本文推出了 SWE-QA-Pro,一个针对仓库级(Repository-level)代码理解的高难度基准测试集。该工作涵盖了 26 个长尾开源项目,并通过“难度校准”过滤掉无需工具即可回答的简单问题。此外,作者提出了一种基于 SFT 和 RLAIF 的两阶段训练方案,使 8B 规模的开源模型在代码理解任务上超越了 GPT-4o。
TL;DR
在自动驾驶式软件工程(Agentic SE)领域,如何评估模型是真的“看懂了代码”还是仅仅“记住了知识”?本文发布的 SWE-QA-Pro 建立了一个严苛的基准:它只保留那些不查阅代码库就无法回答的问题。通过一套名为 SFT→RLAIF 的两阶段训练秘籍,作者成功让 8B 规模的 Qwen3 模型在复杂代码问答中超越了 GPT-4o,证明了智能体(Agent)的探索能力可以通过高质量合成数据和强化学习实现质变。
背景定位:基准测试的“除水分”革命
目前的 LLM 在代码任务上表现惊人,但学术界一直怀疑这些成绩的“水分”:
- 数据污染:热门仓库的数据早已被模型背得滚瓜烂熟。
- 伪仓库任务:很多所谓的“仓库级”问题,其实只看单一文件甚至只看函数名就能猜出来。
SWE-QA-Pro 的出现,旨在将这些“伪需求”剔除,强制模型必须像人类程序员一样,在成百上千个文件中反复横跳、追踪调用链、定位 Bug 根源。
痛点深挖:为什么现有的评估在“骗”我们?
作者指出,现有基准如 SWE-Bench 虽好,但覆盖的多样性有限(集中在头部项目)。更糟的是,如果一个问题不需要 Tool-calling(工具调用)就能被模型“直感”答对,那它就失去了评估 Agent 导航能力的意义。
因此,SWE-QA-Pro 引入了难度校准(Difficulty Calibration):
- 使用 GPT-4o, Claude 4.5 等强模型作为测试基准。
- 如果模型在不提供仓库上下文(Direct-answer)的情况下就能拿高分,该问题直接舍弃。
- 结果:保留下来的问题,Agent 模式比直接回答模式平均高出 13 分,确保了“工具调用”是通向正确答案的唯一阶梯。
核心方法:SFT→RLAIF 训练秘籍
如何让一个小模型学会如此复杂的行为?作者没有选择堆算力,而是优化了学习路径。
1. Agent 架构:摒弃 RAG,回归探索
不同于传统的检索增强生成(RAG),SWE-QA-Pro Agent 采用了 ReAct(Reasoning + Acting) 循环。它没有预构建索引,而是通过语义搜索、 scoped 文件查看和受限的命令行操作,在 25 轮对话内完成从“迷茫”到“定位”的进化。
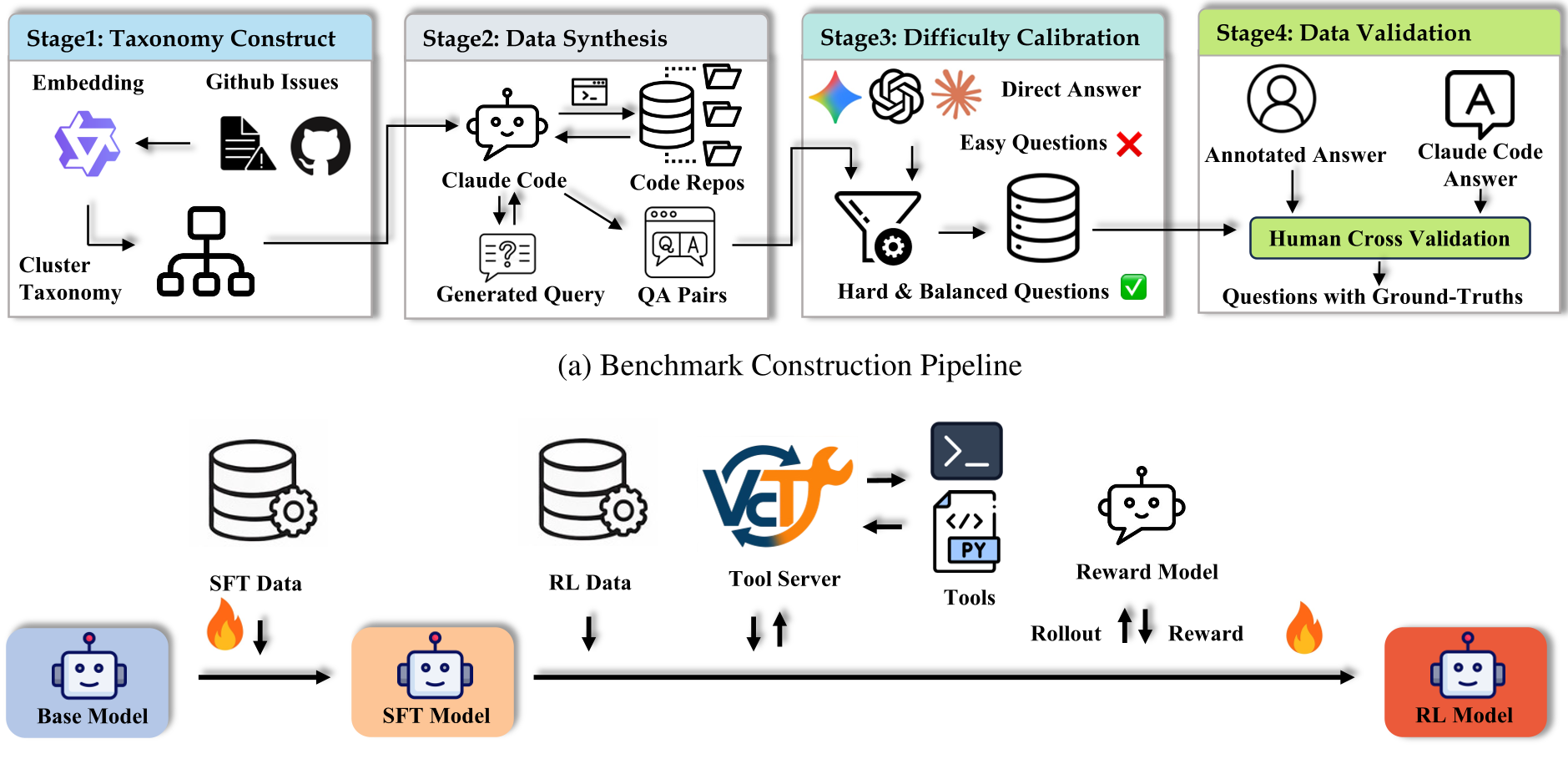
2. 两阶段训练流程
- 第一阶段 (SFT):使用 Claude 生成 1000 条高质量的工具调用链。这一步是让模型学会“怎么敲命令”。
- 第二阶段 (RLAIF):引入 AI 反馈的强化学习(使用 GRPO 算法)。
- 奖励函数设计:不仅看答案对不对,更看重是否引用了准确的文件路径和行号(Correctness, Completeness 权重最高)。
- 抗奖励作弊:专门抑制了“虽然废话多但没干货”的回答。
实验战绩:8B 逆袭 100B+ 巨头
实验结果令人振奋:经过 RLAIF 训练后的 Qwen3-8B,在 SWE-QA-Pro 上的表现不仅吊打了 Llama-3.3-70B,甚至以 35.39 的综合得分超越了原版的 GPT-4o。

深度分析:
- 工具调用量 vs. 质量:Claude Sonnet 4.5 依然是王者,它发起的工具调用次数最多,逻辑也最稳。
- RL 的威力:从表 2 可以看到,RL 阶段相比纯 SFT 阶段,在 Correctness(准确性)上有显著提升。这说明 RL 帮助模型学会了“审慎思考”,而不是盲目堆砌代码片段。
局限性与展望
尽管 SWE-QA-Pro 展示了强大的评估能力,但它目前:
- 领域受限:主要针对 Python 生态(因为需要可执行沙箱环境)。
- 规模有限:为了保证高质量,仅包含 260 个专家校验的问题。
总结 (Takeaway)
SWE-QA-Pro 的贡献在于它为代码 Agent 树立了一面不带滤镜的镜子。它告诉我们:参数量不是唯一,精准的训练反馈(RLAIF)才是小模型在专业领域以弱胜强的关键。 对于开发者而言,这意味着未来的本地化开发 Agent,即使运行在端侧设备上,也有望拥有比肩云端巨头的代码库理解深度。