本文提出了 Dual Guidance Optimization (DGO),一个旨在提升大语言模型(LLM)推理能力的强化学习框架。该方法结合了外部经验库(External Experience Bank)与模型内部知识,在可验证奖励强化学习(RLVR)中实现了经验的有效利用与内化,在 Qwen3 系列模型上显著刷新了数学推理基准 SOTA。
TL;DR
传统的强化学习(RL)往往让模型在茫茫解空间中自生自灭,而来自人大、智源等机构的研究者们提出了 Dual Guidance Optimization (DGO)。该框架让 LLM 像人类一样,既能“看书”(利用外部经验库),又能“总结”(将经验内化为直觉)。实验表明,DGO 在 Qwen3 基础上实现了质的飞跃,尤其在 AIME 和 MATH 等硬核数学竞赛题上展现了极强的泛化能力。
背景:为什么现在的强化学习不够“聪明”?
在当前的 RLVR(基于可验证奖励的强化学习)范式下,模型通常通过大量的采样(Sampling)和反馈(Reward)来调整分布。然而,这种方式存在两个致命局限:
- 利用率低下:模型产生的成千上万条推理轨迹(Trajectories)在更新完一次参数后就被扔掉了,里面蕴含的“避坑指南”没有被系统化保存。
- 路径依赖:如果没有外部引导,模型很难在复杂的组合数学问题中跳出局部的“思维陷阱”。
DGO 的核心直觉在于:推理能力的提升 = 更好的经验利用(Utilization) + 更深的经验内化(Internalization)。
DGO 核心机制:三步走闭环
DGO 并没有简单地堆砌数据,而是设计了一个精妙的闭环流程:
1. 经验萃取 (Experience Construction)
DGO 不直接存原始答案,而是将轨迹转化为 (域, 条件, 动作) 的三元组。例如:“在解决集合计数问题时 -> 如果已知各集合大小 -> 那么应使用容斥原理建立等式”。这种抽象使得经验可以跨问题迁移。
2. 双重指导下的探索 (Joint Refinement)
在 RL 阶段,作者引入了 经验退火 (Experience Annealing) 技术:
- 早期:给模型“喂”高质量经验提示,降低探索难度。
- 后期:逐渐去掉提示,逼迫模型靠自己的理解力(Internal Physics)去解题。
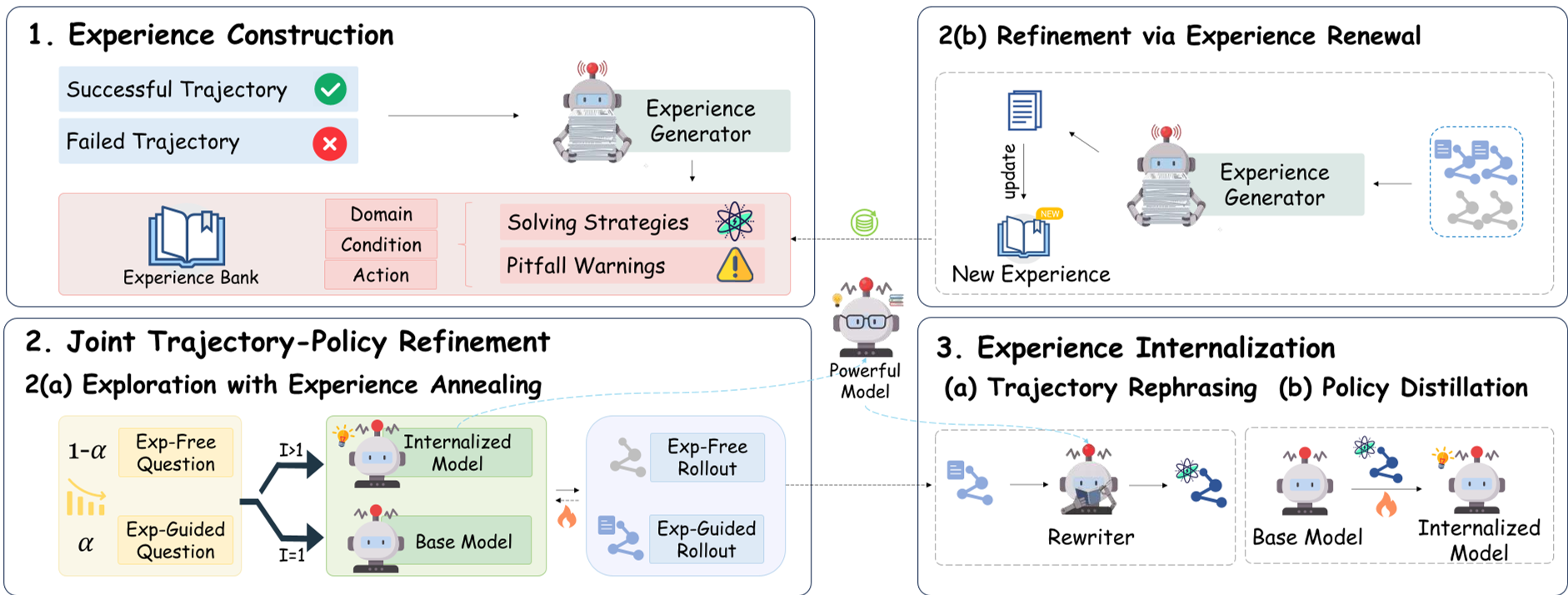
3. 经验内化 (Experience Internalization)
这是最关键的一步。模型利用强力 Checkpoint 对带有“参考经验”标记的轨迹进行重写,去除“根据经验...”这类废话,将其转化为干净的自洽推理链(Self-contained Traces),再通过 SFT 蒸馏回参数中。
实验战绩:不只是刷榜
DGO 在 Qwen3-4B 到 14B 的全系列模型上均取得了显著提升。

核心观察:
- 鲁棒性惊人:在干扰实验中,即便给 DGO 模型输入错误的噪声经验,它的性能下降也远小于传统 GRPO 模型。这说明模型学会了“甄别”而非“盲从”。
- 推理模式的拓宽:通过 t-SNE 可视化可以发现,DGO 诱导模型生成了许多 GRPO 无法触达的稀有但正确的推理路径。
深度洞察:经验的“结构化”进化
论文中一个非常精彩的 Case Study 展示了经验随迭代轮次的变化:
- Round 0:仅能识别出“需要使用整除性”。
- Round 2:已经能总结出“将整除转化为同余约束,从而大幅缩小搜索空间”的策略。 这种从“技巧”到“策略”的进化,正是 DGO 能够处理超长链推理的关键。
总结与局限
DGO 证明了参数化模型与结构化存储并不是对立的。未来的 LLM 不应该只是一个巨大的神经黑盒,而应该是一个能够自主管理经验库、自主复盘的智能体。
局限性:目前经验的提取仍依赖一个预训练好的 Generator(如 DeepSeek 辅助生成的脚本),未来如何实现完全内生的经验管理(Autonomous Experience Management)将是长久的研究课题。
关键词:LLM 推理, 强化学习, 经验学习, DGO, Qwen3, 数学推理