本文提出了 V-Dreamer,一个全自动化的机器人操作数据合成框架。该框架通过整合大语言模型(LLM)、3D 生成模型和视频生成模型(Video Diffusion),直接从自然语言指令生成可用于仿真的 3D 场景及对应的专家操作轨迹。
TL;DR
数据匮乏一直是通用机器人发展的瓶颈。来自南京大学、复旦大学等机构的研究者提出了 V-Dreamer,这是首个全自动、全周期的机器人数据合成流水线。它能将一句简单的指令(如“把那个赛博朋克风格的杯子放到木盘里”)转化为完整的 3D 仿真环境和可执行的专家级机械臂轨迹,且无需任何人工干预。
核心亮点:
- 全自动化:从 LLM 语义拆解到 3D 建模,再到动作生成,全程闭环。
- 视频先验:利用视频生成模型作为“物理直觉”库,通过像素追踪还原 3D 动作。
- 零样本迁移:在纯合成数据上训练的模型,可直接部署到真实硬件。
痛点深挖:为什么机器人还是“书呆子”?
传统机器人学习(Imitation Learning)依赖于人类示教。但这存在两个致命问题:
- Scale 不上去:雇人演示 10,000 次操作既贵又慢。
- 场景僵化:现有的仿真系统(如 RoboGen)虽然能随机生成任务,但通常只能在有限的物体库里折腾。当你换一个从未见过的、形状古怪的瓶子时,机器人往往就“罢工”了。
V-Dreamer 的直觉很简单:既然视频生成模型(如 Sora 级别模型)已经见过互联网上几乎所有的物理运动,我们能不能把这些“视频梦境”转化为真实的控制逻辑?
核心方法论:从“梦境”到“现实”的三个步骤
V-Dreamer 并不是简单地拼凑模型,它构建了一个逻辑严密的**视觉-运动学对齐(Visual-Kinematic Alignment)**框架。
1. 语义到物理的场景合成 (Semantic-to-Physics)
首先,LLM 根据指令规划出资产清单,利用 Flux 生成 2D 资产,再将其提升为 3D Mesh。为了保证稳定性,系统内置了物理引擎(Genesis),通过物理验证(Collision Checking)和重力平齐,确保生成的场景符合客观规律,而不是“飘”在空中的。
2. 基于视频先验的轨迹生成 (Video-Prior-Based Trajectory)
这是最令人惊叹的部分。研究者给视频模型(Wan2.2)输入一张初始场景图,让它“脑补”出操作过程。为了解决视频中常见的“物体变形”顽疾,他们引入了负向提示词(Negative Prompting),强制模型保持刚体动力学。
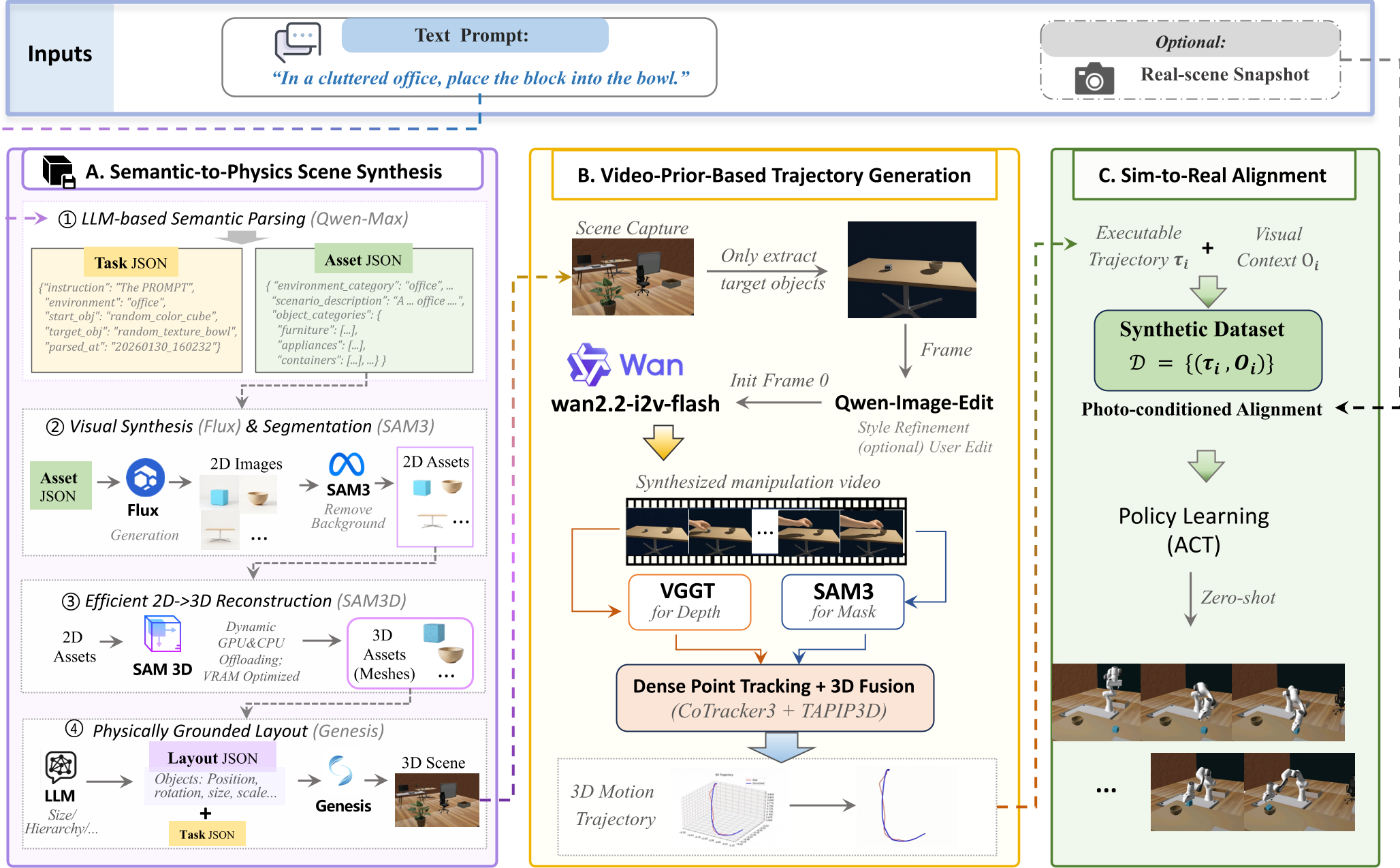
3. Sim-to-Gen 视觉-运动学对齐
生成的视频只是像素。V-Dreamer 利用 CoTracker3 进行像素级追踪,配合 VGGT 进行度量深度估计,将 2D 的像素位移“还原”成 3D 空间中的末端执行器路径点。
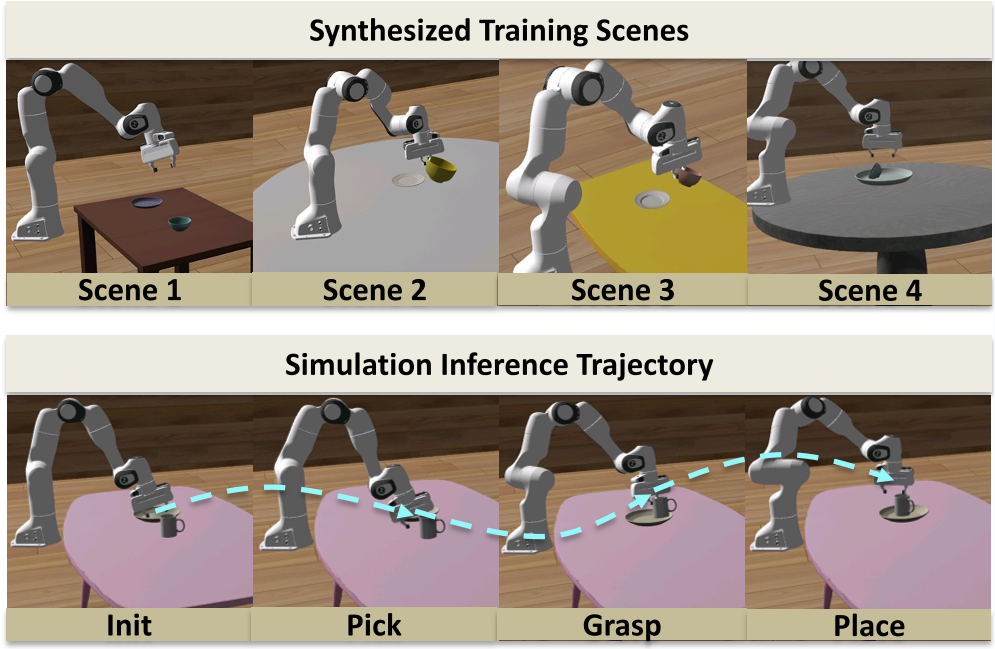
实验与战绩:2500 条数据带来的质变
实验结果验证了 V-Dreamer 作为“高通量数据引擎”的潜力。在 8 张 RTX 4090 的加持下,它每小时能吐出 600 条高质量轨迹。
- 数据量效应:实验证明,随着合成轨迹从 500 增加到 2500,机器人在未见目标上的成功率从 3.46% 飙升至 36.96%。这证明了合成数据的多样性确实缓解了长尾分布问题。
- Sim-to-Real 的优雅:通过 Photo-conditioned 机制(通过真实照片反向构建仿真场景),即使只在合成数据上训练,机器人也能在现实中成功抓取苹果、磁带卷和梨。
深度洞察与总结
局限性 (Limitations): 目前 V-Dreamer 主要处理刚体(Rigid-body)操作。对于毛巾等可变形物体,视频生成的一致性依然面临挑战,且目前对轨迹的“质量筛选”还不够智能化。
未来展望 (Future Work): V-Dreamer 开启了机器人学习的新路径:从“以人为中心”的示教转向“以基础模型为中心”的蒸馏。当视频模型理解了世界的物理逻辑,我们就不再需要昂贵的真实数据,而是让机器人在数以亿计生成的“梦境”中自我迭代。
Takeaway:未来的机器人不需要被“手把手”教,它们只需要多“看”生成视频,并把视觉运动对齐到自己的关节上。