TRQA is a novel evaluation suite designed to assess Deep Research Agents (DRAs) on "Total Recall" tasks where answering a single query requires retrieving every relevant document from a large corpus. It leverages an entity-centric framework across three datasets (Wikidata-Wikipedia and a synthetic E-commerce corpus) to provide verifiable, reproducible benchmarks for multi-step reasoning and retrieval.
TL;DR
Deep Research Agents (DRAs) are the latest frontier in AI, promised to act as autonomous investigators. However, the new TRQA (Total Recall Question Answering) benchmark reveals a sobering reality: when a question requires finding all relevant evidence rather than just a few snippets, even the most advanced agents (Search-R1, GPT-5.2) fail. TRQA introduces a verifiable, contamination-resistant framework that separates memorization from true research logic.
The "Needle in a Haystack" is Not Enough
Standard RAG (Retrieval-Augmented Generation) benchmarks usually ask for a specific fact. If an agent finds one document containing that fact, it wins. But real-world research—like market analysis or scientific synthesis—requires Total Recall.
Consider the query: "What is the total revenue of all e-commerce companies founded in 2010 that use AI for logistics?" If your agent finds 9 out of 10 relevant companies, the final sum is wrong. Current benchmarks fail to test this because:
- LLM-as-a-Judge is flaky: Subjective grading of "research reports" isn't reproducible.
- Data Contamination: LLMs "know" the answers to Wikipedia questions from training, masking their inability to actually search.
Methodology: The TRQA Framework
The researchers built TRQA by anchoring unstructured text to structured Knowledge Bases (KB).
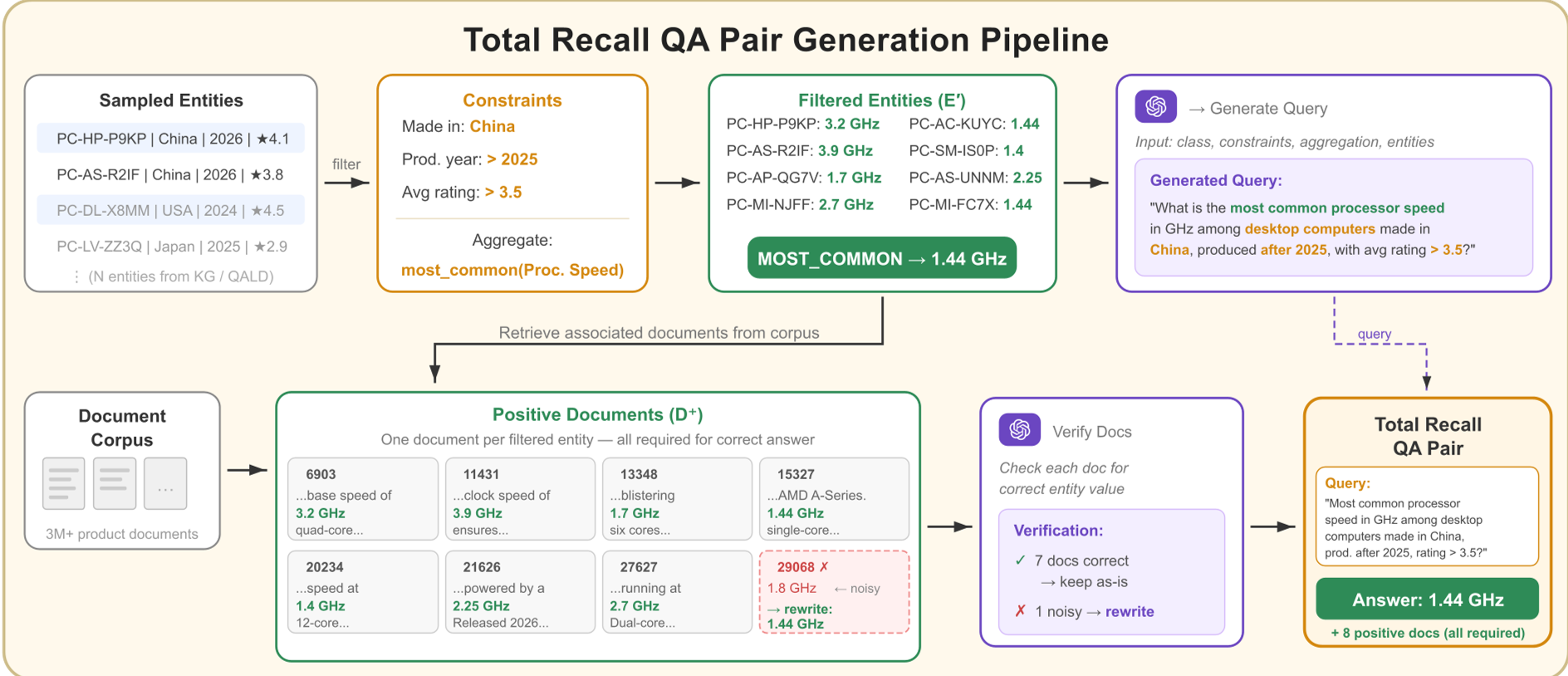
The process is mathematically rigorous:
- Entity Filtering: Use the KB to find a precise set of entities (e.g., all US states with population > 5M).
- Aggregation: Apply an operator (SUM, AVG, COUNT) to a specific property of those entities.
- Verifiability: The result is a single number. No subjective grading required—either the agent got the math right, or it didn't.
To ensure generalizability, they created TRQA-Ecommerce, a completely synthetic world of 476,842 products. Since the LLM has never seen this data during pre-training, it cannot rely on its "gut feeling" or parametric memory.
The Brutal Reality of Benchmark Results
The findings are a wake-up call for the industry. When agents were tested on the synthetic TRQA-Ecommerce dataset, their performance cratered.

Key Insights:
- The Retrieval Trap: Most agents issue 2-3 sub-queries and stop, regardless of how many documents are actually needed. They retrieve more "distracting" (irrelevant) entities the longer they search.
- Reasoning over Recall: Even in the Oracle setting (where the researchers handed the agent all the correct documents), models like Claude 4.5 and GPT-5.2 still failed ~90% of the time due to "reasoning errors." They couldn't accurately synthesize information across a large context window.
- Contamination is Real: Performance on Wikipedia-based tasks was much higher because models already "knew" the answers. The synthetic dataset proved that agents are much worse at "researching" than they appear.
Deep Dive: Where do Agents go Wrong?
The paper categorizes failures into two buckets:
- Parametric Bias: The model ignores the search results and chooses an answer based on its training data.
- Reasoning Failures: The model reads the documents but fails the math or the logic.
Interestingly, 95.9% of Claude's errors were pure reasoning failures. This suggests that expanding the context window (Long Context) is not a silver bullet; models need better "working memory" and symbolic reasoning to aggregate data.
Conclusion and Future Outlook
TRQA provides a much-needed "stress test" for the agentic era. It moves evaluation away from "looking smart" to "being accurate."
Takeaway for Developers: If you are building a research agent, don't just optimize for better embeddings. TRQA shows that the real bottlenecks are iteratively refining search queries to reach 100% recall and robustly aggregating large volumes of numerical data without losing track in the context window.
The code and datasets are open-sourced, providing a new North Star for the next generation of Search-R1 and similar reasoning models.