本文系统研究了多模态大语言模型(MLLMs)在视频指令微调(Video-SFT)阶段的视觉能力演变,提出了“时间陷阱”(Temporal Trap)现象。研究涵盖了 Qwen2.5-VL 等多种架构,证明 Video-SFT 在提升视频理解的同时,往往会导致静态图像空间理解能力的退化。
TL;DR
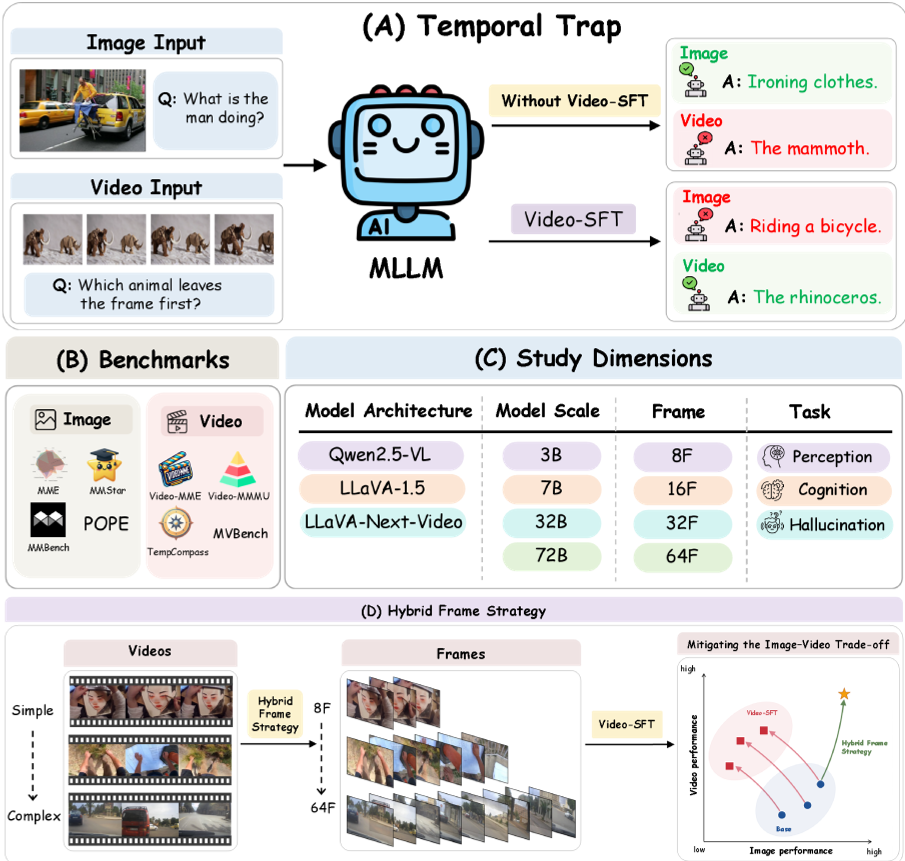
多模态大模型(MLLM)在进化成“全家桶”的过程中遇到了一个意想不到的障碍:视频指令微调(Video-SFT)在增强模型处理动态视频能力的同时,悄悄削弱了它对静态图像的理解力。 本文将其定义为 “时间陷阱”(Temporal Trap)。研究者发现,通过一种基于指令感知的 Hybrid-Frame(混合帧) 采样策略,可以有效平衡空间(图像)与时间(视频)的成本。
1. 动机:视频理解是免费的吗?
在 MLLM 的训练中,业界普遍遵循一种“图像-视频一家的直觉”:既然视频就是一堆图像,那训练视频理应能让模型更懂视觉。然而,事实并非如此简单。
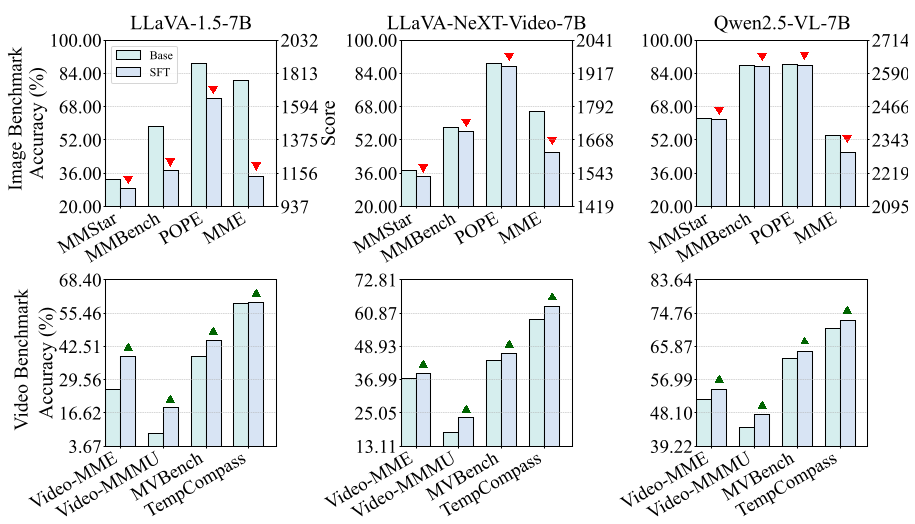
- 观测现象:模型在 Video-MME 等视频榜单刷分的同时,在 MME、MMStar 等图像榜单上却出现了明显的性能下滑(如图 2 所示)。
- 痛点分析:这种冲突在参数量较小的模型上尤为严重,细粒度感知任务(如名人识别、OCR)受创最深。
2. 核心洞察:梯度冲突与时间预算
为什么会发生“陷阱”?作者从理论层面给出了严谨的物理解释:
- 梯度非对齐(Gradient Misalignment):当视频任务的梯度方向与图像任务的梯度方向在共享参数空间中呈钝角(夹角大于 90 度)时,优化视频性能必然会牺牲图像性能。
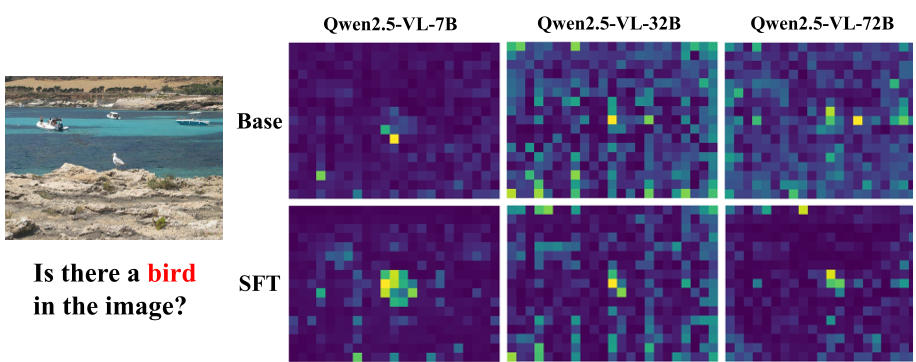
- 冗余即噪声:为了捕捉时间流,我们倾向于增加采样帧数。但对于很多任务(如“这件衣服是什么颜色?”),多出的帧不仅是计算浪费,更是作为噪声干扰了模型对关键空间特征的注意力,使其注意力机制变得分散。
3. 方法论详解:Hybrid-Frame 策略
为了跳出“时间陷阱”,作者提出了 Hybrid-Frame 策略。其核心直觉是:不是所有的视频指令都需要相同的帧数。
- 指令感知分析:通过一个较小的 VLM(如 Qwen2.5-VL-3B)预先审校指令。如果指令涉及“因果推断”或“高速动作”,则增加帧数;如果是询问“静态物体属性”,则减少帧数。
- 动态预算分配:模型不再死板地对所有视频采样 64 帧。实验显示,平均 11 帧的智能采样,效果优于盲目采样 64 帧。
4. 实验战绩
研究团队在 Qwen2.5-VL 和 LLaVA 两大家族上验证了该方法的普适性。
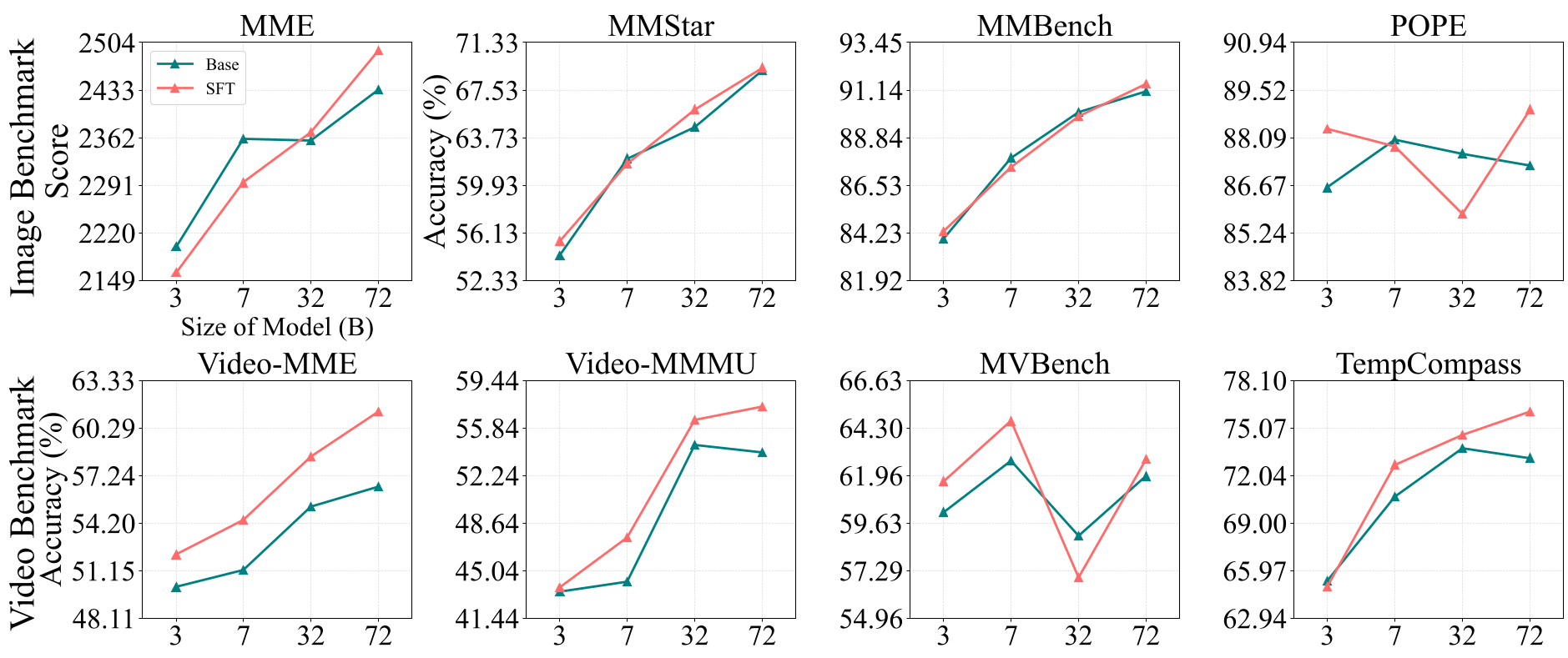
- 性能提升:在 Qwen2.5-VL-7B 上,Hybrid-Frame 成功地在维持视频高分的同时,修复了图像理解的退化。
- 模型规模效应:有趣的是,实验发现 72B 规模的大模型对“时间陷阱”有更强的免疫力,注意力分配更鲁棒,但这通常意味着昂贵的计算成本。
5. 深度总结:通往统一模态之路
本项工作不仅揭示了一个容易被忽略的学术盲区(Video-SFT 的副作用),更传达了一个关键启示:统一视觉建模并不意味着“统一处理”。
目前的统一架构在底层(Shared Backbone)实现了融合,但在数据交互层仍需要更精细化的调度。未来的通用多模态模型,必须像人类一样,能够根据任务的紧急程度和复杂度,自适应地分配视觉感受野和计算资源。目前 Hybrid-Frame 虽是启发式的尝试,但它指明了通往“极简且高效”视觉智能的方向。
局限性:当前 Hybrid-Frame 采样比例是离散的(8/16/32...),未来的研究可以探讨如何实现连续、像素级的动态采样长度控制。
Senior Editor's Note: 此项研究对正在进行 Video Fine-tuning 的算法团队具有重要的工程指导价值——在加大数据和序列长度前,先审视一下你的图像基准是否还在。