SPPO (Sequence-Level PPO) is a reinforcement learning algorithm designed to align Large Language Models (LLMs) for complex reasoning tasks. It reformulates the reasoning process as a Sequence-Level Contextual Bandit problem, achieving state-of-the-art performance on mathematical benchmarks like AIME and MATH while providing a 5.9x training speedup over group-based methods like GRPO.
Executive Summary
TL;DR: SPPO (Sequence-Level PPO) is a breakthrough in aligning LLMs for long-horizon reasoning. By explicitly reformulating the training process as a Sequence-Level Contextual Bandit, it replaces the noisy token-level credit assignment of standard PPO with a unified sequence-level advantage. It matches the performance of heavyweights like GRPO while requiring only a single sample (N=1) per prompt, resulting in a 5.9x training speedup and significantly lower VRAM requirements.
In the current landscape of Reinforcement Learning with Verifiable Rewards (RLVR), SPPO serves as a "structural optimization," proving that for sparse-reward tasks, simplicity—treating the response as an atomic unit—beats complex, high-bias token-level modeling.
Problem & Motivation: The "Tail Effect" and The GRPO Bottleneck
Standard PPO relies on Generalized Advantage Estimation (GAE) to assign credit to specific tokens. In long Chain-of-Thought (CoT) tasks, the reward is sparse (only at the end). This forces the critic to propagate signals across thousands of tokens, often failing until the very end of the sequence.
The "Tail Effect"
The authors identify a critical failure mode: The Tail Effect. As shown in Figure 1, the critic value $V(s_t)$ only begins to discriminate between correct and incorrect paths at the very end of the reasoning chain. In between, the value signal is essentially noise, leading to vanishing or misleading advantages.
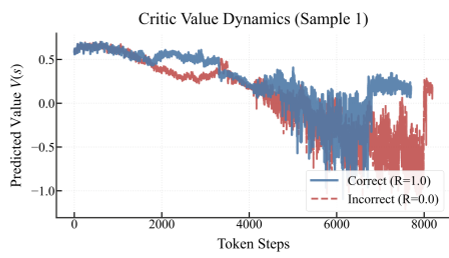
The Variance-Computation Trade-off
To solve this, methods like GRPO (Group Relative Policy Optimization) removed the critic and used group-based statistical baselines. However, to reduce the high variance of Monte Carlo outcomes, GRPO must sample many responses (e.g., $N=8$) for every prompt. This creates a massive computational bottleneck, slowing down iteration cycles for large models.
Methodology: Sequence-Level Contextual Bandit
The core insight of SPPO is that reasoning isn't a multi-step MDP where every token is a decision; it's a Contextual Bandit where the prompt is the context and the entire output is the action.
1. Collapsing the Horizon
By treating the full sequence $a_{seq}$ as a single atomic unit, SPPO eliminates token-level noise. The reward $R \in {0, 1}$ evaluates the holistic correctness.
2. The Scalar Critic
Instead of a token-level critic, SPPO trains a Value Model $V_\phi(s_p)$ to predict the probability of success for a given prompt. The advantage for every token in the sequence is then simply: $$A(s_p, a) = R - V_\phi(s_p)$$
If a reasoning chain is correct, every step is reinforced equally. If it's wrong, every step is penalized equally. This bypasses the temporal credit assignment problem entirely.
3. Decoupled Critic Architecture
Because estimating "prompt difficulty" is easier than "generating a solution," the authors propose using a Small Critic (e.g., Qwen-1.5B) to align a larger policy (e.g., Qwen-7B).
Experiments & Results
SPPO was evaluated against strong baselines including standard PPO, ReMax, RLOO, and GRPO on high-difficulty math benchmarks (AIME24, AMC23, MATH500).
Key Benchmarks (DeepSeek-R1-Distill-Qwen-7B)
- Performance: SPPO achieved an average score of 58.11% (and 58.56% with the small critic), outperforming GRPO's 57.44%.
- Efficiency: SPPO reached its peak performance in ~22 hours, while baselines like RLOO and GRPO were significantly slower due to multi-sampling overhead.
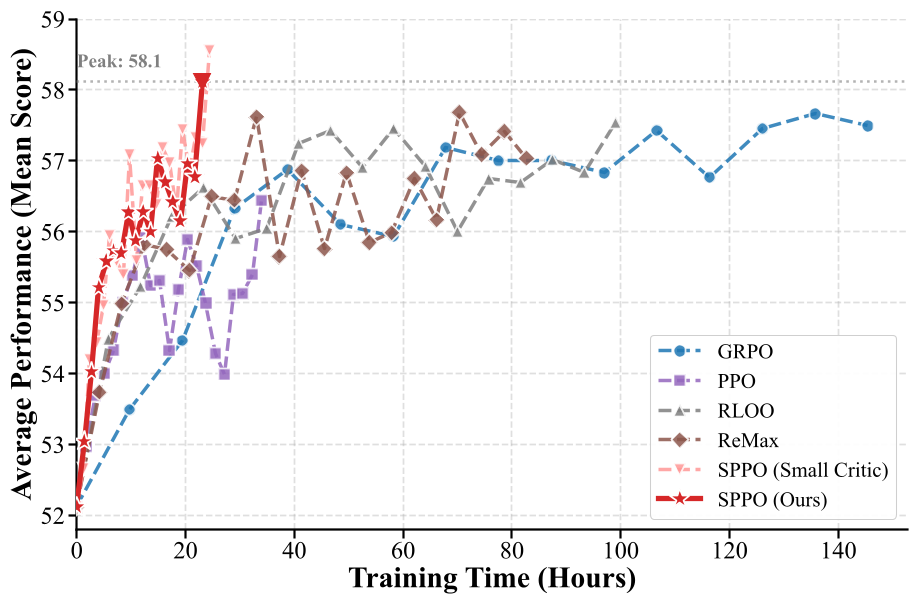
Ablation: Is it just the Loss Function?
The authors tested if simply changing the loss to Binary Cross-Entropy (BCE) in standard PPO would work. It didn't. The performance collapsed, proving that the Sequence-Level formulation—the propagation of a unified advantage—is the true driver of stability.
Critical Analysis & Conclusion
Takeaway
SPPO settles a growing debate in LLM alignment: Do we need complex token-level critics? For tasks with verifiable outcomes (Math, Code), the answer appears to be no. The "sequence-level" view provides a cleaner optimization landscape.
Limitations & Future Work
- Verifiable Rewards: SPPO currently depends on objective rewards (+1 or 0). Extending this to open-ended generation (e.g., creative writing) where objective verifiers are absent remains an open question.
- Future Reach: The "Small Critic" strategy is a massive win for hardware accessibility, showing that we can align 70B+ models using lightweight critics, saving significant GPU memory.
In summary, SPPO provides a resource-efficient, stable, and highly scalable framework, making it a new "Go-To" for researchers looking to push the boundaries of LLM reasoning without the cluster-sized compute requirements of group-sampling methods.