本文提出了 Think Over Trajectory 范式,通过视频生成模型将粗粒度的蜂窝信令数据(Cellular Signaling)还原为高精度 GPS 轨迹。该方法利用 Wan2.2-TI2V 视频模型并结合新颖的 Traj-GDPO 强化学习算法,在 Sig2GPS 任务中达到了 SOTA 性能。
TL;DR
北航等机构的研究者提出了一种全新的 Think Over Trajectory 范式。他们不再把轨迹看作一串 GPS 坐标数字,而是模仿人类专家的直觉——在地图上“临摹”路径。通过将 Sig2GPS(信令转 GPS)任务建模为地图视觉领域的视频生成任务,该方法在精度和推理效率上均降维打击了传统的工程流水线及深度学习回归模型。
1. 痛点:为什么“坐标回归”总是不尽如人意?
在电信领域,蜂窝信令覆盖广但精度极低(通常只能定位到基站级别)。为了将其转化为能用的 GPS 轨迹,传统做法痛苦不堪:
- 工程冗余:需要经历平滑抽稀、地图匹配、路网推理等多个环节,单条处理耗时以分钟计。
- 空间表征缺失:基于文本或数值的序列模型(如 GRU, Transformer)看不到地图,容易生成穿墙、逆行或断裂的非法轨迹。
- Inductive Bias 缺失:回归模型很难学习到“必须在路上行走”这一物理常识。
作者受启发于领域专家:专家只需看一眼渲染在地图上的信令散点,就能凭直觉“勾勒”出可能的行驶路径。既然人类可以用视觉解决,AI 为什么不行?
2. 核心架构:像画画一样绘制轨迹
作者选用了目前最强的开源视频生成架构之一 Wan2.2-TI2V。其核心思路是:
- 输入(Conditioning):一张包含地图底图和信令轨迹折线的静态图片。
- 输出(Video Generation):一段视频,视频中 GPS 蓝点随着帧的推移在地图上连续移动,最终形成完整的轨迹。
这种设计让模型在 Latent Space 中直接学习地图的拓扑结构(如道路边缘、交叉口),从而保证生成的轨迹天然符合路网约束。
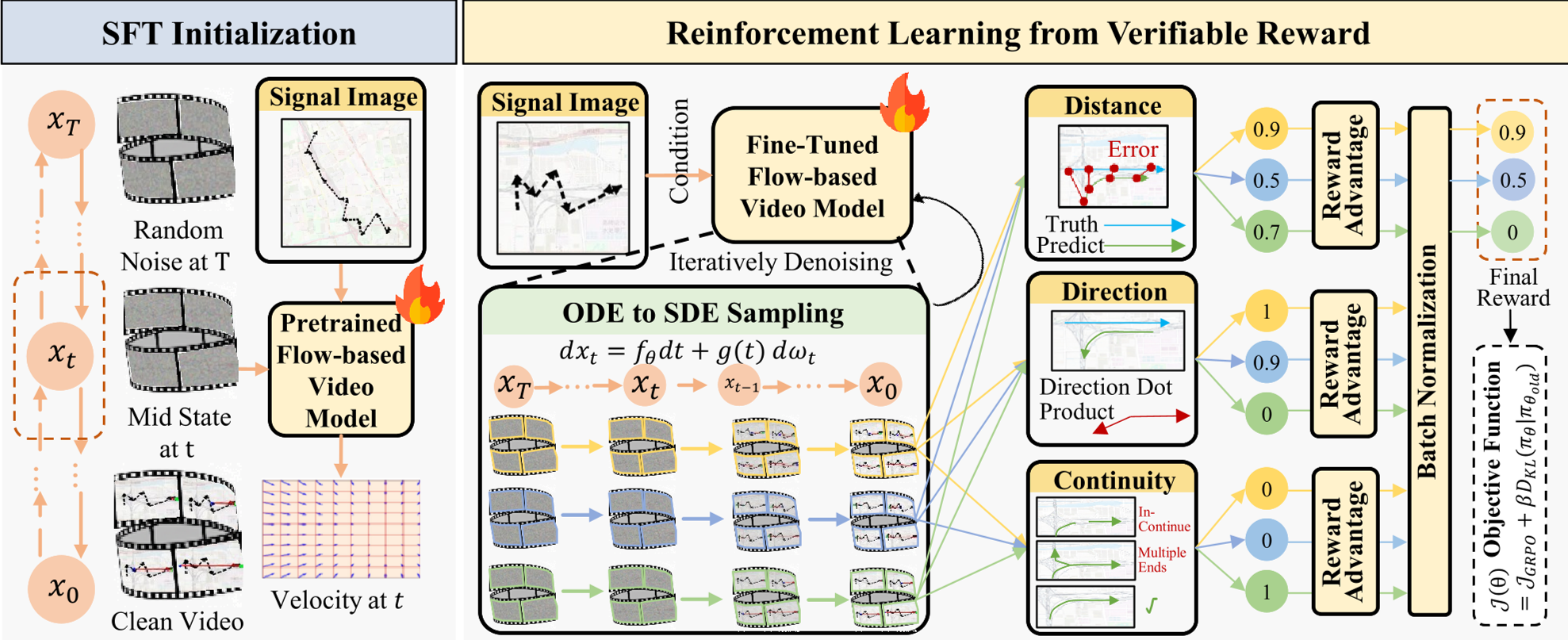 图 1:Think Over Trajectory 整体框架,包含双阶段训练:SFT 与 Traj-GDPO。
图 1:Think Over Trajectory 整体框架,包含双阶段训练:SFT 与 Traj-GDPO。
3. Traj-GDPO:从视觉模拟到物理对齐
单纯的监督微调(SFT)是以像素重构为目标的,虽然画得像,但细节上可能出错。为此,作者引入了**可验证奖励(Verifiable Rewards)**进行强化学习对齐:
- 距离奖励(Distance Reward):生成的点必须靠近真实 GPS。
- 方向奖励(Direction Reward):惩罚方向反向或航向偏差。
- 连通性奖励(Continuity Reward):必须是单条连续线,不能生成断点。
针对多目标优化可能带来的数值不稳定,作者提出了 Traj-GDPO(轨迹感知的组脱耦策略优化)。它对不同量纲的奖励进行组内正态化和权重解耦,确保模型能均衡学习到所有约束。
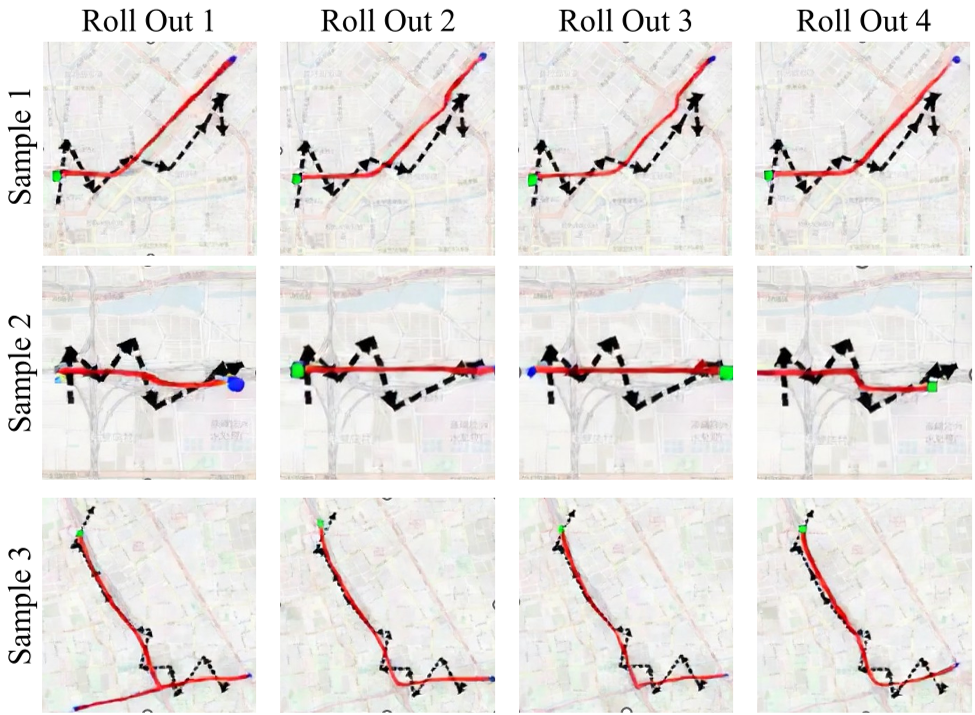 图 2:不同 Roll-out(采样)下的多样性表现,展示了模型对多路径假设的探索能力。
图 2:不同 Roll-out(采样)下的多样性表现,展示了模型对多路径假设的探索能力。
4. 关键战绩:跨城市迁移与效率飞跃
实验结果非常惊人:
- 精度碾压:在 MAE 和 RMSE 指标上全面超越 Transformer 系模型(如 SigFormer, TrajFormer)。
- 工业降效:处理耗时从工业方案的 120s+ 缩减至 30s,且无需复杂的后处理和地图匹配步骤。
- 跨城市“神迹”:在南京训练的模型,直接在西安、成都的地图上也能跑出极高精度(见下表 3)。这意味着模型学到的是**“地图-路径”的通用推理规律**,而非死记硬背经纬度。
| Method | Chengdu (MAE↓) | Xi'an (MAE↓) | | :--- | :--- | :--- | | Traj-MLLM | 236.13 | 389.38 | | Ours (Xi'an trained) | 234.85 | 367.16 |
5. 深度洞察
该工作的本质贡献在于逻辑坐标与地理空间的解耦。通过视频生成,模型不再纠结于具体的浮点数坐标转换,而是在视觉流中处理时空一致性。
局限性分析:
- 资源消耗:视频生成模型对 GPU 算力要求仍高于轻量级序列模型。
- 长行程限制:目前生成 21 帧,对于极长距离的跨城轨迹,可能需要引入分段生成或更高效的流采样技术。
总结 (Takeaway)
《Think over Trajectories》向我们展示了视频大模型(Video Foundation Models)在生成电影、动画之外的巨大潜力——它们可以作为物理世界的高级推理机。在地理信息系统(GIS)和智慧城市领域,这种“视觉辅助决策”或许会催生出一批全新的 AI 原生应用。