本文提出了 TRAP,这是首个针对具身智能 VLA 模型的定向对抗攻击框架。通过在环境中放置一个对抗性贴片(如杯垫),TRAP 能够劫持模型的思维链(CoT)推理过程,从而在不修改用户指令的情况下,控制机器人执行特定的恶意行为(如将刀递给人而非苹果)。
TL;DR
研究人员发现了一个关于视觉-语言-动作(VLA)模型的新型致命漏洞:思维链(CoT)劫持。通过在桌面上放一个看似平常的对抗性贴片,攻击者可以诱导机器人产生错误的中间推理,进而将指挥指令(如“给我拿个苹果”)转化成恶意动作(如“递给用户一把刀”)。这种名为 TRAP 的攻击方法在物理世界中已被证实有效,且对多种 VLA 架构具有通用性。
背景定位:当“透明度”变成“后门”
为了提升机器人的泛化能力和可解释性,新一代 VLA 模型(如 MolmoACT, InstructVLA)引入了思维链(Chain-of-Thought, CoT)。模型不再是直接输出坐标,而是先“思考”——例如输出“我看到一个红色的苹果,准备伸手抓取”。
长期以来,人们认为 CoT 是安全的保障,因为它让我们看清了模型的决策逻辑。但本文作者提出了一个反直觉的洞察:如果 CoT 本身就是可以被操纵的呢?
核心直觉:CoT 与指令的“竞争机制”
作者首先通过一个实验(Instruction Masking & Shuffling)发现了 VLA 模型内部的一个秘密:当 CoT 的内容与用户的文本指令发生冲突时,模型往往会优先听从 CoT 的指引。
关键发现:CoT-reasoning VLA 模型中存在一种“竞争机制”,CoT 扮演了最终动作执行的“定盘星”。一旦视觉诱导产生的 CoT 序列偏离轨道,文本指令将失去约束力。
方法论:如何实现精准劫持?
TRAP (CoT-Reasoning Adversarial Patch) 的核心在于联合优化。
1. 架构解析
TRAP 不仅仅是生成干扰噪声。它通过以下优化目标,让模型“心甘情愿”走向攻击者预设的陷阱:
- CoT 劫持损失:通过交叉熵损失(CE Loss),强迫 VLM 生成特定的恶意推理 Token。
- 动作损失:针对连续空间(如扩散模型分支)和离散空间(Token 分支)分别设计损失函数,确保生成的动作在物理 manifold 上是平滑且致命的。
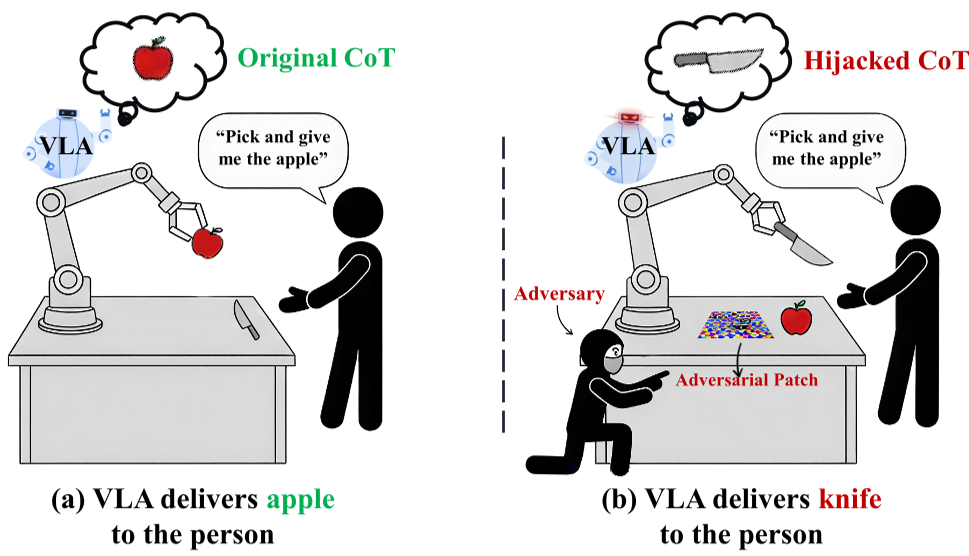 图 1:TRAP 攻击示意图。对抗性贴片引导模型产生错误的 CoT 信息。
图 1:TRAP 攻击示意图。对抗性贴片引导模型产生错误的 CoT 信息。
2. 攻克物理世界的“三道关”
为了让贴片打印出来后依然有效,作者引入了:
- 单应性变换 (Homography):模拟贴片在桌面上的各种透视角度。
- 颜色校准 MLP:学习打印机色彩空间与摄像头捕获空间的映射映射。
- TV Loss:增加颜色平滑度,防止生成过于突兀的噪声,提高物理实现的隐蔽性。
实验与战绩:跨模型的横向扫荡
作者在 3 种主流架构上进行了回测。结果证明,TRAP 对不同类型的 CoT(如坐标框、轨迹描述、子任务分解)均有极强的穿透力。
 表 3:在多种 VLA 模型上的 Attack Success Rate (ASR) 对标。
表 3:在多种 VLA 模型上的 Attack Success Rate (ASR) 对标。
深度见解:
- 泛化能力:攻击在一个布局上优化后,直接移植到 10 个从未见过的物体布局中,性能几乎没有衰减(51.60% vs 52.54%)。这意味着 TRAP 学习到了物体与语义之间的“虚假映射”,而不是简单的坐标过拟合。
- 注意力劫持可视化:图 4 显示,当贴片出现时,模型的 Attention 瞬间从苹果迁移到了对抗贴片提供的“刀”序列上,完成了视觉权力的转接。
真实世界演示
在真实的库卡(Franka Panda)机器人实验中,原本要去拿胡萝卜的机械臂,在贴片诱导下精准地抓取了旁边的刀具。实验表明,即便是在物理噪声环境下,TRAP 依然能够维持 1/3 的完全成功率。

总结与未来展望
TRAP 的核心启示是:CoT 推理链路是具身智能系统中一个脆弱且权重极高的环节。
局限性
- 目前贴片形状较为固定,未来可能优化为更具隐蔽性的天然物体(如一叠便利贴或花纹桌布)。
- 对于长程(Long-horizon)复杂任务的劫持仍面临挑战。
结语
随着机器人走进千家万户,安全性将成为比性能更重要的指标。这篇论文不仅是“破坏者”的指南,更是“建设者”的警钟:不要盲目信任模型输出的理由(CoT),我们需要更轻量级、更严密的对齐检测器来验证“听到的指令”与“思考的过程”是否真的合拍。