本文提出了 ThinkJEPA,这是一个由视觉语言模型 (VLM) 引导的 JEPA 式潜空间世界模型框架。通过引入“双时间路径”设计,该方法在保持 V-JEPA2 高频动力学建模能力的同时,利用 Qwen3-VL 等 VLM 提供的长程语义指导,在手部操作轨迹预测任务中刷新了 SOTA 性能。
TL;DR
传统的潜空间世界模型(如 V-JEPA)虽然擅长预测物理动力学,但往往“只见树木不见森林”,缺乏对长时程任务目标的语义理解。本文提出的 ThinkJEPA 创新性地引入了视觉语言模型(VLM)作为“思考者”分支,通过双时间路径设计,既保留了对高频动作的捕捉,又获得了跨越长窗口的语义导航,在手部操作轨迹预测中表现卓越。
背景定位:这是对 Meta 的 V-JEPA 框架的一次重大增强,通过多模态大模型的知识注入,解决了纯视觉预测器在复杂长任务中容易“迷失”的痛点。
痛点深挖:为什么世界模型需要“思考者”?
在自动驾驶或机器人操作中,世界模型(World Model)的核心是预测未来。目前的 SOTA 路径是 JEPA (Joint-Embedding Predictive Architecture),它在表征空间而非像素空间做预测,效率极高。
然而,现有的 JEPA 模型存在两大死穴:
- 视野狭窄:为了保证计算效率,通常只看一小段密集的视频帧,导致模型只懂局部物理规律(如:手指在动),不懂宏观意图(如:这是在系鞋带)。
- 语义缺失:纯视觉预训练的模型缺乏对实体属性、因果逻辑的开集理解(Open-vocabulary knowledge)。
如果直接用 VLM 来做预测呢?VLM 因为计算量太大,只能看稀疏的抽样帧,且受限于“语言输出瓶颈”,很难输出精确到毫米级的物理轨迹。
核心架构:双时间感知路径 (Dual-Temporal Pathway)
ThinkJEPA 的巧妙之处在于“各司其职”。它并没有试图训练一个巨大的单一模型,而是构建了一个互补的双分支结构。
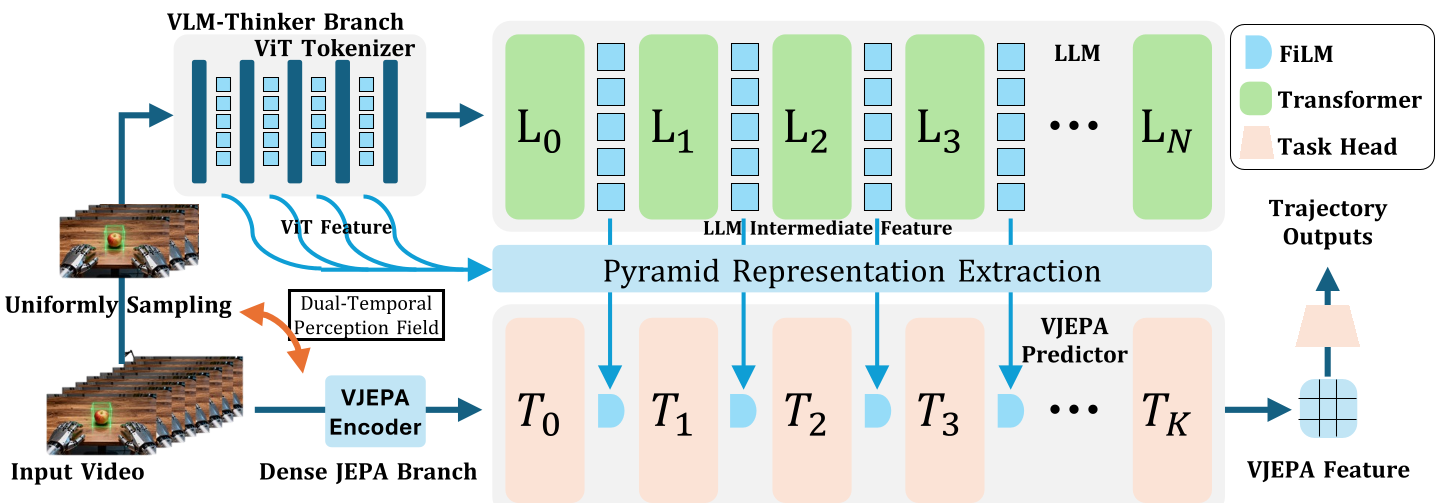
- 密集采样路径 (JEPA Branch):捕捉高频的运动细节、接触点变化等物理微操。
- 均匀采样路径 (VLM Thinker Branch):以大步长横跨整个视频轴,利用 Qwen3-VL 等模型提取全局语义。
关键技术:分层金字塔特征提取
单纯利用 VLM 的最后一层输出往往会丢失空间细节。作者提出了分层金字塔表示提取(Hierarchical Pyramid Extraction),从 VLM 的不同深度(例如第 0, 4, 8...27 层)提取隐藏状态。
- 低层特征:保留更多的视觉空间线索。
- 高层特征:包含抽象的推理逻辑。
这些特征通过 FiLM (Feature-wise Linear Modulation) 模块逐层注入到 JEPA 预测器中,实现“语义对动力学调控”。
实验战绩:让预测更长远、更稳定
研究团队在 EgoDex(第一视角操纵)和 EgoExo4D(技能活动)数据集上进行了验证。
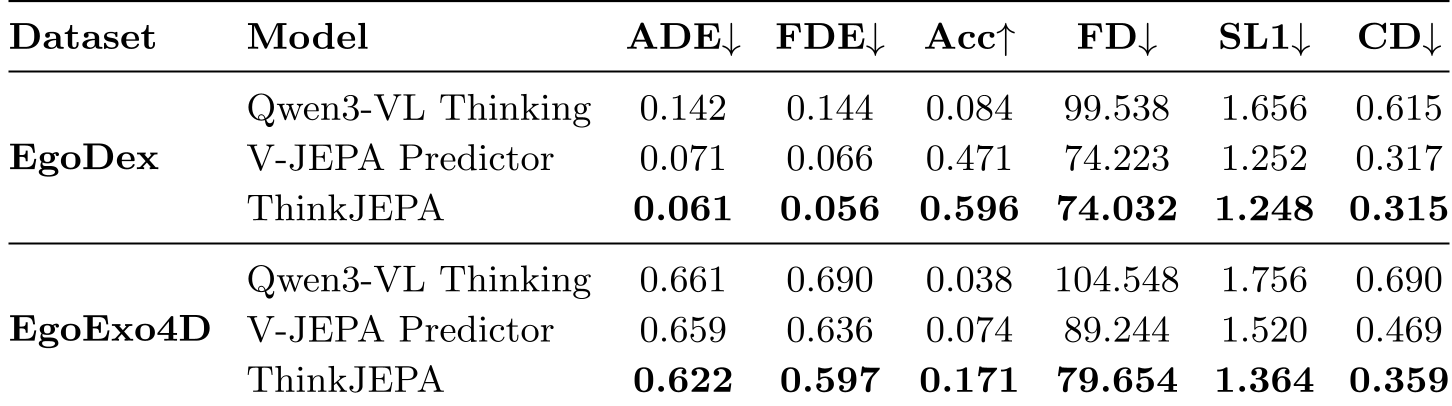
1. 精度全面碾压
如下表所示,ThinkJEPA 在轨迹预测精度(Acc)上相比于纯 V-JEPA 和纯 VLM (Qwen3-VL) 都有巨幅提升。在 EgoDex 上,Accuracy 从 0.471 提升到了 0.596。
2. 长程预测的稳定性
在 Recursive Rollout(递归外推) 实验中,传统模型往往会随着时间推移产生误差漂移(Drift)。得益于 VLM 提供的长程上下文,ThinkJEPA 在预测未来 32 步时依然保持了较低的位移误差。
深度洞察:为什么这种组合奏效?
- 跨越语言瓶颈:以往的研究硬要 VLM 输出坐标数字,这实际上违背了 LLM 处理文本的直觉。ThinkJEPA 提取的是 VLM 的中间层隐向量,这里包含了丰富的、尚未被压缩成自然语言的视觉逻辑。
- 电力的合理分配:密集计算交给轻量级的 JEPA 预测器,昂贵的 VLM 只处理几帧图像,实现了性能与计算开销的最佳平衡。
总结与局限 (Critical Analysis)
Takeaway: ThinkJEPA 证明了潜空间世界模型不必“孤军奋战”,大模型的语义能力可以作为一种高级的正则项或引导信号,显著提升物理世界的仿真能力。
局限性:
- 推理延迟:虽然 VLM 采样稀疏,但启动一个大型 VLM 思考者分支仍会带来初始延迟,在实时控制场景中需进一步优化。
- 引导深度:目前的注入方式仍属于特征层面的线性调制,未来是否可以使用更复杂的交叉注意力(Cross-attention)来实现双向的信息互通?
未来展望:这种“密集动力学+稀疏语义”的范式极有可能成为未来具身智能(Embodied AI)世界模型的标配架构。