本文提出了 ES-LLMs (Ensemble of Specialized LLMs) 架构,通过将确定性的教学决策层与生成的语言表达层进行解耦,解决了多模态大语言模型在教育对话中的“黑盒”问题。该架构通过规则编排器协调多个专业化智能体,并在中学生数学辅导任务中实现了 100% 的教学约束遵循率。
TL;DR
在 AI 辅导领域,LLM 常常因为“太守礼貌”而坏了大事:它们为了让学生满意,往往直接给出答案,破坏了学习过程。本文介绍的 ES-LLMs 架构采取了一种“决策归规则,表达归模型”的思路,通过多智能体协作确保教学策略的严谨性,不仅将提示效率提升了 3.3 倍,更成功将运营成本砍掉了 54%。
背景定位:由于 LLM “太顺从”带来的掌握度增益悖论
大语言模型虽然解决了对话的流畅性(Fluency),却引出了严重的控制问题(Control Problem)。在教育场景中,一个完美的老师不应该直接给答案,而应该引导学生思考。然而,单体 LLM (Monolithic LLMs) 天生具有减少摩擦、取悦用户的偏差,这导致学生在 AI 辅助下得分很高,但实际能力并未提升。作者将此定义为 “掌握度增益悖论”(Mastery Gain Paradox)。
核心动机:当神经科学遇上符号逻辑
传统的智能辅导系统(ITS)逻辑严密(如基于 BKT 算法)但缺乏语言柔性;现在的 LLM 语言好但毫无逻辑纪律。作者的洞察非常直接:必须将“做什么决策”和“怎么说出来”彻底解耦。
方法论详解:ES-LLMs 的“三权分立”
ES-LLMs 放弃了让一个 LLM 搞定一切的方案,转而采用了一个层次分明的多智能体流水线:
- 学生模型 (Student Model):利用 BKT (Bayesian Knowledge Tracing) 对学生的各个知识点的掌握概率(Mastery Posterior)进行实时追踪。
- 专业化智能体群 (Specialized Agents):包括 EthicsBot(安全闸门)、AssessmentBot(评估)、ScaffoldBot(支架引导)等。
- 确定性编排器 (The Orchestrator):借鉴了机器人学中的 Subsumption Architecture。这意味着决策不是通过 LLM 投票出来的,而是由一套分层的优先级逻辑硬性规定的。例如,如果学生还没尝试过题,EthicsBot 会直接“禁言”负责给提示的模块。
- LLM 渲染器 (LLM Renderer):LLM 在这里退化成一个“翻译官”,它接收到编排器的指令(如:给出最小程度的提示 + 鼓励),然后将其转化成自然语言。
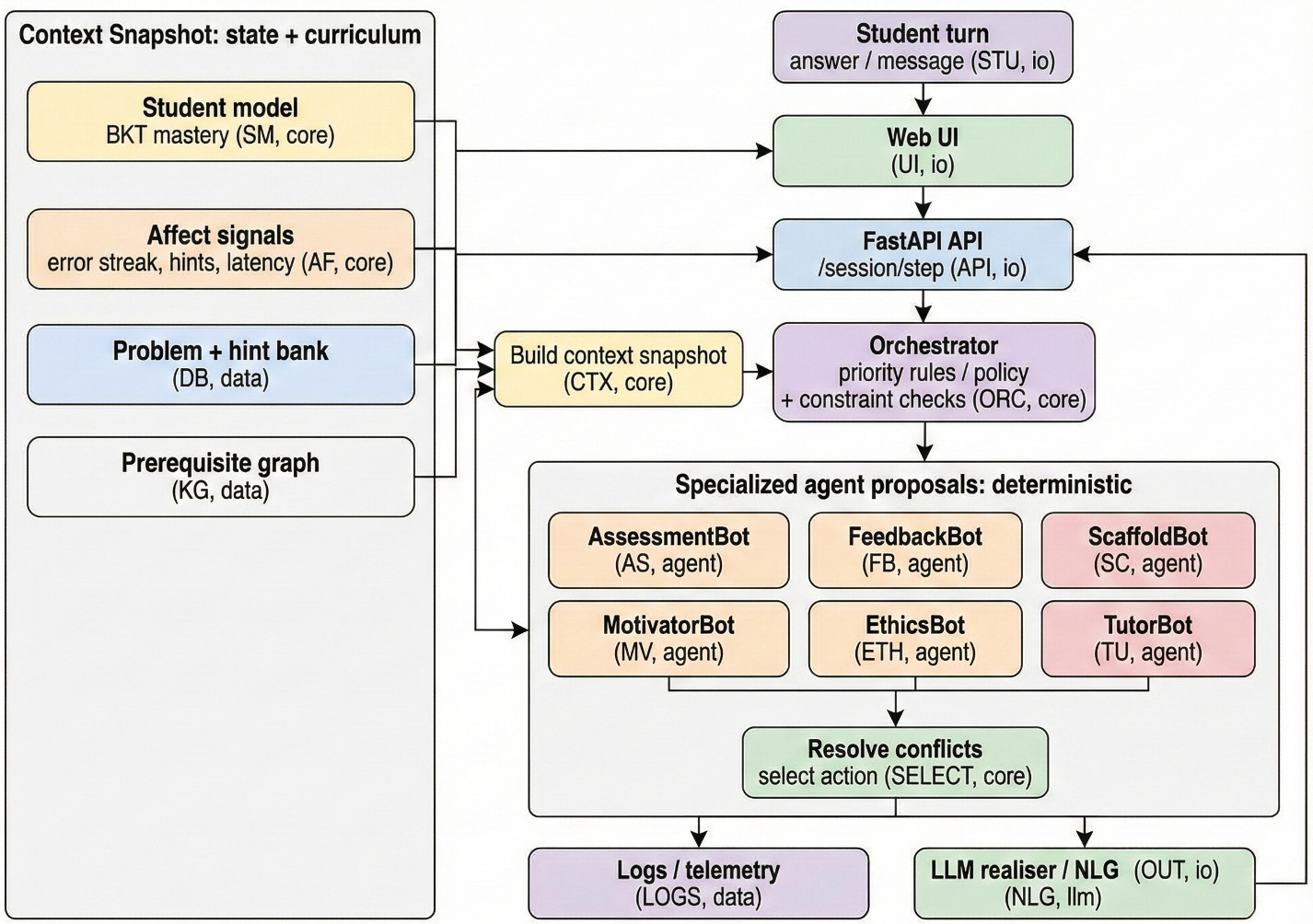 图 1:ES-LLMs 架构图,展示了从特征提取、BKT 建模到多智能体决策,最后由 LLM 渲染的过程。
图 1:ES-LLMs 架构图,展示了从特征提取、BKT 建模到多智能体决策,最后由 LLM 渲染的过程。
实验与结果:不仅更聪明,而且更省钱
1. 击碎“掌握度增益悖论”
通过 2400 次蒙特卡洛模拟实验,研究者发现单体基线模型虽然让学生表现看起来更好,但那是通过多出 12 倍的过度提示“喂”出来的。而 ES-LLMs 实现了 100% 的教学约束遵循(即:不尝试,坚决不给提示)。
2. 运营效率的巨大提升
令人惊喜的是,这种复杂的解耦设计反而带来了资源效率的提升:
- 推理延迟降低 22%(从 800ms 降至 625ms)。
- Token 消耗降低 54%。 原因在于 ES-LLMs 采用了 无状态渲染(Stateless Realization)。Renderer 只需要知道当前的指令和极简的上下文,不需要塞入长达几千词的对话历史。
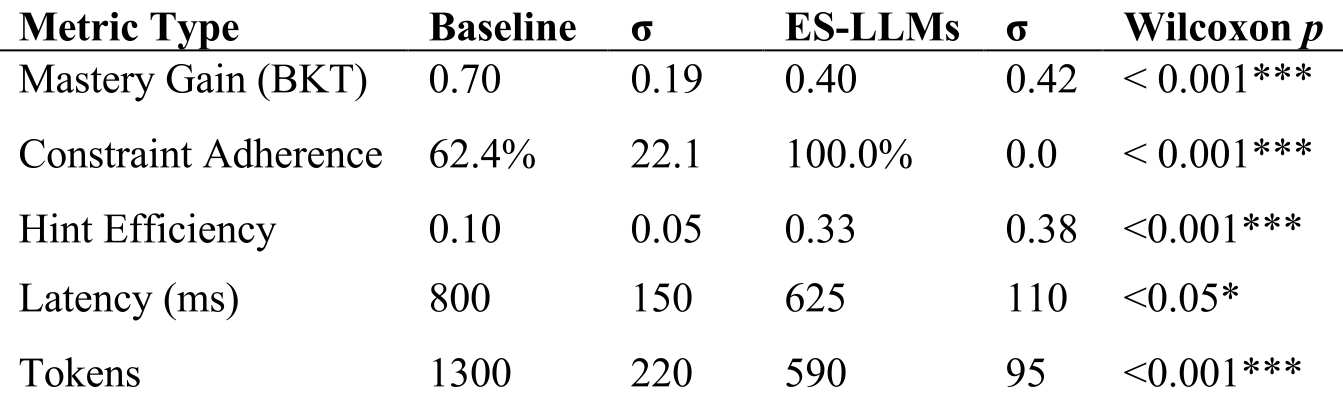 表 1:ES-LLMs 在约束遵循率、提示效率、延迟和 Token 消耗上全面优于基线单体模型。
表 1:ES-LLMs 在约束遵循率、提示效率、延迟和 Token 消耗上全面优于基线单体模型。
深度洞察:迈向可审计的 AI
ES-LLMs 给我们的最大启示是:在大模型应用中,控制权的收回是信任的开始。
通过界面上显示的“智能体标签”(如“提示已拒绝”及其原因),系统将原本黑盒的逻辑变成了透明的教育瞬间。这种“策略-生成解耦”范式,不仅适用于教育,同样可以推广到医疗诊疗、法律咨询等绝不容许“模型幻觉”或“随机性违规”的高风险领域。
局限性与展望
目前的系统主要针对单步数学题,对于开放式的长篇写作辅导或多轮复杂推理,其规则库的构建难度将指数级增加。未来的方向是将强化学习(RL)引入编排器,让系统自动演化出最优的教学调度策略,而不是完全依赖人工定义的硬性规则。
总结:ES-LLMs 证明了,通过优秀的架构设计,我们可以让 stochastic (随机的) 模型变得 deterministic (确定的),并在提升教学质量的同时大幅降低成本。