本文提出了 ControlSketch-Part 框架,旨在教导多模态大模型(VLM)以“分部分(Part-by-Part)”的方式串行生成矢量素描。通过自动标注流水线构建了包含丰富语义零件标注的数据集,并利用两阶段(SFT+RL)训练,在矢量路径生成中实现了 SFT 与带有中间过程奖励的 GRPO 强化学习。
TL;DR
传统的 AI 素描生成模型通常像“打印机”一样瞬间吐出所有线条,而这篇论文让 AI 进化成了真正的“画师”。通过引入 ControlSketch-Part 数据集和一种创新的多步过程奖励 GRPO 强化学习算法,模型学会了按照“头部 -> 躯干 -> 肢体”的语义顺序分部分绘制矢量图(SVG),不仅生成效果刷新 SOTA,更实现了极强的局部编辑能力。
1. 痛点:为什么 AI 绘画总是“一锅端”?
在工业设计或艺术创作中,素描是一个不断迭代、由局部到整体的过程。然而,目前的 Text-to-Vector 模型(如基于 Diffusion 或 CLIP 优化的方法)存在三大弊端:
- 黑盒化:所有笔画一次性生成,用户无法单独修改一只马蹄而不影响整匹马。
- 逻辑缺失:模型不理解“零件”概念,导致在处理复杂指令时长出多余的腿。
- 适应性差:闭源模型(如 Claude)虽有逻辑但画风单一且不可控。
2. 核心突破:ControlSketch-Part 自动化标注流水线
为了教会模型认识“零件”,作者开发了一套精妙的自动标注流水线。它不依赖昂贵的人工,而是让 VLM(如 Gemini 3.0 Pro)进行自我博弈:
- 分解与批判:VLM 先将素描拆解为零件,再由另一个 VLM 作为“批评家”指出漏画或重叠的部分。
- 视觉诊断分配:通过特定的颜色编码(Diagnostic Visualization),将 SVG 路径精准对齐到对应的语义零件。
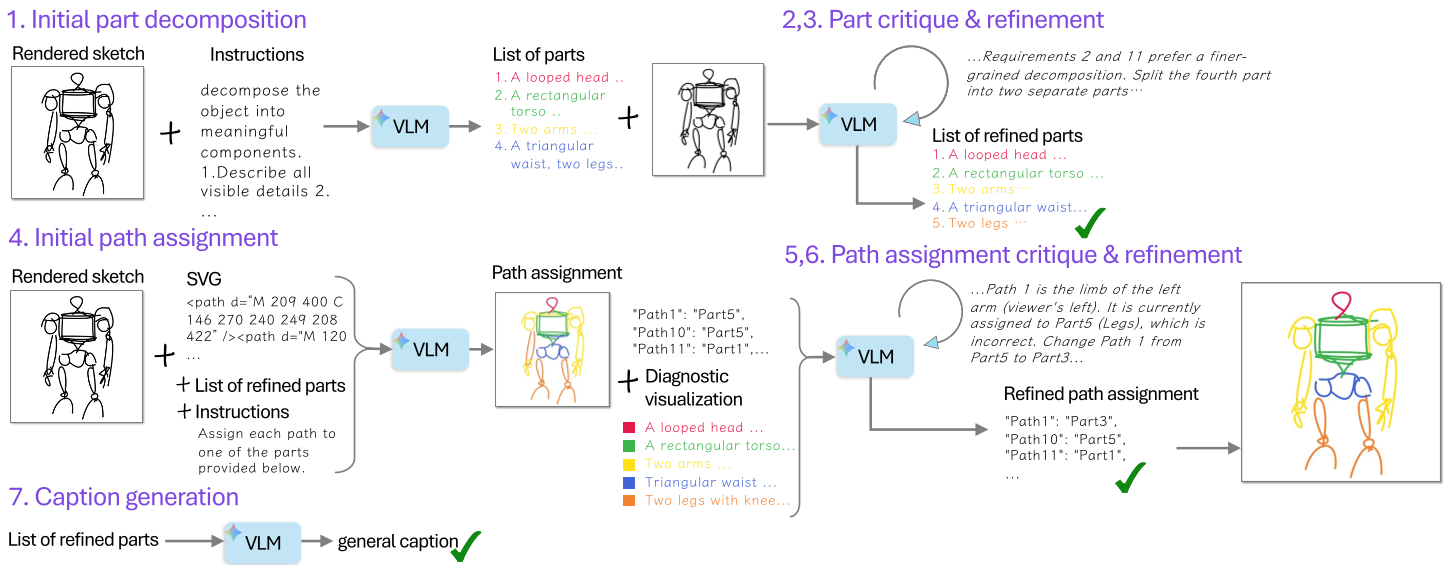 图 1:自动标注流水线示意图,展示了从原始 SVG 到带语义零件标注的演进。
图 1:自动标注流水线示意图,展示了从原始 SVG 到带语义零件标注的演进。
3. 算法演进:从单步 SFT 到多步过程奖励 GRPO
仅仅通过有监督微调(SFT)是不够的。在推理时,模型会根据自己上一轮画出的“丑零件”继续作画,误差会迅速累积。
为了打破这一瓶颈,作者引入了 Multi-turn Process-reward GRPO:
- 策略优化:使用 Group Relative Policy Optimization (GRPO),不需要额外的 Value 网络,通过同一提示词下的多条采样轨迹(Trajectories)互相竞争。
- 过程奖励(Process Reward):不同于只看终点的奖励,作者在每一个零件生成后,利用 DreamSim 计算当前画布与真值(Ground Truth)的中间相似度,实现“密度信用分配(Dense Credit Assignment)”。
- 路径长度约束:加入路径计数惩罚,防止 AI 变得“啰嗦”或“偷工减料”。
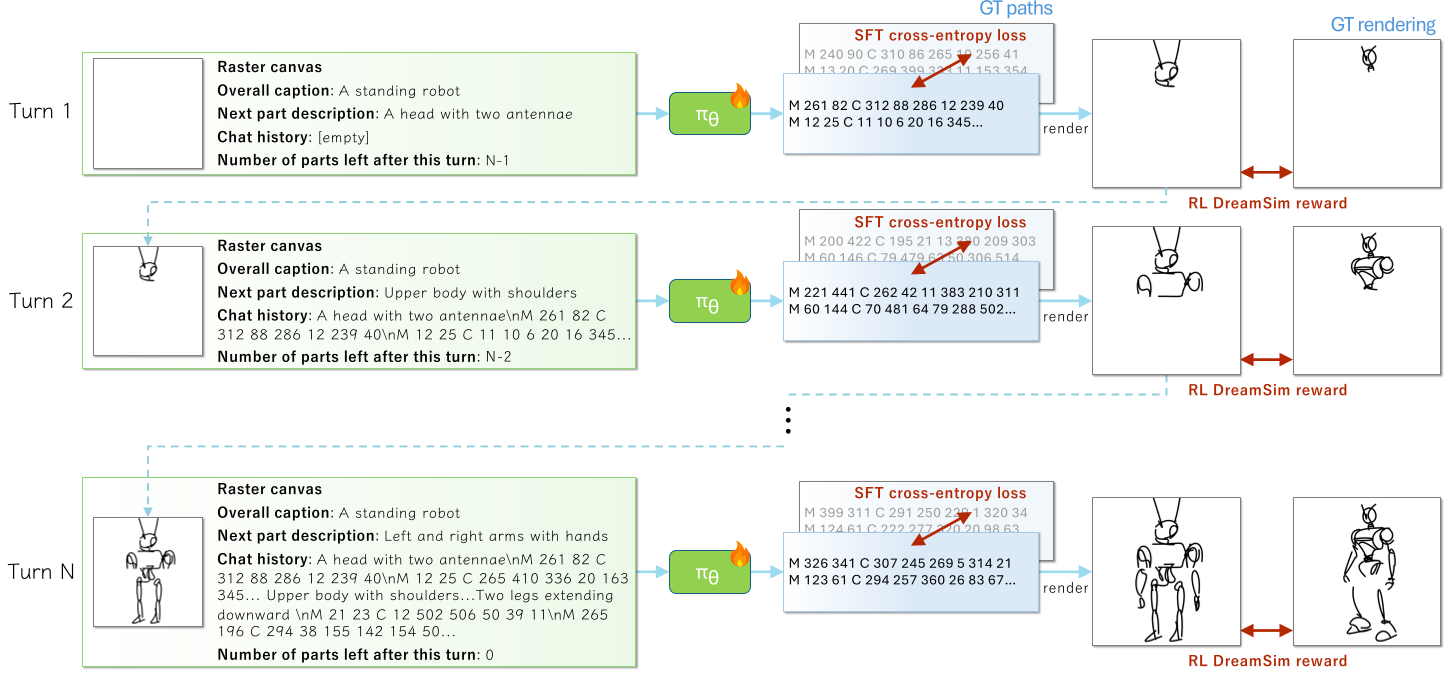 图 2:两阶段训练流程:SFT 规范格式,RL 提升视觉质量。
图 2:两阶段训练流程:SFT 规范格式,RL 提升视觉质量。
4. 实验战绩:AI 画师的自我修养
在与 SketchAgent、Gemini 3.1 Pro 等强劲基线的对比中,ControlSketch-Part 展示了压倒性的优势:
- 文本一致性:Long-CLIP 相似度显著提升。
- 可视化质量:生成线条平滑、结构合理,不再是凌乱的几何体堆砌。
- 局部编辑:用户可以发出指令如“把这辆自行车的篮子换成流线型的”,模型仅需重新绘制特定 Part,保持其他部分不动。
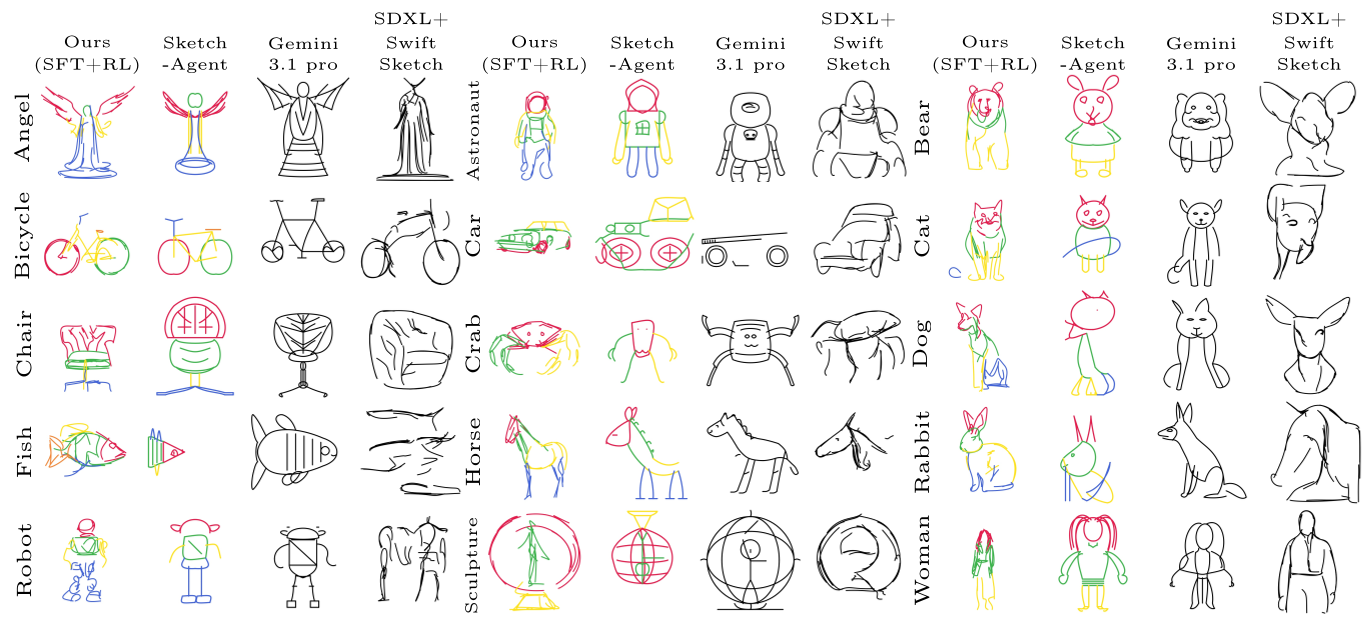 图 3:与各基线方法的定性对比,本方法在细节和零件逻辑上更胜一筹。
图 3:与各基线方法的定性对比,本方法在细节和零件逻辑上更胜一筹。
5. 深度洞察与总结
这篇工作的价值在于它证明了:视觉生成不仅仅是像素或坐标的堆砌,更是对现实世界物理结构的序列化理解。 通过将 GRPO 这种在 LLM 领域大放异彩的 RL 技术引入矢量生成,并配合过程奖励,我们看到了解决生成模型“长直连”误差的新希望。
局限性:目前模型仍依赖于 ControlSketch 预定义的目标类别,对于从未见过的极端抽象概念,其拓扑逻辑仍有失败可能。未来的方向在于引入思维链(CoT)推理,让 AI 在画每一笔前先“想一想”布局。
Takeaway: 构建高质量的、带有中间过程解释的数据集,结合过程化强化学习,是提升 AI 生成质量从“能看”到“好用”的关键门槛。