本文提出了 StreetForward,一个用于动态街道重建的 Pose-free 且 Tracker-free 的前馈(Feedforward)框架。该方法基于 VGGT 架构,通过引入因果掩码注意力机制(Causal Masked Attention)和 3D Gaussian Splatting (3DGS) 表示,实现了在无需场景优化的情况下,直接从视频序列推理出高精度的 4D 场景重建。
TL;DR
理想的自动驾驶仿真系统需要能从海量采集数据中快速“回放”真实世界的 4D 场景。StreetForward 代表了这一领域的最新前沿:它抛弃了缓慢的单场景优化(Per-scene Optimization)和对外部追踪器(Tracker)的依赖,通过一个功能强大的 Transformer 前馈架构,在毫秒级时间内从视频中预测出带有速度信息的 3D 高斯场(3DGS),支持在任意视角、任意时间进行高保真渲染。
痛点深挖:为何动态街道重建这么难?
传统的 3D/4D 重建架构(如 NeRF 或原始的 3DGS)面临两个核心障碍:
- 效率陷阱:它们通常需要针对每一个场景运行数千次优化迭代,无法满足大规模自动驾驶数据处理的需求。
- 运动建模困局:现有的前馈模型(如 VGGT)擅长捕捉静态几何,但在处理“运动”时,由于其注意力机制是全局对称的,模型往往无法区分当前帧相对于上一帧的位移方向,导致运动物体出现“重影”或几何坍缩。
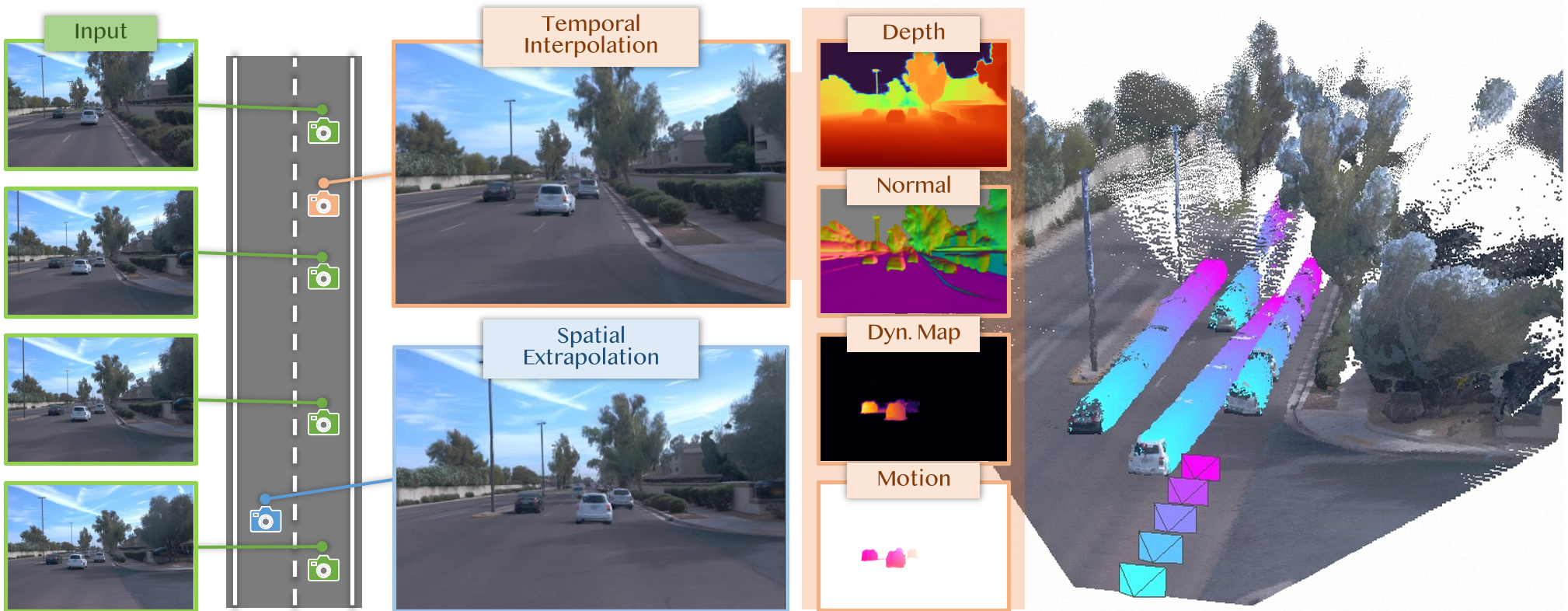
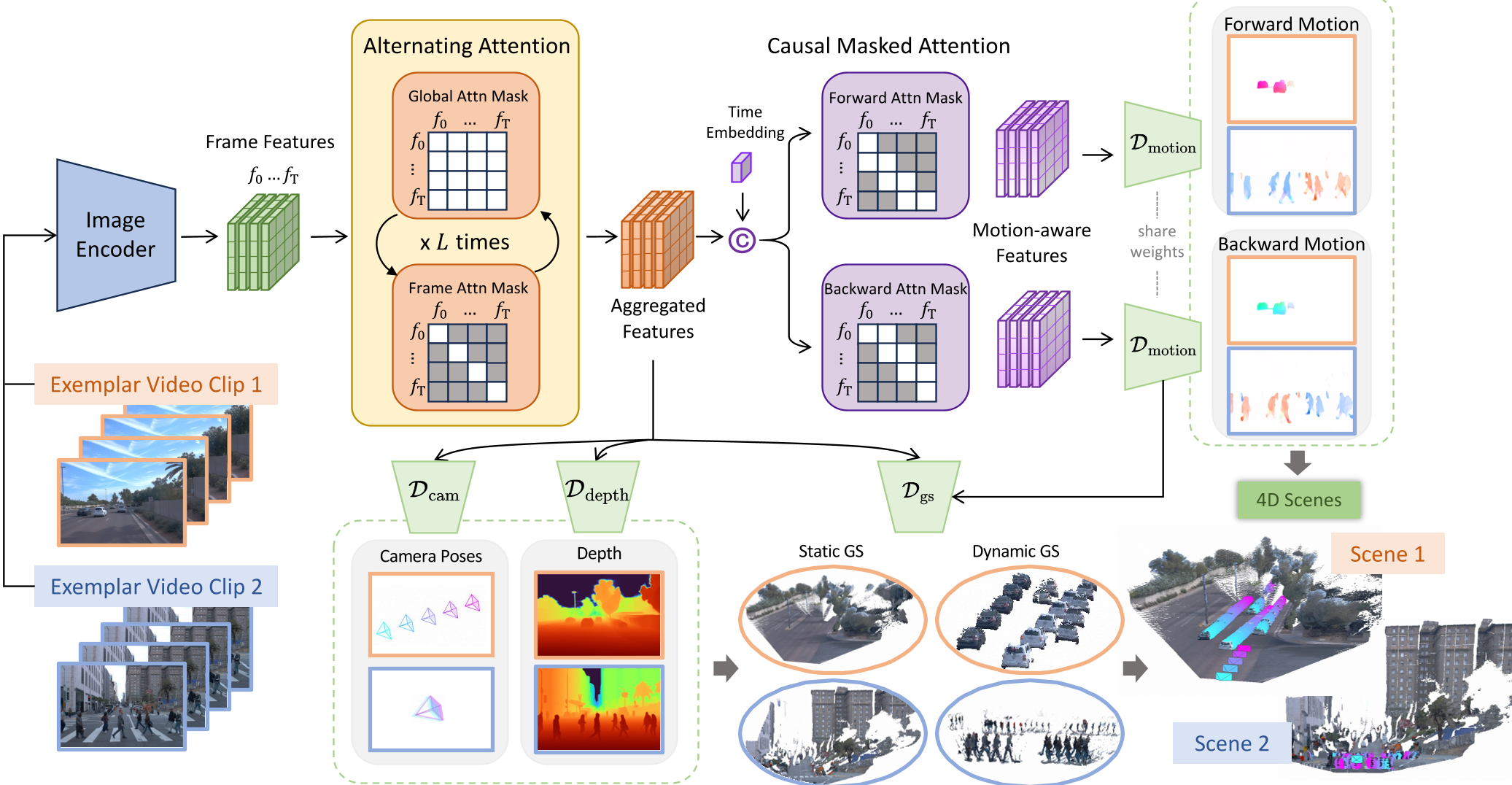
核心方法论:因果注意力与 3DGS 运动解耦
1. 因果动态建模 (Causal Dynamics Modeling)
StreetForward 的杀手锏是在 VGGT 的交替注意力后端中嵌入了因果掩码注意力(Causal Masked Attention)。 作者的直觉非常明确:如果要模型理解运动,就必须打破“所有帧一视同仁”的平衡。通过在注意力层中应用特定的 Frame Mask,强制模型学习“源帧 目标帧”的定向关联,从而让 Latent Representation 能够识别出像素级别的位移趋势。
2. 无监督的速度解码
虽然模型预测的是 3D 高斯球(),但为了处理动态,StreetForward 为每个高斯点预测了一个速度场 (Velocity Field)。
- 静态/动态解耦:通过一个 Motion Head 预测动态概率 。
- 时空一致性约束:利用前后向对称性(Forward-Backward Symmetry)来约束运动预测。这意味着即使没有激光雷达(LiDAR)或人工标注的轨迹,模型也能通过渲染损失(Rendering Loss)自动学到合理的物理运动。
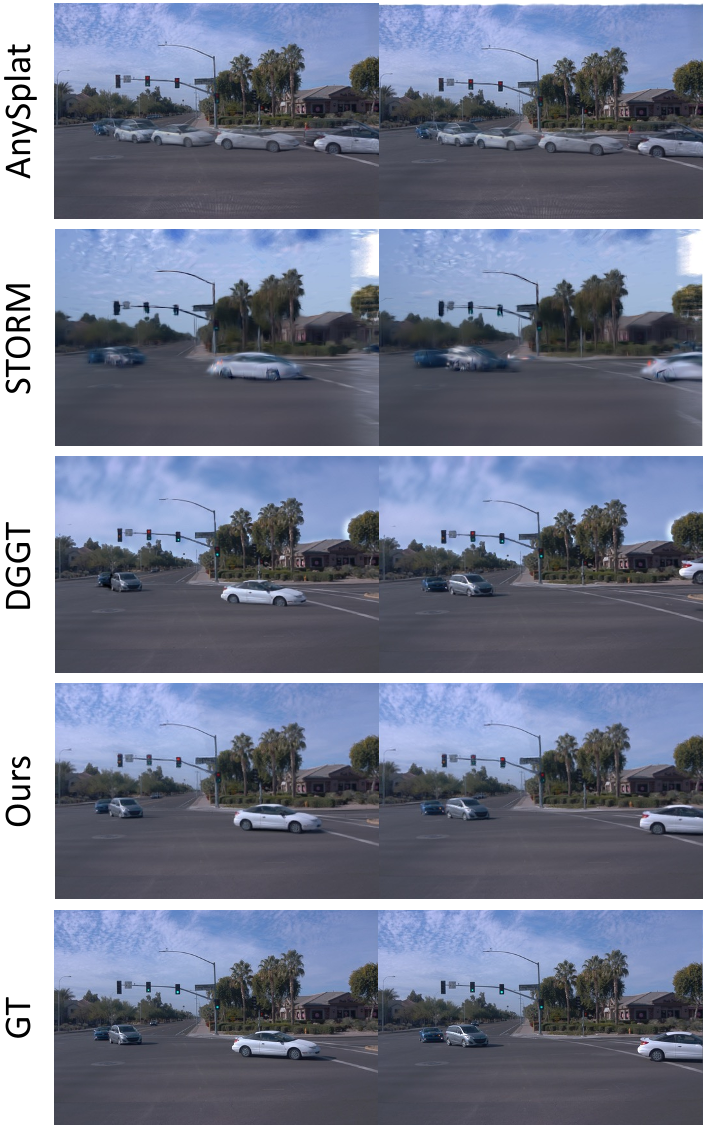
实验战绩:全方位的性能超越
在 Waymo Open Dataset 的测试中,StreetForward 表现出了惊人的几何还原度。
- 深度估计新高度:全图 RMSE 降至 3.14,远超之前的 VGGT (4.07) 和 DGGT (4.08)。
- 动态物体合成:在针对动态区域(Dynamic only)的 PSNR 上,StreetForward 达到了 24.30,相比于目前的主流方法 DGGT (20.99) 提升了近 16%。
消融实验证明了关键模块的价值:
- 如果不加因果注意力,模型在插值时会出现明显的“重影”和运动模糊。
- 局部刚性先验(Local Rigidity) 的加入有效地消除了刚性物体(如汽车)周围的悬浮物。
深度洞察与总结
StreetForward 的成功在于其深刻地理解了 Inductive Bias(归纳偏置) 在 Transformer 架构中的重要性。仅仅堆叠数据是不够的,将物理世界的“因果性”和“刚性”通过数学约束植入注意力机制和损失函数中,是实现从“像素拟合”到“世界建模”跨越的关键。
启示记录:
- 解耦思考:将静态背景与动态实例统一在 3DGS 框架下,但通过运动概率进行选择性聚合,是处理复杂交通流的高效方案。
- 前馈即未来:随着自动驾驶数据的指数级增长,能够实现“零手动干预、即插即用”的重建模型将成为闭环仿真系统的基石。
更多可视化 Demo 请参考项目主页:https://streetforward.github.io