This paper introduces TiCo, a post-training framework that enables Spoken Dialogue Models (SDMs) to generate responses with controllable durations based on user instructions. By utilizing Spoken Time Markers (STMs) and a two-stage training process involving self-generation and Reinforcement Learning with Verifiable Rewards (RLVR), TiCo achieves state-of-the-art time-controllability in spoken interactions.
TL;DR
In the world of voice assistants, "brevity is the soul of wit"—but for AI, it’s a massive technical challenge. TiCo (Time-Controllable training) is a novel two-stage framework that teaches Spoken Dialogue Models (SDMs) how to tell time. By inserting Spoken Time Markers (STM) into their internal "thought" process, models can now follow instructions like "Summarize the news in exactly 30 seconds" with high precision, outperforming even GPT-4-based cascaded systems.
The "Time Blindness" of Modern Speech AI
While Large Language Models (LLMs) have become masters of text, their spoken counterparts (SDMs) remain "time-blind." In text, controlling length is a matter of counting tokens. In speech, duration is non-linear. Factors like:
- Phonetic Composition: Some words take longer to say than others despite having fewer characters.
- Prosody: Emotional or emphasized speech changes the tempo.
- Speaker Variation: Different "voices" have different natural speeds.
Existing models either ignore duration instructions entirely or rely on crude truncation, leading to unnatural, cut-off responses.
Methodology: Teaching AI to "Think" in Seconds
The core insight of TiCo is that time awareness must be an intermediate planning step. The authors introduce a two-stage training pipeline:
Stage 1: Building a Temporal Compass (SFT)
The model is first trained to predict Spoken Time Markers (STMs)—discretized timestamps (e.g., <5.2 seconds>) interleaved with its text output. To do this without expensive human labeling, the authors use self-generation:
- The model generates a response.
- An ASR (Whisper) aligns the text to the audio to find exact timestamps.
- The model is fine-tuned to predict these timestamps as if they were part of its natural language.
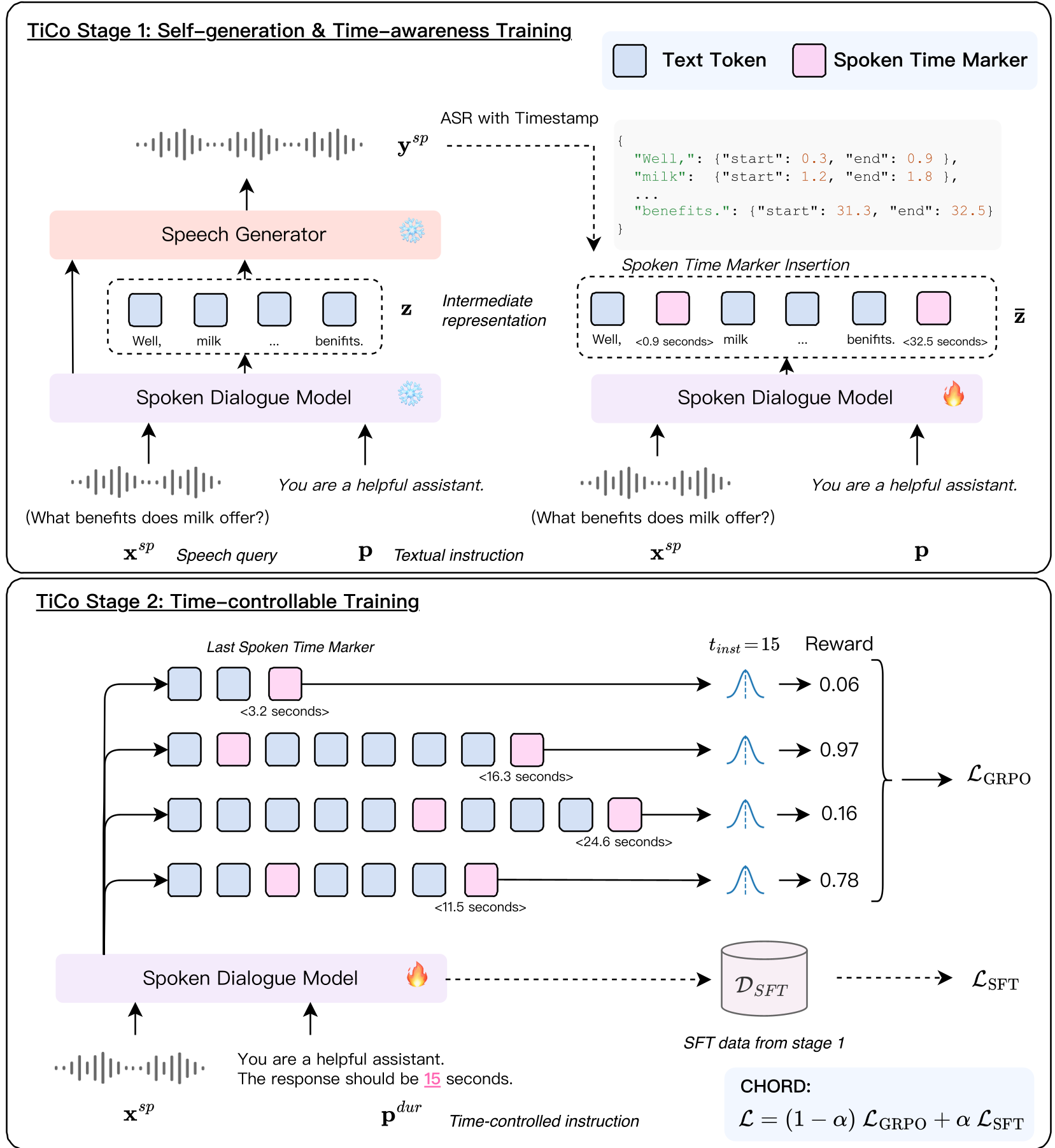 Figure 1: The TiCo two-stage framework. Stage 1 focuses on learning time awareness through self-generated STMs; Stage 2 applies RLVR to enforce duration constraints.
Figure 1: The TiCo two-stage framework. Stage 1 focuses on learning time awareness through self-generated STMs; Stage 2 applies RLVR to enforce duration constraints.
Stage 2: Enforcing Constraints with RLVR
Once the model understands the concept of time, Stage 2 uses Group Relative Policy Optimization (GRPO) to reward the model for hitting specific time targets. The "Verifiable Reward" system checks:
- Accuracy: Does the final STM match the requested duration?
- Monotonicity: Do the timestamps only move forward?
- Diversity: Is the model actually changing content rather than just repeating markers?
Experiments: Precision Under Pressure
The researchers developed TiCo-Bench, sourcing queries from benchmarks like InstructS2S and LIFEBench.
Key Performance Gains:
- MAE (Mean Absolute Error): TiCo achieved an error of only 4.54 seconds, compared to 13.01 seconds for the backbone Qwen-2.5-Omni model.
- Superiority over GPT: Even a cascaded system (GPT-4 generating text + a dedicated TTS) had a higher error (10.41s), proving that text-level planning isn't enough for speech-level control.
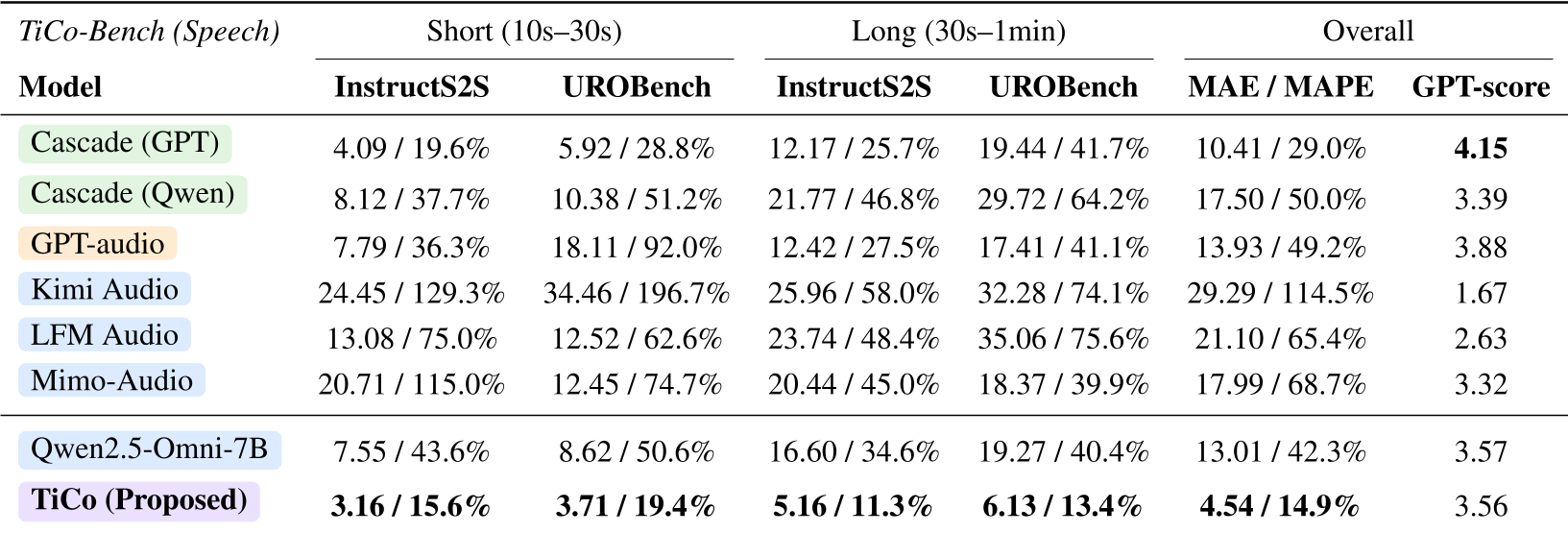 Table 1: TiCo consistently outperforms all baselines (Commercial, Open-Source, and Cascaded) across both short and long duration settings.
Table 1: TiCo consistently outperforms all baselines (Commercial, Open-Source, and Cascaded) across both short and long duration settings.
Zero-Shot Generalization
One of the most impressive findings is Generalization. Despite being trained primarily on responses under 40 seconds, TiCo successfully managed durations up to 1 minute without a significant spike in error. It also worked seamlessly when queries were provided by text instead of speech, showing the temporal reasoning is "modality-agnostic."
Critical Insight: Why it Works
TiCo works because it doesn't try to "force" the speech synthesizer at the end of the pipeline. Instead, it adjusts the semantic content during the "thinking" phase. If the model sees it only has 5 seconds left but much to say, the learned policy encourages it to summarize or conclude more rapidly—mimicking human conversational adaptability.
Conclusion & Future Directions
TiCo represents a significant step toward functional speech agents. Whether it's a car navigation system that needs to finish a sentence before your next turn, or a medical assistant providing a 10-second summary in an emergency, time-controllability is a non-negotiable feature for real-world deployment.
The authors suggest that future work will focus on even higher precision and integrating this with other controllable behaviors like emotion and multi-turn reasoning.