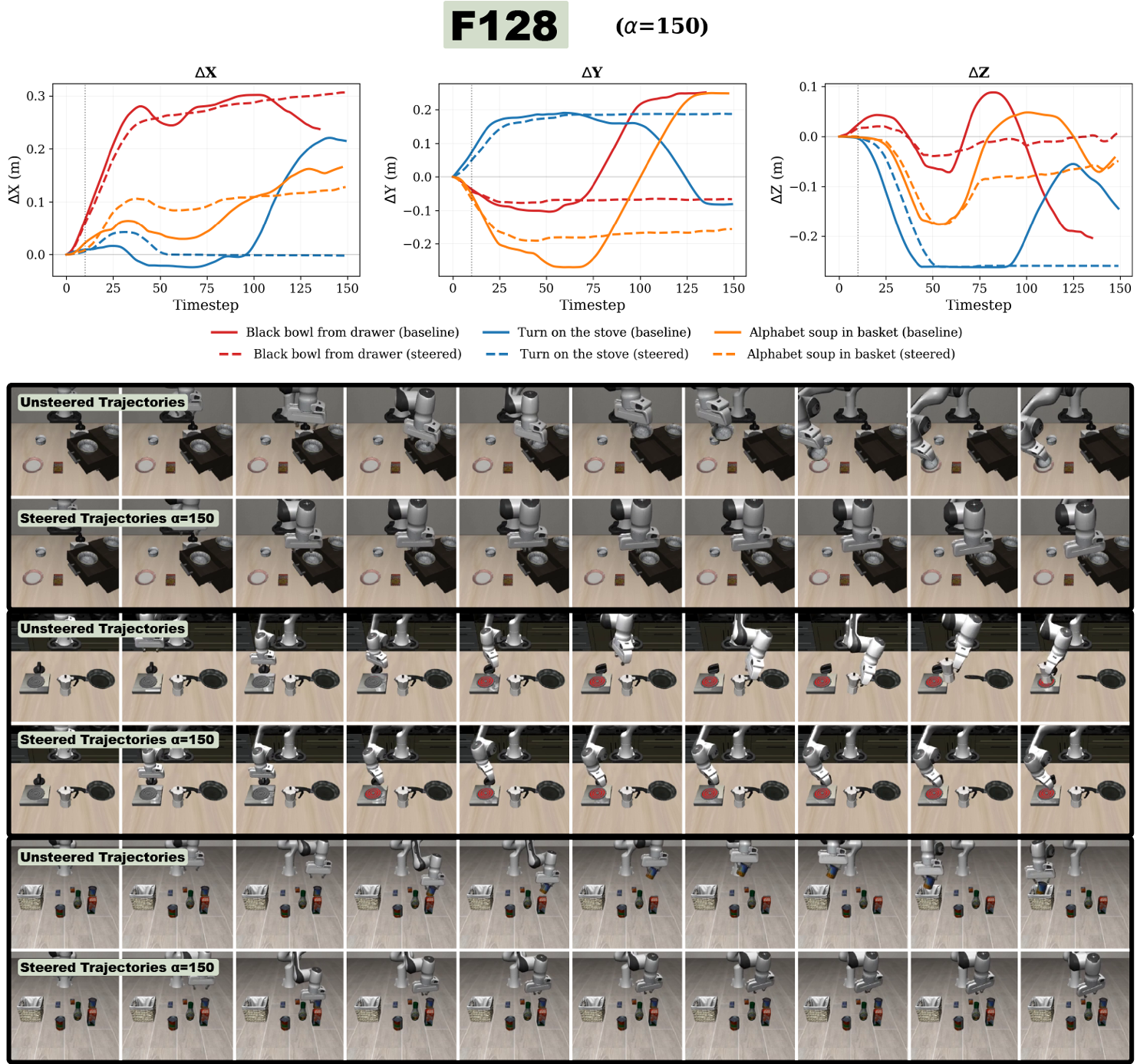
Critical Analysis & Conclusion
Takeaway: The study proves that VLAs can learn transferable skills, but current training methods (SFT) disproportionately favor memorization. Using Knowledge Insulation (KI) and larger datasets like DROID significantly improves the "General Feature" ratio.
Limitations:
- Steerability Gaps: Not all interpretable features are steerable, likely due to the complex, non-linear nature of the "Action Expert" (Diffusion/Flow heads).
- Scaling: Most features are still memorized (~90%+). We are far from a truly world-model-based generalist robot.
Future Work: This research opens the door to Interpretability-Guided Training, where models are penalized for developing "Memorization Features" and rewarded for "General Features," potentially solving the brittleness of robotic AI forever.