本文提出了 SparseCam4D,一个利用视频生成模型实现稀疏视角(仅 2-3 个摄像头)下高质量 4D 动态场景重建的框架。核心贡献是引入了时空畸变场(STDF),解决了生成观测值在空间与时间上的不一致性问题,在多个基准数据集上达到了 SOTA 性能。
TL;DR
传统的动态 4D 场景重建(如拍摄一段可以自由改变视角的视频)往往需要密不透风的摄像头阵列。SparseCam4D 挑战了这一极限:仅需 2-3 个稀疏布置的摄像头,通过引入**视频生成模型(VDM)产生辅助观测,并配套创新的时空畸变场(STDF)**解决生成内容的闪烁与不一致问题,实现了高保真、可自由漫游的 4D 重建。
痛点深挖:生成模型的“想象力”与“不协调性”
在摄像头极少的情况下,4D 重建是一个病态问题(Ill-posed),因为大部分视角的动态信息是缺失的。
- 几何正则化的局限:前人尝试用深度估计来补足,但在视角剧烈偏移时渲染质量会迅速下降。
- 生成模型的双刃剑:虽然视频扩散模型(如 ViewCrafter)可以“脑补”出缺失视角的影像,但生成的每一帧之间存在微小的空间错位和时间闪烁。如果把这些影像直接喂给重建算法,结果只会得到一团浆糊。
核心机制:时空畸变场 (STDF)
SparseCam4D 的天才之处在于:它并不强求生成模型产出完美的数据,而是接受不完美,并用一个专门的“场”去修正它。
1. 九平面表征 (Ennea-plane)
作者将 (x, y, z, t, s) 五维空间(空间+时间+位姿索引)分解为 9 个二维特征平面。这种高度分解的架构允许模型精确捕捉生成影像在特定时间点或特定视角下的微小形变。
2. 畸变解耦 (Disentanglement)
对于每一组生成的影像,STDF 会预测其 Gaussian 特性的偏移量(位置 $\Delta \mu$、旋转 $\Delta q$、缩放 $\Delta s$)。
- 训练时:利用生成的影像加上畸变修正后的 Gaussians 进行渲染。
- 推理时:直接丢弃 STDF,只保留最纯净、一致的“名义”4D Gaussians,从而实现实时渲染且无额外开销。
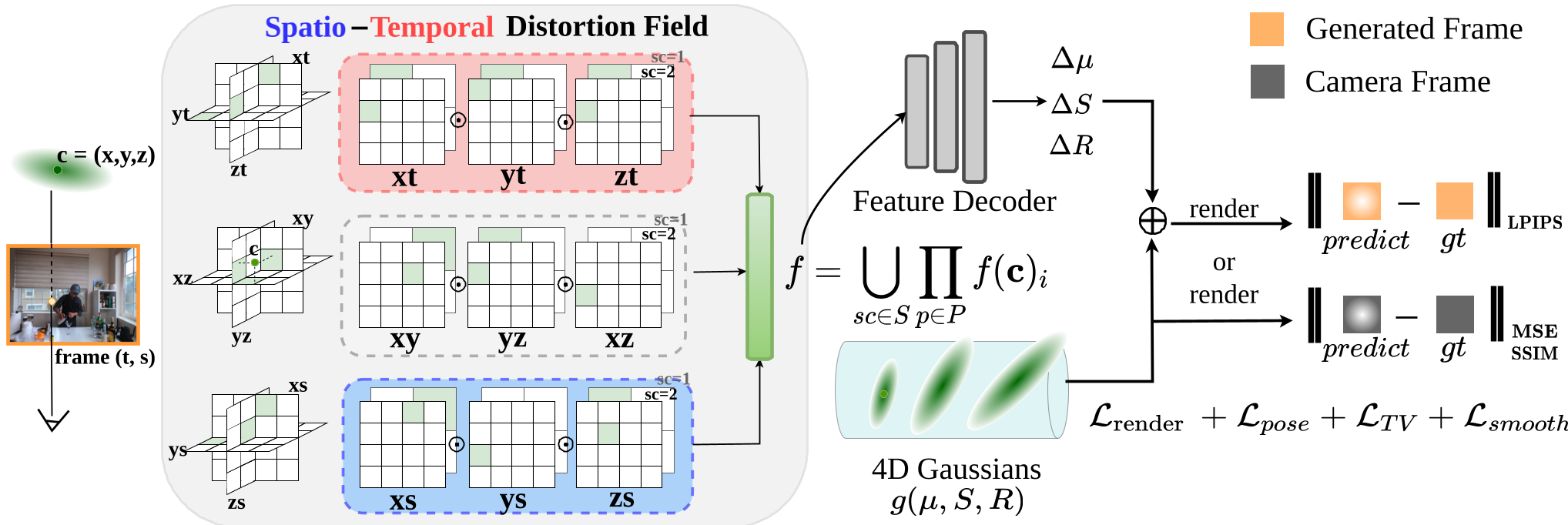 图 1: SparseCam4D 整体管线:通过辅助视角生成与 STDF 修正实现一致性重建
图 1: SparseCam4D 整体管线:通过辅助视角生成与 STDF 修正实现一致性重建
实验结果:以少胜多的胜利
SparseCam4D 在三大主流数据集上进行了测试,展示了在稀疏输入下的统治力:
- 画质跃升:在多项指标(PSNR, SSIM, LPIPS)上均显著超越了包括 MonoFusion 和 4DGS 在内的强力基线。
- 细节保留:即便视角增加到 9 个,SparseCam4D 依然能比 baseline 提供更锐利的纹理和更稳定的动态轨迹。
 图 2: 定性对比:SparseCam4D 在处理复杂动作时避免了基线方法的几何破碎和模糊现象
图 2: 定性对比:SparseCam4D 在处理复杂动作时避免了基线方法的几何破碎和模糊现象
深度洞察:为什么 STDF 有效?
通过消融实验可以发现,如果不加 STDF(即直接用生成图训练),PSNR 会下降约 2.5dB。有趣的是,作者通过可视化 STDF 的热力图发现,畸变场主要作用于人脸、玻璃瓶等细节丰富或光影复杂的区域。这证明了扩散模型在处理精细结构时更容易产生时空漂移,而 STDF 成功充当了“稳定器”。
总结与思考
SparseCam4D 不仅仅是一个算法的改进,它代表了一种趋势:将判别式重建与生成式 AI 深度耦合。它不再试图从虚无中提取几何,而是利用生成模型的广泛先验,辅以严谨的物理/几何修正场。
局限性:目前的重建质量高度依赖底层生成模型的质量。如果 VDM 产生了严重的幻觉(如人体结构崩坏),STDF 也难以回天。未来的研究可能会向“生成-重建”闭环迭代的方向演进。
主编评论:本文为解决稀疏视角下的 4D 重建提供了一个极具优雅的数学框架。通过 STDF 这一轻量级插件,它巧妙地在生成模态和几何一致性之间搭建了桥梁,是 3D/4D 内容创作民主化的又一里程碑。