daVinci-MagiHuman is an open-source audio-video generative foundation model featuring a 15B-parameter single-stream Transformer architecture. It achieves SOTA synchronized human-centric generation, supporting multilingual outputs and generating 5s of 256p video in 2 seconds on a single H100 GPU.
TL;DR
The landscape of generative AI is moving from silent frames to full-fledged "talking heads" with synchronized audio. daVinci-MagiHuman enters the open-source arena not with more complexity, but with less. By utilizing a 15B single-stream Transformer, it abandons the traditional multi-branch architecture in favor of a unified token sequence, achieving industry-leading synchronization, multilingual speech support, and high-speed H100 inference.
Problem & Motivation: The Complexity Trap
Most existing SOTA models (e.g., Ovi, LTX) treat audio and video as distinct entities that need to be "fused" later via cross-attention or specialized alignment modules. While intuitive, this creates an engineering bottleneck:
- Heterogeneous Computation: Different modalities require different kernels, making hardware utilization (FLOPS) sub-optimal.
- Alignment Drift: Temporal synchronization between lip movement and speech often breaks down in deep multi-stream networks.
The authors' insight is radical yet simple: "Everything is a Token." By treating video patches and audio frames as part of the same sequence, the Transformer’s self-attention mechanism naturally learns the cross-modal correlations without extra "glue" code.
Methodology: The Unified Backbone
The core of daVinci-MagiHuman is a 40-layer Transformer. However, it’s not a standard ViT.
1. The Sandwich Architecture
To balance modality-specific nuances with deep fusion, the model uses a symmetrical design:
- Outer Layers (1-4 & 37-40): Modality-specific projections and normalization.
- Inner Layers (5-36): Shared parameters for deep multimodal reasoning.
2. Timestep-Free Denoising & Per-Head Gating
The model departs from standard Diffusion Transformers (DiT) by removing explicit timestep embeddings. Instead, it infers the denoising state directly from the noisy latent—a trend gaining traction for its efficiency. Furthermore, it incorporates Per-Head Gating (an LLM technique) to stabilize gradients during the training of the massive 15B parameter stack.
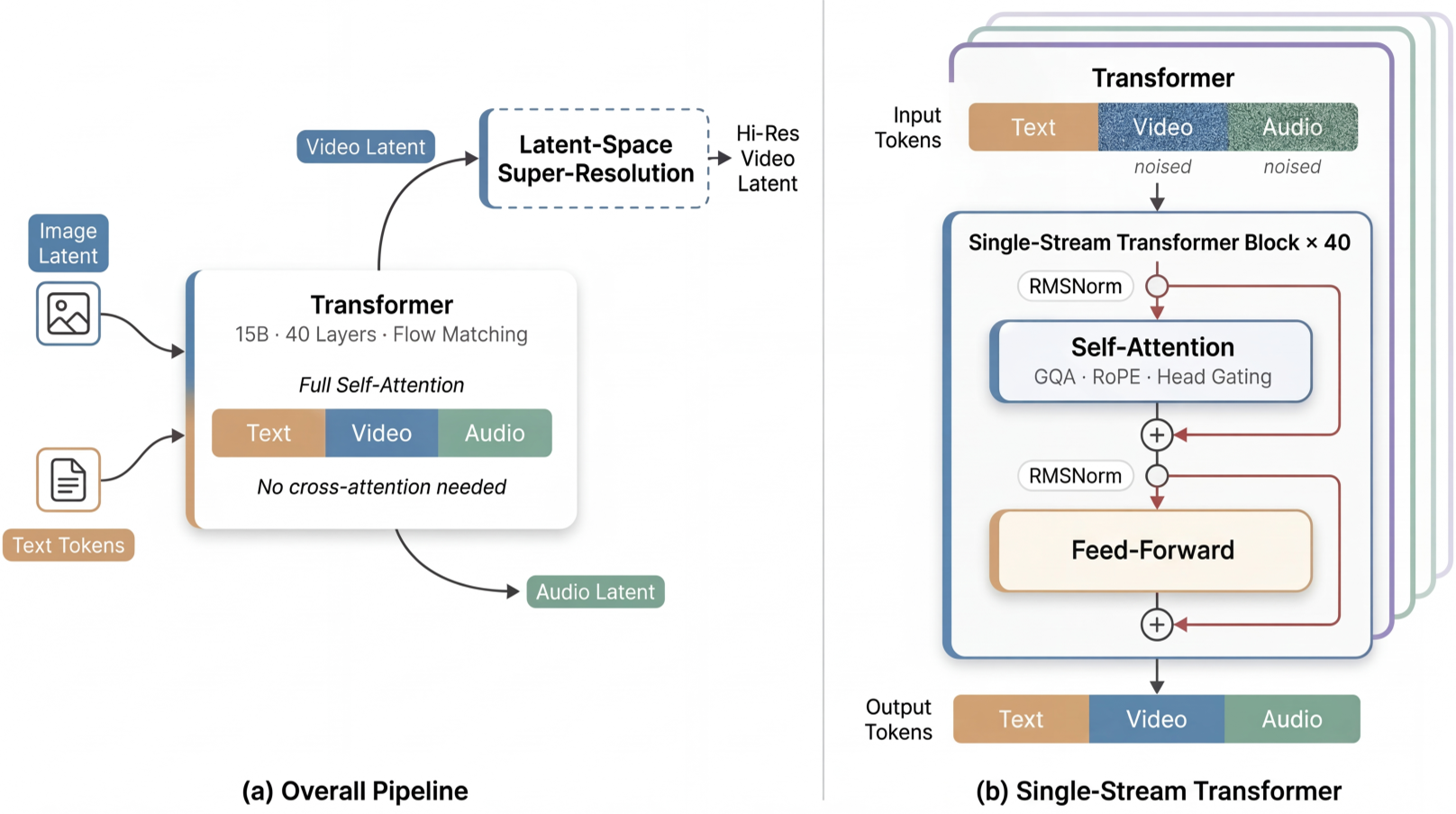 Figure: The Single-Stream Transformer processes text, video, and audio tokens in a unified representation space.
Figure: The Single-Stream Transformer processes text, video, and audio tokens in a unified representation space.
Experiments: Superior Quality and Speed
The model was benchmarked against leading open models like Ovi 1.1 and LTX 2.3.
1. Speech Intelligibility
Speech quality is where daVinci-MagiHuman truly shines. It achieved a Word Error Rate (WER) of 14.60%, significantly lower than LTX 2.3 (19.23%), indicating that the single-stream attention is exceptionally good at maintaining "lip-sync" and audio clarity.
2. Efficiency Breakdown
By combining DMD-2 distillation and a Turbo VAE, the model demonstrates remarkable latency. It can render 5 seconds of 1080p video in roughly 38 seconds—a feat that typically takes minutes for unoptimized diffusion models.
 Table: Comparison of visual and audio quality metrics across open-source baselines.
Table: Comparison of visual and audio quality metrics across open-source baselines.
Critical Insight & Conclusion
The success of daVinci-MagiHuman suggests that the "Simplicity Scale" is real. While the industry initially moved toward complex multi-pathway models to handle audio-video, the most robust solution appears to be a return to the unified Transformer. By scaling the backbone to 15B parameters and using a "Sandwich" layout, the model captures complex human dynamics—facial expressions, gestures, and multilingual speech—without specialized sub-networks.
Limitations: While strong in human-centric tasks, the paper notes that physical consistency still lags slightly behind LTX 2.3 in certain non-human scenarios. However, as an open-source foundation, its modularity (Base + SR + Turbo VAE) provides a powerful toolkit for the community to build upon.