本文推出了 UW-VOS,首个大规模水下视频对象分割 (VOS) 基准数据集,包含 1,431 个视频和 409 个类别。同时提出了 SAM-U,通过在 SAM2 架构中嵌入轻量化适配器,仅需 2% 的可训练参数即可在水下环境达到 SOTA 性能。
TL;DR
针对水下环境色彩失真和目标伪装带来的视觉挑战,东南大学研究团队发布了 UW-VOS——全球首个大规模水下视频对象分割 (VOS) 数据集。同时,他们基于 SAM2 提出了 SAM-U 架构,通过创新性的 光谱通道门控 (SCG) 机制,仅利用 2% 的参数微调便刷新了水下分割的 SOTA 纪录。
痛点深挖:为什么陆地上的视觉之王在水下会“失明”?
当前的视频对象分割 (VOS) 技术在陆地场景(如 DAVIS, YouTube-VOS)已取得了惊人的准确率。然而,一旦进入水底,问题接踵而至:
- 光谱衰减 (Wavelength-dependent Attenuation):水对红光的吸收极快,导致画面呈现蓝绿色调,物体的色彩对比度丧失。
- 生物伪装 (Camouflage):水下生物进化出了极强的保护色,与背景高度融合。
- 小目标与频繁出入:56.3% 的水下目标属于极小目标(Mask Ratio < 0.01),且鱼类游动轨迹难以预测,经常进出画面边缘导致 identity switch。
现有数据集(如 CoralVOS)往往只关注单一类别(如珊瑚),难以支撑复杂的多目标水下视频任务。
Methodology:SAM-U 的物理直觉
作者认为,不需要从头训练一个重型模型,而是应该“教”现有的视觉基础模型如何看懂水下世界。
1. 架构解析
SAM-U 选择了当前最强的视频分割模型 SAM2 作为骨干,并在其 Hiera 图像编码器中插入了 Underwater Domain Adaptation (UDA) 模块。
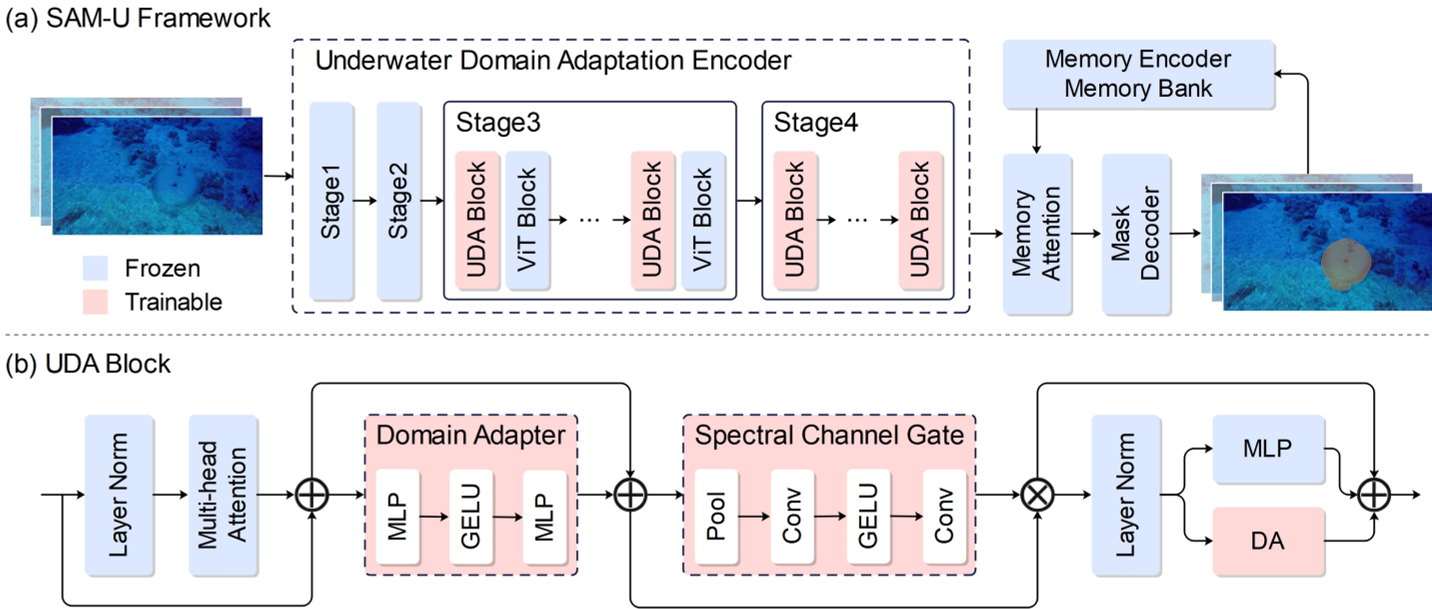
2. 核心模块:针对物理特性的补偿
- Domain Adapter (DA):一种轻量级的瓶颈式 MLP,负责捕捉水下目标的尺度变化。
- Spectral Channel Gate (SCG):这是本文的神来之笔。考虑到水下红、绿、蓝通道衰减不一,SCG 学习一个通道级的缩放因子(Scaling Factor),在特征层面对被削弱的光谱通道进行“补偿”,从而增强对比度。
实验与结果:小参数博取大提升
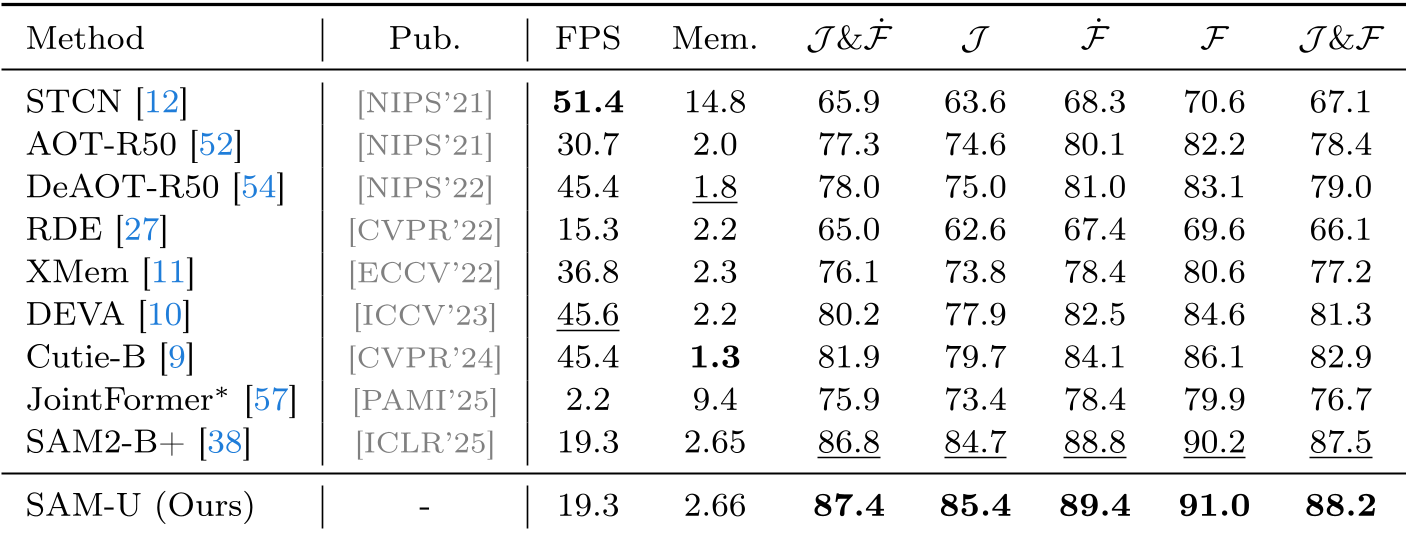
研究团队在 UW-VOS 上对 9 种主流方法进行了 Benchmark 评测。
1. 领域鸿沟的量化
实验数据表明,将陆地预训练模型直接(Zero-shot)用于水下,性能会平均下降 13 个 J&F 点。这证明了水下环境存在严重的 Domain Shift。
2. SOTA 对比
SAM-U 仅通过更新 1.5M 的参数(总量约 2%),就在几乎所有指标上超过了全参数微调(Full Fine-tuning)的 SAM2。
关键发现:在小目标 (ST) 和伪装目标 (CAM) 的消融实验中,SCG 模块的加入显著提升了约 0.7-1.1 个百分点。
深度洞察:未来的航向
UW-VOS 的出现填补了海洋探索中关键的一环。作者通过属性分析指出:伪装目标(Camouflage) 和 目标重入(Exit-re-entry) 依然是当前最难跨越的障碍。即使是 SAM-U,在处理目标完全消失后重现的场景时仍有提升空间。
总结 (Takeaway): 这项工作的真正价值在于证明了:处理极端领域迁移任务时,物理启发的模块设计(如 SCG) 比单纯增加训练数据量更具效率。UW-VOS 不仅仅是一个 Benchmark,它为未来 AUV(自主水下航行器)的鲁棒导航和海洋生物多样性监测提供了底层数据支持。
注:UW-VOS 数据集包含 1,431 视频,409 类别,30.9 万个 Mask 标注,是目前该研究领域规模最大、属性标注最全的数据集。