本文提出了 V-Co,一种通过视觉协同去噪(Visual Co-Denoising)实现像素级扩散模型表征对齐的系统性框架。该方法在 ImageNet-256 上取得了 SOTA 性能,V-Co-H/16 仅需 300 epoch 训练即达到 FID 1.71,显著优于 JiT 等像素空间基线模型。
TL;DR
在生成模型的世界里,潜空间模型(LDMs)凭借 VAE 的压缩能力长期占据统治地位。然而,像素空间扩散模型(Pixel-space Diffusion)近期正在强力回归。本文介绍的 V-Co 为像素空间模型打了一剂强心针:通过引入预训练 DINOv2 特征进行协同去噪(Co-Denoising),并在架构、引导、损失函数和校准四个维度提供了严格验证的“金牌配方”。结果显示,小模型 V-Co-B 即可越级挑战大其两倍的基线模型,刷新了像素生成的效果上限。
痛点深挖:为什么像素生成总是“差点意思”?
传统的像素空间扩散模型(如 JiT)直接在原始像素上进行去噪。虽然避开了 VAE 带来的重构伪影和瓶颈,但它面临一个本质困难:像素损失无法显式捕捉高层语义结构。这导致模型在学习“猫的轮廓”或“复杂的纹理逻辑”时极其低效。
虽然之前有研究尝试用预训练模型做监督(如 REPA),但如何将这些高层特征深度整合进采样轨迹,而非仅仅作为训练时的旁路约束,一直是领域内的未解之谜。
核心方法论:V-Co 的四大金牌配方
作者通过一套严谨的消融实验,剥离了所有干扰项,总结出协同去噪的四大核心:
1. 全双流架构(Fully Dual-stream Architecture)
研究发现,简单的特征融合(如相加或通道拼接)会限制模型的表达能力。V-Co 采用了全双流架构:像素流和语义流拥有各自的 Norm、MLP 和 Attention 投影,但通过联合自注意力(Joint Self-attention)进行交互。这种设计允许模型在保留各自特征特性的同时,动态决定交互的时机。
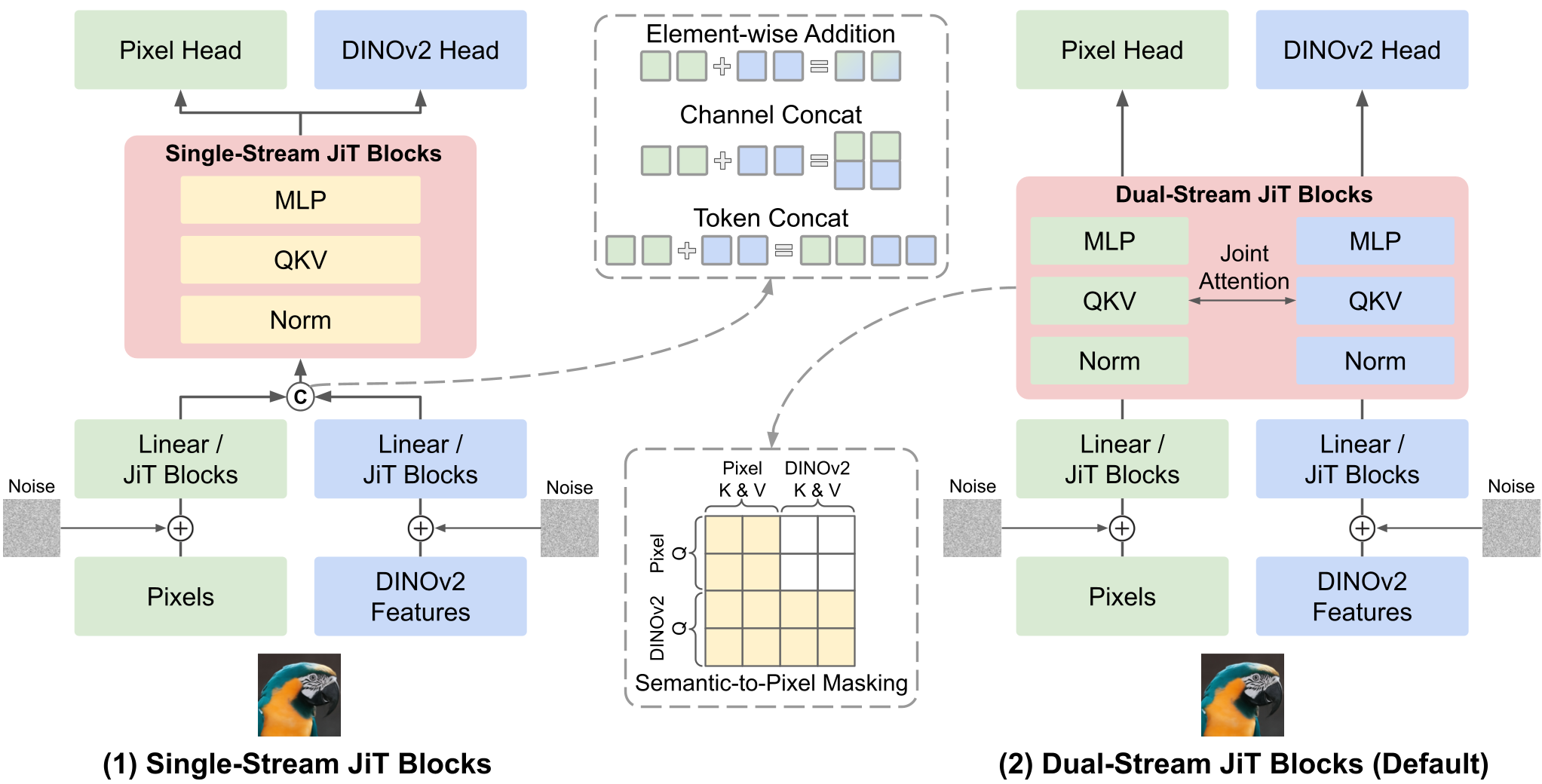
2. 结构化遮蔽 CFG(Structural Masking for CFG)
这是本文的一个神来之笔。在进行分类器自由引导(CFG)时,定义“无条件预测”至关重要。V-Co 抛弃了传统的输入置零,而是直接在 Attention 层实施语义到像素的遮蔽(Semantic-to-pixel Masking)。这意味着在无条件路径下,像素流完全看不见语义流的信息,从而产生最纯粹的无条件预测方向。
3. 感知-漂移混合损失(Perceptual-drifting Hybrid Loss)
单纯的均方误差(MSE)对齐可能导致模式崩塌。作者结合了两种力量:
- 感知力:拉近生成样本与地面真值(GT)的特征距离。
- 漂移力:利用排斥机制防止生成的特征堆积在某些区域,通过类内排斥增强分布覆盖度。
4. RMS 特征校准
像素和 DINOv2 特征位于完全不同的流形空间。V-Co 提出了一种极其简单但有效的物理直觉:通过 RMS(均方根)缩放 使两个流的信号强度匹配。数学上,这等同于动态调整了两个流的去噪信噪比(SNR),确保它们在相同的步数内以相似的难度进行优化。
实验与结果:小参数的“降维打击”
实验在 ImageNet-256 上进行。V-Co 展示了恐怖的参数效率:
- 越级挑战:V-Co-B(260M)达到了 FID 2.33,直接追平了参数量接近其两倍的 JiT-L(459M)。
- SOTA 登顶:V-Co-H/16 仅需 300 个 epoch 的训练,便以 1.71 的 FID 刷新了像素级扩散模型的记录,超越了 2B 参数规模的 JiT-G。

深度洞察与总结
V-Co 的成功证明了:像素级生成模型并不弱,弱的是对高层语义的整合方式。 本文通过一套干净的消融实验,告诉我们不需要复杂的模块,只需对 Attention 进行结构化遮蔽,对特征进行简单的 RMS 校准,并引入分布级的正则化损失,就能让像素空间扩散模型焕发第二春。
尽管目前仍依赖像 DINOv2 这样的外部编码器,但 V-Co 为未来的端到端多模态对齐生成(如 Text-to-Image)树立了一个极具参考价值的基准。对于追求生成质量且受够了 VAE 模糊感的开发者来说,V-Co 无疑是目前最值得尝试的方向之一。
本文由资深学术技术主编重构。