本文提出了一种用于定位和验证多模态大模型(VLM)内部“视觉思维环路”的因果流水线。通过在 Qwen3-VL-8B 等模型的中层(Layer 21)训练 TopK 稀疏自编码器(SAE),作者发现了具有空间接地性的任务选择性特征,并揭示了特征组合时的非模态干扰现象。
TL;DR
视觉语言模型(VLM)在推理时内部到底发生了什么?本文通过**稀疏自编码器(SAE)**作为“因果显微镜”,在 Qwen3-VL 中定位到了关键的“视觉思维环路”。研究发现:虽然我们可以精准找到控制特定任务的“原子特征”,但这些特征像磁铁同极一样相互排斥——当你试图同时增强多个相关特征时,模型反而会陷入“幻觉”并崩溃。
背景定位
该工作是 VLM **机械可解释性(Mechanistic Interpretability)**领域的突破性进展。它不仅从稠密激活中剥离出了稀疏的语义特征,更通过严谨的因果干预实验,证伪了长期以来在模型转向(Steering)技术中存在的“线性模态假设”。
痛点与动机:为什么模型控制总是失效?
目前的 VLM 干预技术(如 Steering)通常假设:如果我们找到代表“计数”和“空间关系”的方向,将它们相加就能提升综合推理能力。
但作者发现,这往往导致输出漂移(Output Drift)。原因在于:
- 感知与语义的纠缠:早期层(如 Layer 10)充斥着高频视觉噪声,干预此处的特征会像在泥潭里推车。
- 非正交的基向量:VLM 的特征空间并非直角坐标系,不同的语义方向之间存在显著的几何拮抗(Antagonism)。
核心方法论:寻找思维的“原子”
1. 定位语义瓶颈
作者首先利用**线性探测(Linear Probing)**在解码器的 36 层中扫射。实验发现,Layer 21 是一个神奇的“鞍点”:在此处,任务类型的可分性达到 99.37%,标志着视觉像素完成了向抽象语义的华丽转变。
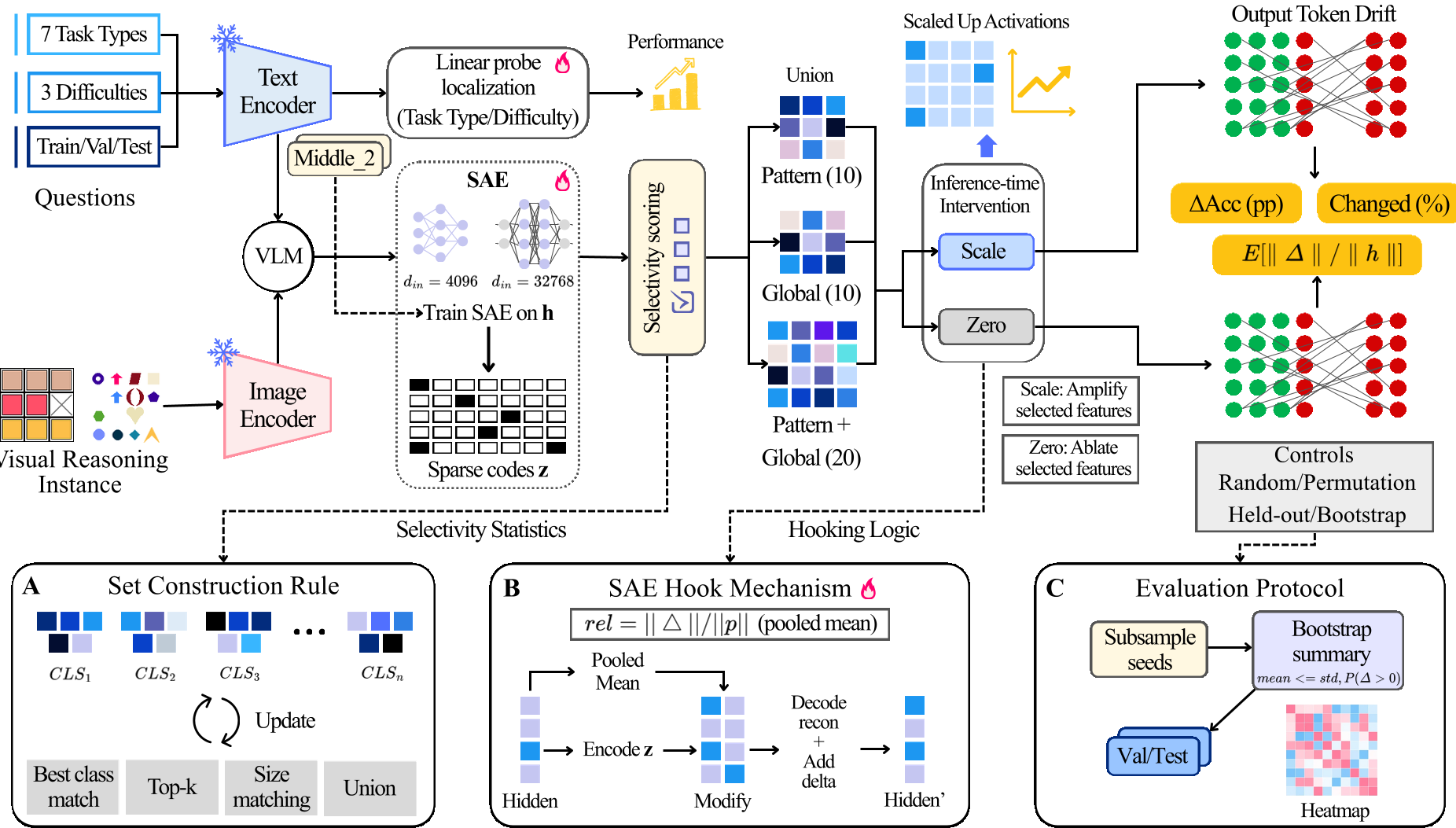
2. TopK-SAE 稀疏分解
在 Layer 21,作者训练了一个 expansion factor 为 8 的 TopK-SAE,将 4096 维的稠密空间映射到 32768 维的稀疏特征空间。
- 空间接地性验证:通过反向投影发现,尽管特征是从全局池化信号中提取的,但特征激活点在图像空间中精准锁定了任务目标(如特定的色块或形状)。
实验战绩:组合悖论的发现
作者对比了**单一特征集(Pattern Set)干预与并集特征集(Union Set)**干预的效果。
- 惊人的必要性:消融(零干预)选定的极少数特征,模型的预测翻转率高达 57%-77%,证明这些特征是推理的“承重墙”。
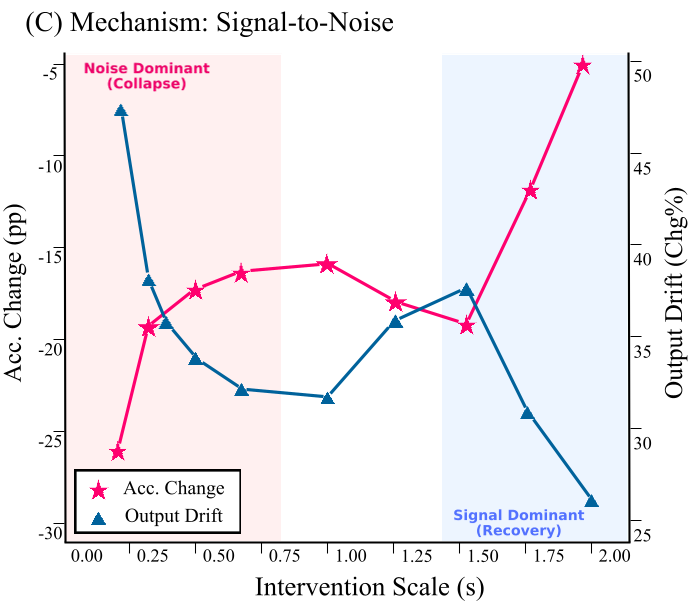
- 组合崩溃:在 NLVR2 和 CLEVR 等基准上,单独增强 Pattern 集合能带来精度提升;但一旦加入 Global 集合形成 Union 组合,精度立刻崩盘(如下图粉色区域所示)。
深度洞察:噪声放大定律
为什么 1+1 < 1?作者提出了**几何拮抗(Geometric Antagonism)**解释: 由于特征方向 $\Delta_P$ 和 $\Delta_G$ 的余弦相似度为负(约 -0.33),它们的线性叠加会导致语义信号发生“矢量抵消”。当有效信号 $\parallel\delta\parallel \rightarrow 0$ 时,Transformer 的 LayerNorm 组件会像扩音器一样放大背景噪声 $\epsilon$。
$$ \mathrm{NSR}_{out} \propto \frac{1}{\parallel\delta\parallel} $$
这种噪声放大使得模型丢失了“视觉锚点”,注意力机制变得发散(熵增),最终导致模型退化到仅依赖语言先验进行胡乱生成的“幻觉模式”。
总结与未来启示
- 层级敏感性:Layer 21 是 VLM 的“隐式视觉思维链”,它是干预的最佳窗口。
- 拒绝简单加法:未来的模型转向必须是感知流形的(Manifold-Aware)。作者建议采用**正交化信号投影(OSP)**来规避拮抗。
- 局限性:目前的 Union 定义仅限于线性加和。复杂的逻辑运算(如 AND/OR)在 VLM 潜空间中如何映射仍是未解之谜。
正如作者所言,控制 VLM 推理的关键不再是寻找更多的特征,而是掌握这些特征之间复杂的几何协议。