Tora3 是一个轨迹引导的音视频(AV)统一生成框架。通过引入物体轨迹作为共享的运动学先验,该方法显著提升了生成内容在视觉运动与声音事件之间的物理一致性,在包括 FVD、FGAS 和运动声音相关性(MAIC)在内的多项指标上达到 SOTA。
TL;DR
阿里巴巴云视觉团队与复旦大学联合推出的 Tora3,通过将“物体轨迹”升级为音视频共享的运动学核心先验,解决了视频生成中物体动得“假”和声音对不准“位”的顽疾。它不仅能让赛车在 4K 画面中丝滑漂移,还能让引擎轰鸣声随速度实时起伏,在物理真实性评估中大幅领先 LTX-2 和 Ovi 等强力基线。
背景定位:从语义对齐到物理感知的飞跃
目前的 Text-to-Audio-Video (T2AV) 模型虽能生成高分辨率画面,但常在“物理常识”上翻车。比如球撞到墙了声音慢了半秒,或者汽车匀速行驶声音却忽大忽小。 Tora3 认为,轨迹 (Trajectory) 是连接画面运动和声音演变的天然纽带。轨迹不仅包含空间位置,还蕴含了速度、加速度等关键动力学特征,而这些正是决定“声音何时响、响多大”的物理基础。
核心机制:三位一体的运动增强架构
1. 轨迹对齐运动表示 (Trajectory-aligned Motion Representation)
传统的做法是弄个额外的轨迹编码器,但这会增加分布偏移。Tora3 另辟蹊径:直接在 latent 空间动手。它将首帧物体的 Latent 特征直接沿着预设轨迹“搬运”到后续帧的对应位置。由于 VAE Latent 具有空间平滑性,这种操作能最直接、无损地注入运动引导。
2. 二阶运动学-音频对齐 (Kinematic-Audio Alignment)
这是 Tora3 的点睛之笔。它不仅告诉音频模型物体在哪,还计算了每个时刻的:
- 位置 (r):提供空间上下文。
- 速度 (v):决定声音的模式(如滑动与滚动的区别)。
- 加速度 (a):精准捕捉撞击、急停等爆发性音效的触发点。 通过特殊的符号对数压缩处理,这些特征被注入音频 DiT 的 Cross-Attention 层,让模型学会“看速给声”。
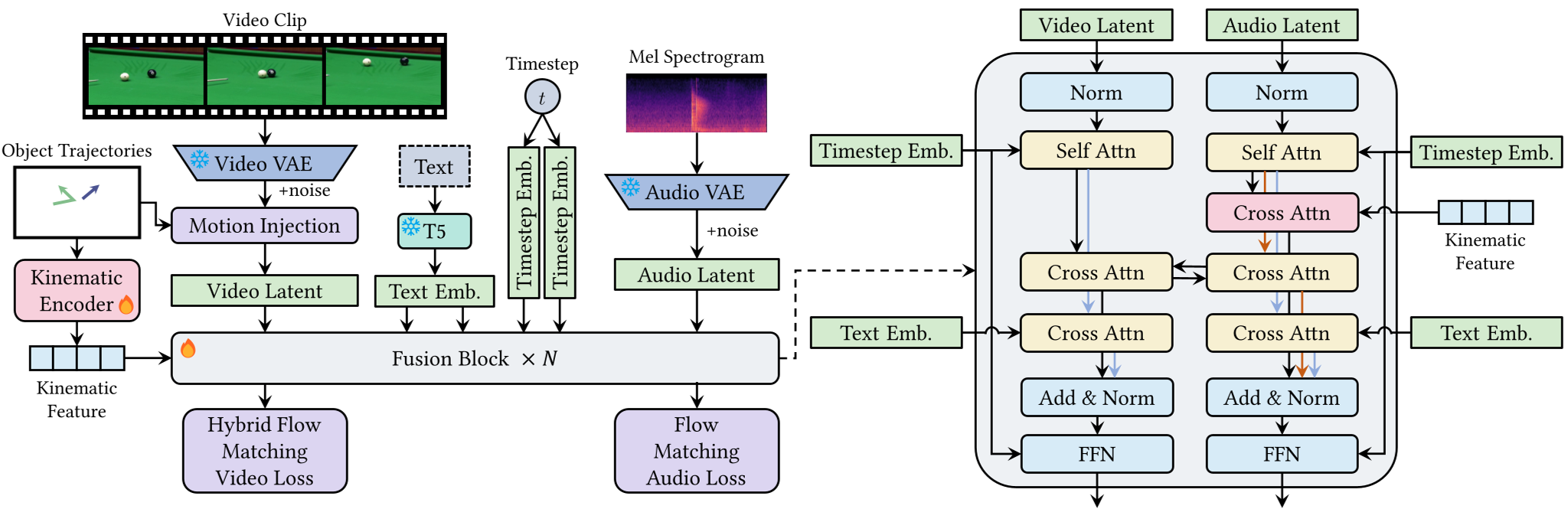
3. 混合流匹配 (Hybrid Flow Matching)
为了防止强制轨迹引导导致背景撕裂,作者设计了双流策略:
- 轨迹区:使用以轨迹 Latent 为终点的概率流,强化运动控制。
- 背景区:维持标准高斯噪声流,保证环境生成的灵活性。
实验战绩:让物理规律在 AI 中“复活”
在多项严苛指标下,Tora3 实现了全面超越:
- 同步性 (FGAS):从 0.156 提升至 0.234。
- 运动忠实度 (TE):误差大幅缩减至 12.13(对比基线的 19.95)。
- 强度相关性 (MAIC):达到了 0.63,显著高于其他模型,这意味着生成的音量变化真正契合了物体运动的快慢。

深度洞察:为什么 Tora3 能赢?
Tora3 的成功在于其对“运动学 (Kinematics)”的深刻理解。它没有试图去学习复杂的刚体动力学(那太难了),而是提取了轨迹中最能决定感知真实性的特征(如二阶导数)。
消融实验(Ablation Study)显示,只在视频或音频单侧使用轨迹,效果都不如双向结合完美。这验证了一个直觉:视听一致性不是事后对齐出来的,而是在生成的起点由同一个运动规律“坍缩”出来的。
局限与未来
尽管表现惊艳,Tora3 目前仍面临一些挑战:
- 材质感知不足:同样的撞击轨迹,金属球和木头球的声音理应不同,目前模型主要依赖文本提示。
- 空间音效:目前的 3D 声场传播(多声道、遮挡等)尚未体现。
总结
Tora3 证明了在生成式 AI 中引入“结构化物理先验”的巨大潜力。对于内容创作者而言,这意味着不仅能像导演一样控制运镜,还能像调音师一样掌控节奏。
本文由资深学术技术主编重构。