本文推出了 TerraScope,这是一个统一的视觉语言模型(VLM),专门用于地球观测(EO)领域的像素级地理空间推理。它通过联合生成分割掩码(Segmentation Masks)和推理链,实现了在光合、SAR(合成孔径雷达)及多时相数据上的高精度 SOTA 表现。
TL;DR
TerraScope 是一款专为遥感影像设计的视觉语言模型,它打破了以往模型只能“笼统描述”的局限,通过将像素级分割掩码嵌入推理流(CoT),实现了对面积、距离、边界关系及多时相变化的精确计算。伴随而来的还有 100 万规模的 Terra-CoT 数据集和首个像素级遥感推理基准 TerraScope-Bench。
背景定位:这是地球观测(EO)领域从“视觉感知”向“精细空间推理”转型的标杆之作,填补了遥感大模型在像素级可解释性上的空白。
痛点深挖:为什么遥感模型总是“胡说八道”?
在处理卫星影像时,GPT-4o 或地学专用模型常在计算“覆盖比例”或“破损面积”时折戟。核心痛点有三:
- 空间连续性:不同于自然图像中的离散目标(如猫或狗),遥感影像的地物(如林地、农田)是连续分布的,传统的 Bounding Box(包围框)粒度太粗,噪声太大。
- 多源数据隔阂:光学影像怕云,SAR 影像难懂,现有模型很难在同一个推理步骤中根据天气自动切换数据源。
- 推理过程黑盒:你不知道模型给出“30% 覆盖率”的依据是什么。
核心机制:以像素之名“思考” (Thinking with Pixels)
1. 像素锚定的思维链 (Pixel-Grounded CoT)
TerraScope 的创新在于其双解码器协同机制。当模型在思考时,如果认为需要关注特定区域,它会主动输出一个 [SEG] 标记,触发分割解码器画出该地物的像素级掩码。
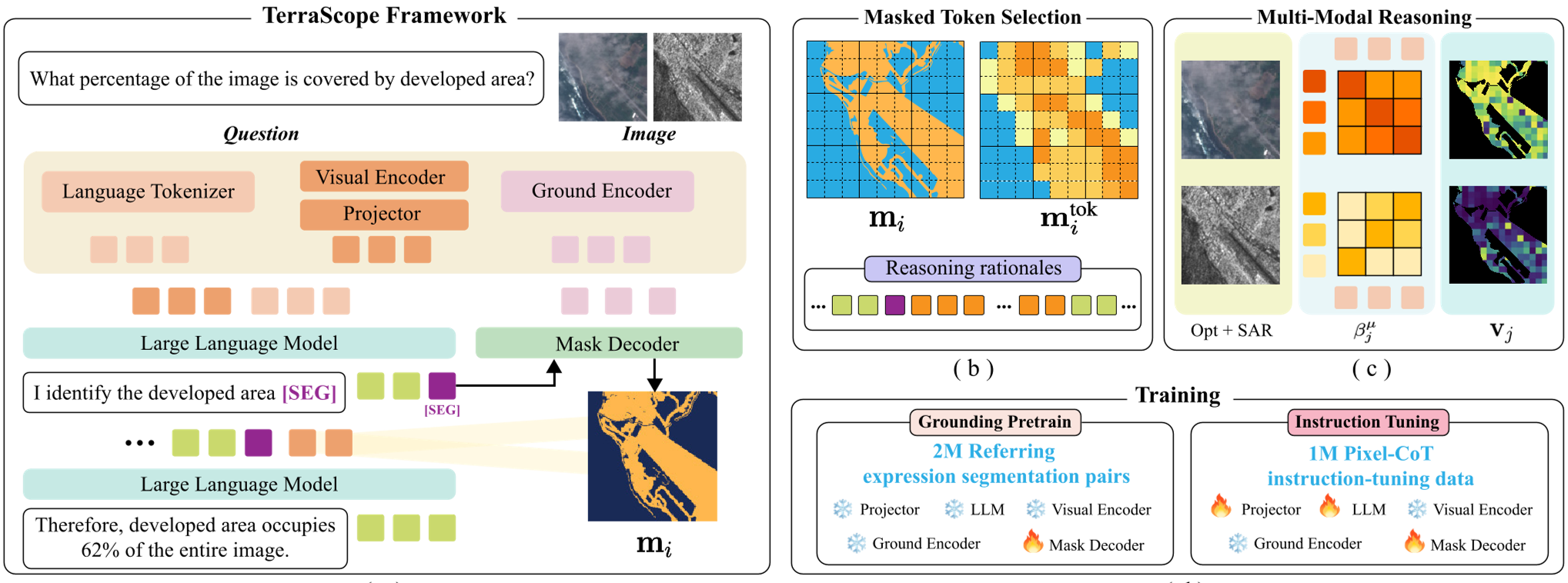 图注:TerraScope 整体架构,展示了如何将分割后的视觉特征重新注入 LLM 以辅助后续推理。
图注:TerraScope 整体架构,展示了如何将分割后的视觉特征重新注入 LLM 以辅助后续推理。
2. 多模态与多时相的精妙融合
- 光学-SAR 动态切换:通过文本引导的交叉注意力机制(Cross-Attention),模型能感知影像质量。如果发现光学图有云,它会自动调高 SAR 特征的权重。
- 显式时间定位:处理变化检测时,模型会生成
Image: t1 [SEG]这样的指令,明确指代是在哪一时刻的图像上进行分割。
实验战绩:全方位的 SOTA
作者构建了 TerraScope-Bench,涵盖了覆盖率分析、面积量化、距离测量等六大高难度任务。
 表注:在各项任务对比中,TerraScope 相比通用模型和已知遥感模型展现了断层式的优势。
表注:在各项任务对比中,TerraScope 相比通用模型和已知遥感模型展现了断层式的优势。
关键发现:
- 准确度提升:在精细的空间分析任务中,TerraScope 的平均得分(68.9%)远超 GPT-4o(38.7%)。
- 分割质量决定推理上限:实验证明,掩码的 IoU(交并比)与推理结果的正确性呈极高的正相关。
深度洞察:它是如何改变行业的?
TerraScope 的价值不仅在于刷榜,更在于它提供了一种透明的决策机制。在灾害响应中,模型不仅告诉救援人员“房屋损毁严重”,还能直接勾勒出受损的具体位置和面积,这种“辅助证据”是传统 VLM 无法提供的。
 图注:TerraScope 在面积计算和距离测量中的推理 trace 可视化。
图注:TerraScope 在面积计算和距离测量中的推理 trace 可视化。
局限与未来 (Critical Thinking)
尽管 TerraScope 极具开创性,但主编认为仍有提升空间:
- 光谱限制:目前主要依赖 RGB 频道,未完全释放 Sentinel-2 多光谱(如近红外、红边波段)在植被监测上的潜力。
- 推理成本:大量的
[SEG]标记增加了上下文长度,在超大规模实时监测场景下,KV 缓存的压力不容小觑。
总结:TerraScope 是地学 AI 的一次重要进化。它教会了大模型不仅要“看”影像,更要“量”像素。这种将底层视觉任务与上层逻辑推理深度耦合的思路,必将成为下一代专业垂直领域多模态模型的标配。