本文提出了针对 Transformer 前馈网络(FFN)的非结构化稀疏优化方案,核心贡献是 TwELL 存储格式和一系列自定义 CUDA 内核。该方法在微弱 L1 正则化下实现了超 99% 的激活稀疏度,并在 H100 GPU 上将 2B 参数模型的推理与训练吞吐量分别提升了 20.5% 和 21.9%。
TL;DR
尽管 LLM 的前馈网络(FFN)存在天然的激活稀疏性,但由于硬件效率低下,这一特性一直难以转化为实际的提速。Sakana AI 与 NVIDIA 合作推出的这项研究,通过一种全新的 TwELL (Tile-wise ELLPACK) 格式和高效 CUDA Kernels,成功打破了这一僵局。该方案在几乎不损失模型性能的前提下,实现了超过 20% 的运行提速和 25% 的显存节省。
背景:被浪费的“稀疏红利”
在当前的 Transformer 架构中,FFN 层贡献了约 2/3 的参数量和 80% 的 FLOPs。大量研究表明,在使用 ReLU 激活时,对于特定的 Token,FFN 中仅有极小比例(常低于 5%)的神经元被激活。
然而,学术界长期面临一个**“稀疏悖论”**:虽然理论计算量下降了,但在 GPU 上跑稀疏算子往往比稠密算子还要慢。原因在于非结构化稀疏会导致内存访问不连续,且管理稀疏索引的开销极大。
核心创新:TwELL 格式与算子融合
为了解决这一痛点,作者提出了 TwELL (Tile-wise ELLPACK) 存储格式。
1. 突破同步瓶颈
传统的 ELL 格式要求对全行进行扫描和对齐,这与现代 GPU 算子基于 2D Tiles 的并行逻辑冲突,导致无法进行算子融合(Kernel Fusion)。TwELL 改为在局部 Tile(如 128x128)内进行 ELL 编码。
- 直觉:在计算 的同时,直接在寄存器中完成稀疏化并写入内存,消除了额外的内存读取。
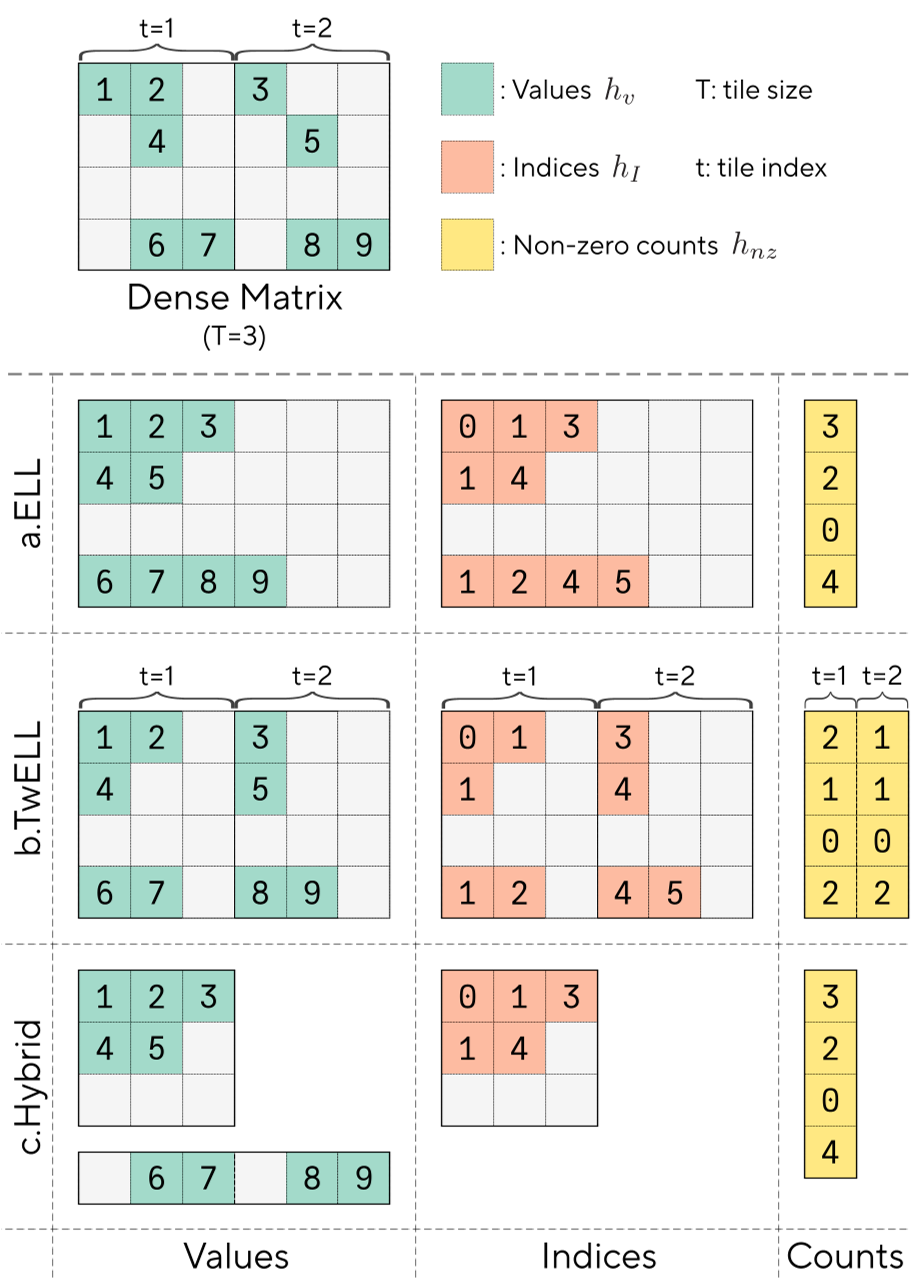 图 1: 推理阶段的管线融合方案,展示了从稠密输入到 TwELL 稀疏存储的生成过程。
图 1: 推理阶段的管线融合方案,展示了从稠密输入到 TwELL 稀疏存储的生成过程。
2. 训练阶段的混合格式 (Hybrid Format)
训练时的稀疏性由于不稳定性更难处理。作者引入了 Hybrid 存储:
- Sparse 部分:处理大部分符合稀疏规律的行,使用精简的 ELL 存储。
- Dense 备份:处理少数激活比例过高的“溢出行”。 这种设计保证了即使在训练早期稀疏性不明显时,系统也不会崩溃或显著变慢。
实验结果:规模越大,收益越高
作者在 0.5B 到 2B 参数规模的模型上进行了验证。
1. 性能对比
实验发现,模型规模越大,稀疏化的潜力越高。2B 模型的推理速度提升了 20.5%,能源消耗降低了 17%。
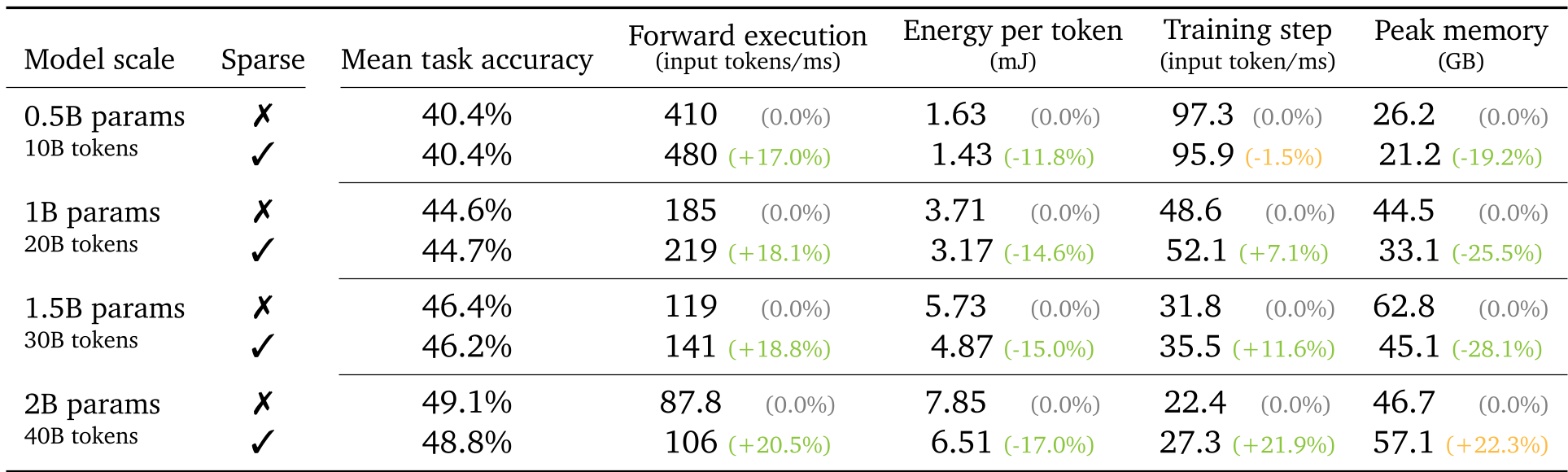 表 1: 不同规模模型的性能表现,可见稀疏模型(✓)在任务精度几乎不变的情况下,大幅提升了吞吐量。
表 1: 不同规模模型的性能表现,可见稀疏模型(✓)在任务精度几乎不变的情况下,大幅提升了吞吐量。
2. 激活深度分析
研究揭示了 LLM 内部的有趣特征:模型中间层的稀疏度最低(激活最频繁),这印证了中间层承载了主要的逻辑推理与知识检索。同时,对于“ predictable”的 Token(如 URL 后缀),模型几乎不怎么“动脑子”(高度稀疏);而对于信息量大的专有名词,激活度显著提升。
深度洞察:为什么这很重要?
- 硬件友好性:该工作证明了如果不考虑硬件的 Tiling 机制,单纯追求数学上的稀疏是徒劳的。TwELL 的成功在于它将稀疏格式与 NVIDIA 的 Tensor Core 处理单元对齐。
- 死神经元 (Dead Neurons) 挑战:虽然 L1 正则化效果显著,但也导致约 30% 的神经元永久失活。作者提出的“定向重新初始化(Targeted Reinit)”策略为未来更深度的稀疏化训练指明了方向。
- 异构平台的潜力:在 RTX 6000 等算力密度略低于 H100 的卡上,由于 SM 数量相对较多,稀疏算子的增益反而更大。这对降低 LLM 硬件准入门槛极具意义。
结论
Sakana AI 的这项工作标志着“稀疏性”正式从理论实验室走向了大规模生产环境。通过开源这些底层的 CUDA 内核,非结构化稀疏性有望成为 LLM 性能优化的标配轴线。
注:作者已在 GitHub (github.com/SakanaAI/sparser-faster-llms) 开源了所有代码与内核。