本文提出了 Total Recall QA (TRQA) 任务及其评估框架,旨在衡量 Deep Research Agents (DRAs) 在处理需要“全量召集”相关信息并进行多步推理的复杂问题时的表现。作者构建了包含三个子数据集的基准测试,涵盖了 Wikipedia 真实数据和合成 e-commerce 数据,并证明了即便在 Oracle 检索条件下,现有最强模型(如 GPT-5.2)仍面临严峻的推理挑战。
TL;DR
如果 AI 告诉你一个结论,你如何确信它看遍了所有相关的资料,而不是仅仅扫了一眼最热门的网页?本文介绍了 TRQA (Total Recall QA),这是一个专门为 Deep Research Agents (DRAs) 设计的硬核评估框架。它抛弃了模糊的 LLM 主观打分,转而使用“数值型聚合问题”来强制模型进行全量信息检索和复杂逻辑推理。结果令人沮丧:即便是最强的推理模型,在面对没见过的新数据时,推理成功率也惨不忍睹。
背景定位:从“搜索引擎”到“研究专家”的横沟
当前的 LLM 智能体正从简单的问答向“深度搜索(Deep Search)”进化。然而,评估这类系统极其困难。现有的 Benchmarks(如 BrowseComp)往往存在以下顽疾:
- 主观性:用 LLM 给 LLM 生成的报告打分,循环论证。
- 暗箱操作:使用动态 Web 搜索,导致实验无法 100% 重现。
- 走捷径:模型可能直接从参数记忆中提取答案,而非通过实时研究。
TRQA 的出现,标志着评估标准从“看起来像那么回事”向“逻辑严密、数据可循”的转变。
痛点深挖:全量召集(Total Recall)的缺失
在深度研究任务中,漏掉一个关键证据可能导致结论完全错误。例如:“所有人口超过 500 万的美国州,其平均失业率是多少?” 如果模型只检索到了 40 个州的信息,它算出的平均值就是错的。这就是 Total Recall 的核心:答案的准确性建立在完整检索所有相关实体的基础上。
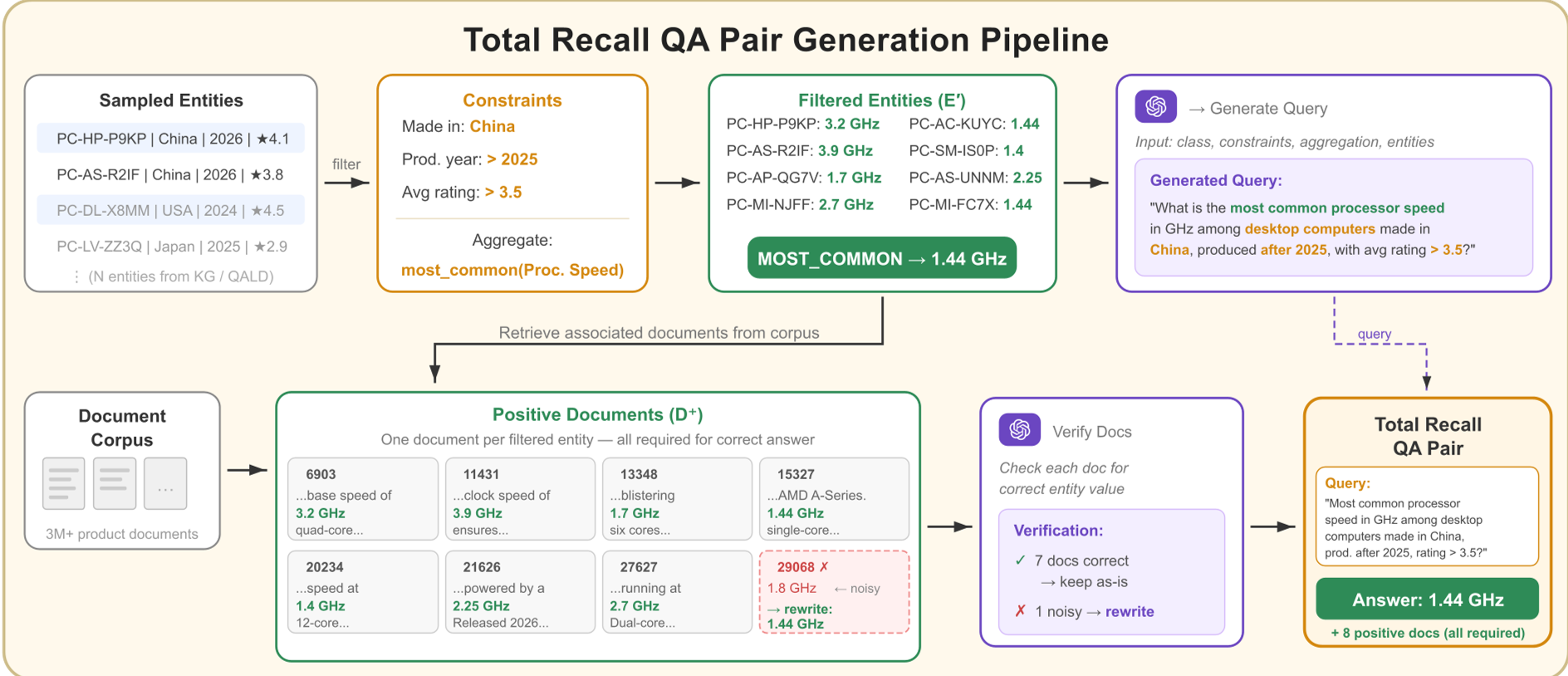
核心方法:构建可验证的“逻辑陷阱”
TRQA 的精妙之处在于它如何生产题目:
- 基于实体中心化 (Entity-Centric):从结构化知识库(如 Wikidata)出发,选定一组满足特定约束(Constraints)的实体。
- 强制性聚合 (Mandatory Aggregation):设计需要对这些实体属性进行求和、求平均或求极值的数学问题。
- 对齐语料库 (Aligned Corpus):将知识库对应到具体的文本段落(如 Wikipedia 列表或合成的电商详情页)。
- 数值化评估:最后通过 Exact Match (EM) 或 Soft Match (SM) 验证答案。这消除了打分歧见——对就是对,错就是错。
为了防止模型“背书”,作者还特意构建了一个 TRQA-Ecommerce 合成数据集,里面充斥着 LLM 训练集中从未出现过的假想产品信息。
实验与结果:揭开“伪深度研究”的面纱
1. 检索性能:目前的模型还很糙
实验对比了 BM25、Contriever 和 BGE 等模型。发现在多步检索任务中,单一检索步骤的 Recall 表现普遍不佳,尤其在复杂约束下,模型很难准确找到所有的“漏网之鱼”。

2. 推理失效:Oracle 模式下的尴尬
这是本论文最惊人的发现:即使研究人员把所有相关的正确文档直接喂到 LLM 嘴边(Oracle Retrieval),模型依然答错。
- 在 TRQA-Ecommerce 数据集上,GPT-5.2 的 Exact Match 准确率仅为 5.56%。
- 错误分析显示,超过 90% 的错误属于“推理错误”(Reasoning Errors),即模型无法从给定的长文本中正确提取并计算数值。

3. 数据污染的遮羞布
当面对 Wikipedia 数据(模型见过)时,性能看似不错;但一旦切换到合成数据(模型没见过),性能瞬间崩塌。这证明了目前的很多 DRA 实际上是在利用“记忆”伪装“推理”。
深度洞察与总结
TRQA 的贡献在于它为 Deep Research 划定了一条严格的防线:真正的智能体必须具备在海量文档中“不漏一人”的检索严谨性,以及在此基础上的“算无遗策”的推理能力。
Takeaways:
- 上下文压力:长上下文窗口并不等于长上下文理解。当需要对数十个片段进行精确聚合计算时,LLM 依旧力不从心。
- 评估闭环:未来 DRA 的优化方向不应只是写出更漂亮的报告,而应是改进其“子查询计划(Sub-query planning)”以提升召回完整性。
- 局限性:目前 TRQA 关注的是数值型答案,未来可以扩展到更复杂的逻辑关系评估。
TRQA 正告所有研究者:在 AI 宣称自己能做“深度研究”之前,先让它跨过这道“全量召集”的门槛。