本文推出了 V-JEPA 2.1,这是一个自监督视觉表示学习模型系列,旨在同时获得高质量的密集局部特征(Dense Features)和强大的全局语义理解。通过引入密集预测损失和深层自监督机制,V-JEPA 2.1 在单目深度估计、动作预测(Ego4D/EPIC-KITCHENS)以及视频动作识别(Something-Something-v2)等多个任务上刷新了 SOTA 记录。
TL;DR
Meta FAIR 团队发布的 V-JEPA 2.1 标志着 Joint-Embedding Predictive Architecture (JEPA) 架构的一次重大进化。通过创新的密集预测损失(Dense Predictive Loss)和深层自监督(Deep Self-Supervision),该模型解决了视频 SSL 长期以来“全局强、局部弱”的痛点。它不仅在动作识别等全局任务上保持领先,更在深度估计、物体追踪和机器人操作等需要精密空间感知的密集任务中展现出卓越的性能。
痛点深挖:为什么之前的 V-JEPA “看不清”局部?
在早期的 V-JEPA 2 框架中,模型被要求根据可见的上下文(Context)去预测被遮盖(Masked)区域的特征。
- 物理直觉的缺失:由于 Loss 仅挂在 Masked 区域,模型会产生一种“捷径主义”——Context Tokens 逐渐演化成了类似
[CLS]的全局聚合器,只关心能帮它完成预测的全局信息,而忽略了 Token 自身的空间物理结构。 - 结果:当你用 PCA 可视化特征图时,会发现 V-JEPA 2 的特征图支离破碎(见下文图1左侧),无法通过简单的线性层提取出干净的物体边界或深度信息。
核心方法论:从局部预测到全量接地
V-JEPA 2.1 的重构建立在“预测每一个 Token”的直觉之上。
1. 密集预测损失 (Dense Predictive Loss)
作者提出,不仅要预测 Masked Token,还要预测那些可见的 Context Token。为了防止模型简单的“抄袭”输入,他们设计了一种基于距离的加权方案: $$ \lambda_i = \frac{\lambda}{\sqrt{d_{min}(i, M)}} $$ 其中距离被屏蔽区域越近的 Context Token,其 Loss 权重越高。这种设计强制模型在整个空间域内保持特征的连续性和空间 grounding。
2. 架构拓扑:多级预测器
V-JEPA 2.1 不再只盯着 Encoder 的最后一层。它提取了 Encoder 不同深度的特征,并通过一个轻量级的 MLP 进行融合。
- 直觉:局部几何信息(如纹理、边缘)通常存在于浅层,而语义信息存在于深层。深层自监督迫使这些信息在网络流转中得以保留。
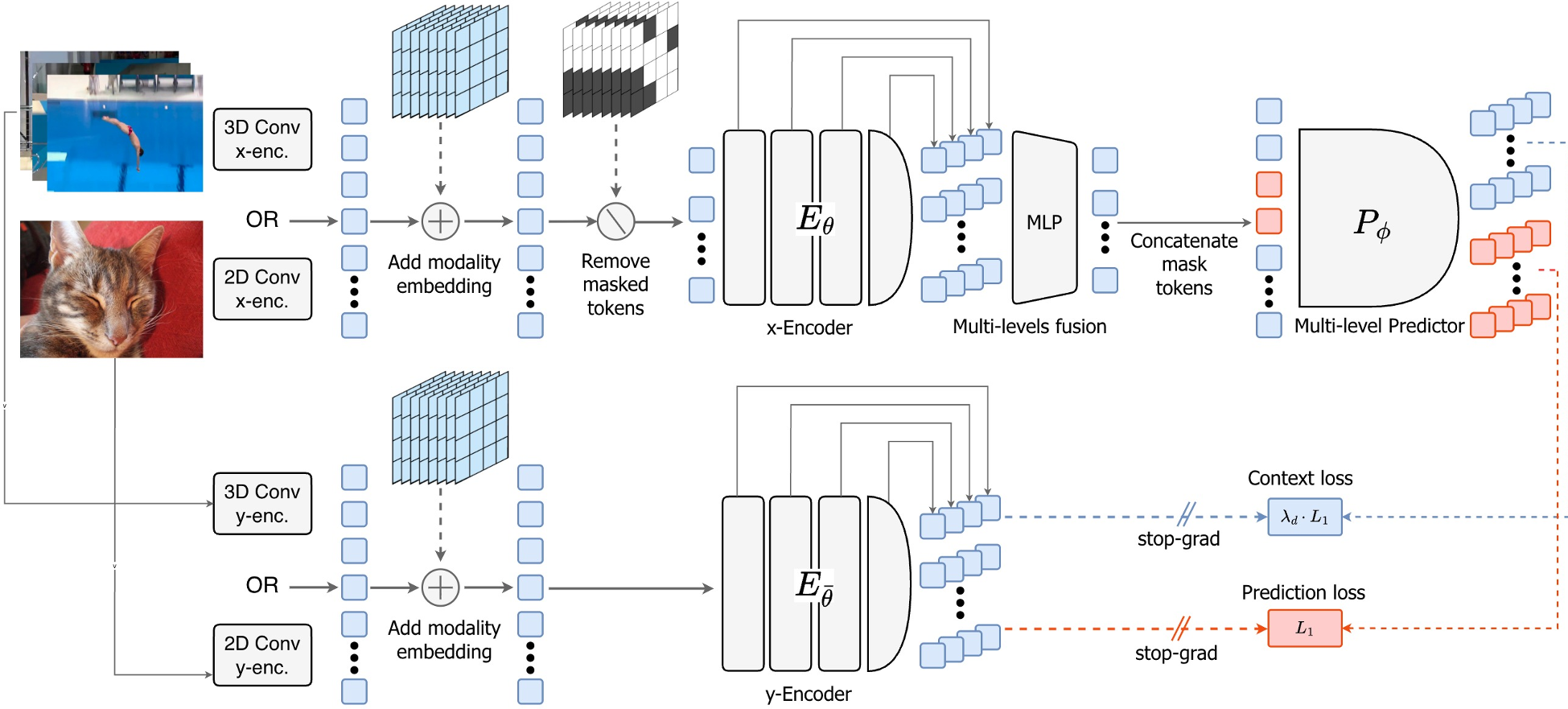 图1:V-JEPA 2.1 架构。可见其特有的多层级特征提取与密集预测路径。
图1:V-JEPA 2.1 架构。可见其特有的多层级特征提取与密集预测路径。
实验战绩:全方位的 SOTA 霸榜
密集视觉任务 (Dense Vision Tasks)
在 monocular depth estimation(单目深度估计)任务中,V-JEPA 2.1 在 NYUv2 数据集上跑出了 0.307 RMSE 的惊人成绩。
- 意义:作为一个视频预训练模型,其深度感知能力甚至超越了专门为图像设计的 DINO 系列模型。
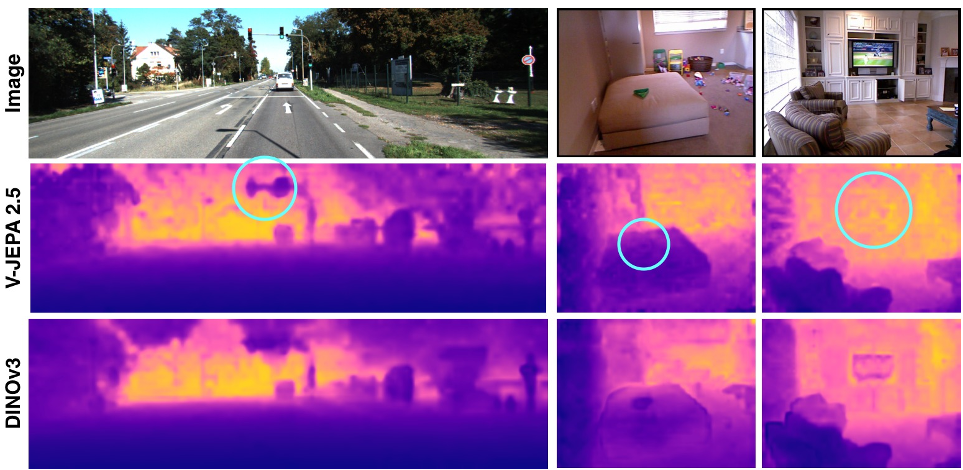 图2:深度估计定性对比。V-JEPA 2.1 能够精准还原红绿灯轮廓等极致细节,而 DINOv3 在尺度一致性上稍逊一筹。
图2:深度估计定性对比。V-JEPA 2.1 能够精准还原红绿灯轮廓等极致细节,而 DINOv3 在尺度一致性上稍逊一筹。
预测与具身智能 (Forecasting & Robotics)
V-JEPA 2.1 的核心价值在于其“世界模型”属性。
- 短期动作预测 (STA):在 Ego4D 数据集上,预测人手下一秒会去碰什么物体、做什么动作。mAP 提升至 7.71,相对提升 35%。
- 机器人抓取:在真实 Franka 机械臂上的 Zero-shot 实验显示,更强的深度理解力直接带来了 20% 的抓取成功率提升。
深度洞察:走向物理世界模型
V-JEPA 2.1 的成功证明了一个观点:SSL 的目标不应仅仅是压缩语义,更应当是对物理环境的模拟。
通过视觉化的 PCA 分量映射(图3),我们可以清晰看到:在视频流中,即使物体发生形变或遮挡,其特征标识(颜色)在时空中保持了极高的一致性。这种“特征稳定性”正是自动驾驶和精密机器人操作所梦寐以求的。
 图3:多场景特征 PCA 可视化。颜色的一致性代表了语义和空间结构的稳定性。
图3:多场景特征 PCA 可视化。颜色的一致性代表了语义和空间结构的稳定性。
局限性与未来展望
尽管 V-JEPA 2.1 在密集任务上表现优异,但在极其复杂、物体密集的 Cityscapes 场景中,其分割精度仍略逊于最顶尖的图像模型。这可能暗示了现有的视频数据集(如 YT-1B)在复杂场景的细节丰富度上仍有提升空间。
未来,将这种密集预测能力与更大规模的 LLM 结合,并引入更长时序的预测(如 8 步以上的长航向规划),将是通向 L5 级自动驾驶或通用家庭机器人的必经之路。