本文提出了 SpatialBoost,这是一个通过注入语言引导的 3D 空间知识来增强预训练视觉编码器(如 DINOv3, SigLIPv2)表示能力的框架。该方法在 ADE20K 语义分割任务上将 DINOv3 的表现从 55.9 提升至 59.7 mIoU,达到了 SOTA 水平。
TL;DR
视觉预训练模型(Vision Encoders)在 2D 语义理解上已经炉火纯青,但在面对 3D 空间关系(如深度预测、物体间距)时往往显得“扁平”。KAIST 和 NAVER 的研究者提出了 SpatialBoost:通过将 3D 几何信息转化为自然语言,并利用大语言模型(LLM)的推理能力,将这些“空间常识”反哺给视觉模型。该方法在不改变模型原有表征能力的前提下,显著提升了模型在深度估计、语义分割及视觉机器人控制任务中的表现。
核心速览:视觉模型的“深度”难题
尽管 DINOv2/v3 和 CLIP 已经是视觉表征的佼佼者,但它们本质上是在一张张“平面图片”上寻找模式。在自动驾驶或机器人抓取等场景中,这种缺乏 3D 空间感的 Inductive Bias 是致命的。
以往的改进思路通常是引入多视图(Multi-view)图像或点云数据进行重训,但这些数据极难大规模获取。SpatialBoost 的 Insight 在于:语言可以作为 3D 信息的“通用接口”。我们可以把几何关系描述给 LLM 听,再通过 LLM 的梯度让视觉模型学会这些几何特征。
方法论:空间链式思考 (Spatial CoT) 与双通道注意力
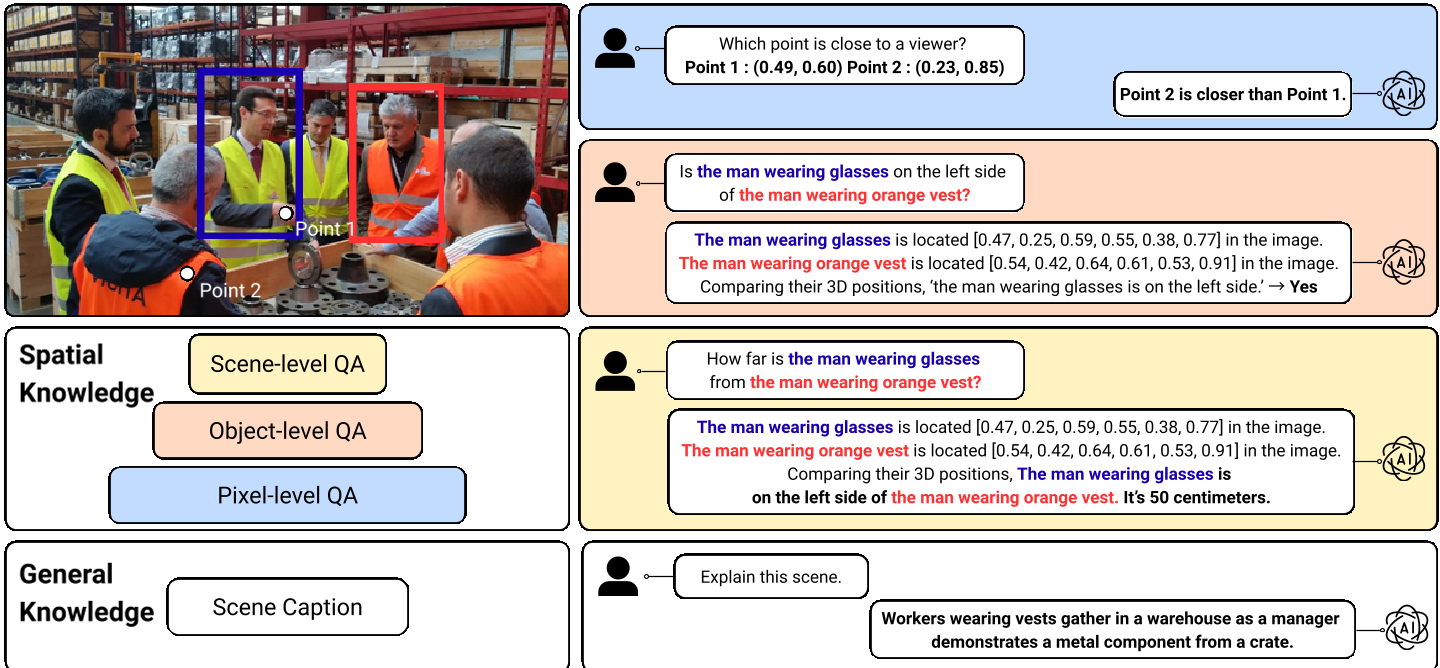
1. 空间推理分层 (Hierarchical Reasoning)
作者并没有简单地喂入“这张图里有桌子”,而是构建了一个三层的推理链条:
- Pixel-level (像素级):查询特定坐标的绝对/相对深度(如:点 A 的深度是多少?)。
- Object-level (物体级):基于像素信息,推理物体的 3D 边界框(Bounding Cube)和相对位置。
- Scene-level (场景级):推理物体间的实际物理距离。
这种从微观到宏观的 Multi-turn Chain-of-Thought 设计,能够强制模型层层递进地建立空间的拓扑结构。
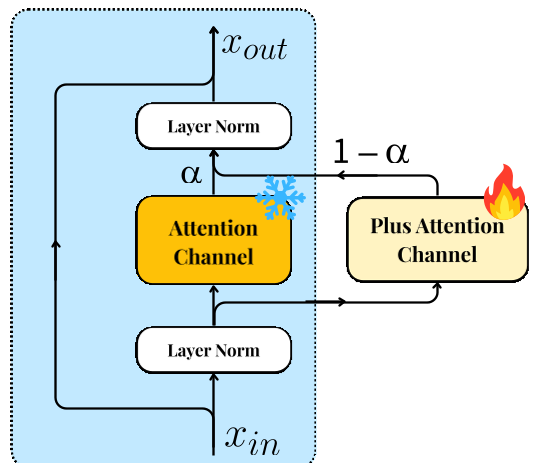
2. Dual-channel Attention:既要也要
全量微调会导致模型忘记原本强大的语义分类能力。SpatialBoost 引入了 Dual-channel Attention。
- 结构:在原本的 $Attn$ 旁边并排增加一个 $Attn^+$。
- 机制:通过一个可学习的参数 $\alpha$ 来控制新旧权重的融合: $$ ext{Attn}^{ ext{final}} = \alpha \cdot ext{Attn}(\mathbf{x}) + (1 - \alpha) \cdot ext{Attn}^{+}(\mathbf{x}) $$ 这样,原始预训练知识被“锁定”在原有通道,而新增的空间知识则在侧通道中灵活学习。
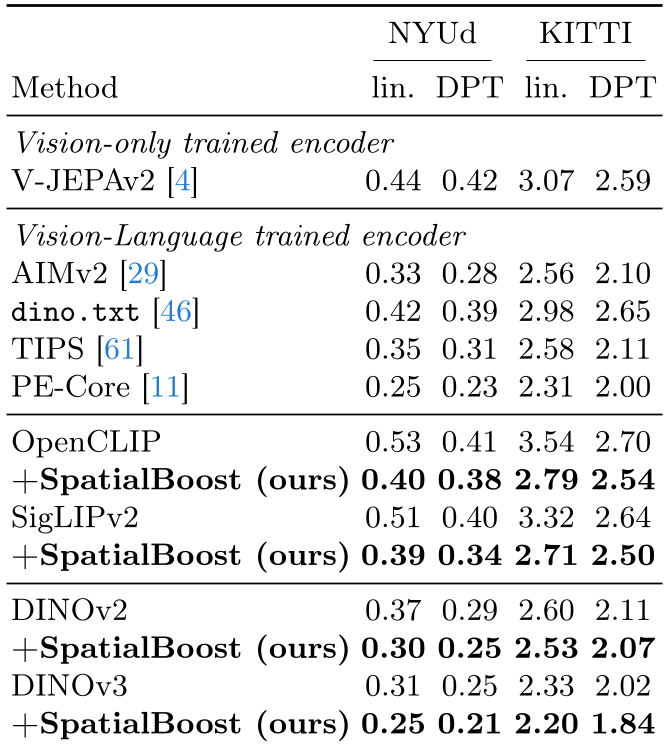
实验战绩:全线飘红
实验在 DINO 家族和 SigLIP 等多个强力 Backbones 上展开。
- 密集预测任务:在 ADE20K 语义分割上,DINOv3 + SpatialBoost 达到了 59.7 mIoU,比原始模型提升了 3.8%。
- 机器人学习:在机器人控制基准测试中,DINOv3 在 SpatialBoost 加持下,其操作任务的平均性能从 72.8 飙升至 80.8。
- 无副作用提升:令人惊讶的是,即使在 ImageNet 这种不需要 3D 信息的分类任务上,模型精度也提升了约 1.8%。这说明空间感增强后的特征更具判别性。
深度洞察与总结
SpatialBoost 的核心价值不仅在于提出了一个高效的 Finetuning 策略,更在于它揭示了 LLM 可以作为一种极其稠密的特征提取器 (Dense Feature Provider)。
局限性与挑战:
虽然实验表现优异,但该方法的训练数据生成依赖于已有的 3D 重建模型(如 VGGT)和深度模型(如 Depth-pro)。这意味着 SpatialBoost 的上限受限于这些“老师模型”的准确性。未来的研究可以探索如何完全脱离辅助视觉模型,通过真实物理反馈来纠偏空间推理。
结论:
对于那些希望在不牺牲通用分类能力的前提下,增强视觉模型空间感的开发者和研究者来说,SpatialBoost 提供了一个极其优雅且可扩展的方案。它证明了:听懂空间,才能看清世界。