本文提出了 VAMPO,一种通过策略优化增强视频动作模型(Video Action Models)视觉动力学精度的后训练框架。该方法将多步去噪建模为顺序决策过程,并利用 GRPO 算法在隐空间优化视觉动力学,显著提升了机器人操控任务的成功率。
TL;DR
在机器人控制领域,视频动作模型(Video Action Models)正成为构建视觉-语言-动作(VLA)系统的新基石。然而,传统的视频模型往往“空有其表”——能生成看起来合理的画面,但在位姿、接触点等物理动力学细节上存在偏差。本文提出的 VAMPO 框架,通过强化学习中的 GRPO 算法对视频模型进行后训练,将去噪过程视为策略优化问题,显著增强了模型对精准视觉动力学的捕捉能力,让机器人从“看懂”进化到“精准预判”。
痛点深挖:似然目标的“美丽误会”
目前的视频动作模型通常分为视频预测模型(VPM)和动作生成模型(AGM)。VPM 负责“想象”未来,AGM 负责依据想象执行动作。
然而,基于扩散模型的 VPM 在训练时通常采用类似 ELBO (Evidence Lower Bound) 的似然代理目标。这种目标函数更关注数据分布的整体拟合,而非控制任务中的关键精度指标。例如:
- 物体位姿的几毫米偏差;
- 抓夹与物体接触的精确一帧;
- 遮挡关系中的细微空间变化。
对于 AGM 来说,这些“微小误差”在决策边界处会被放大,导致机器人抓空、碰撞或时机不当。
核心机制:去噪过程即策略优化
VAMPO 的核心直觉是:将多步去噪看作一个顺序决策过程(Sequential Decision Process)。
1. 从 ODE 采样到 MDP 建模
作者将每一步去噪动作定义为状态转移,并利用专家演示的隐空间表示(Latent Space)作为奖励反馈。为了解决策略梯度估计在确定性去噪(ODE 轨迹)中梯度方差过大的问题,VAMPO 设计了 Euler Hybrid 采样器。
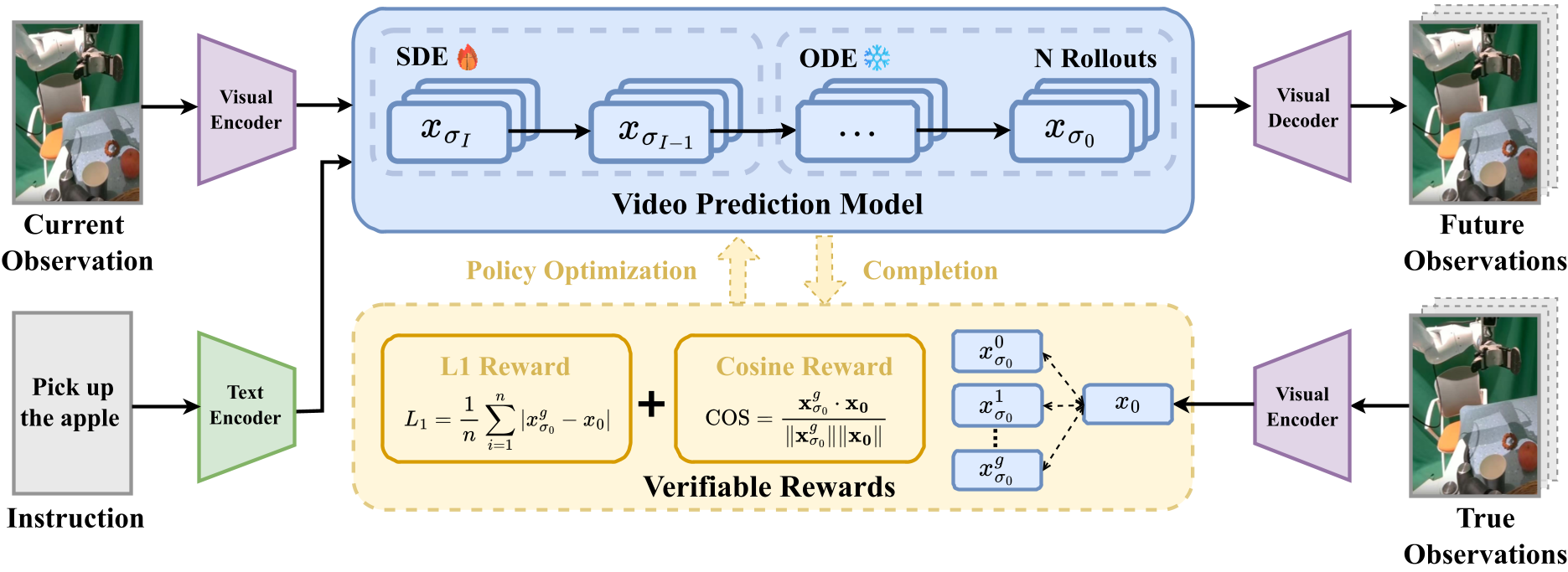 图 1: VAMPO 训练范式概览。左侧展示了从预训练到策略优化的转变。
图 1: VAMPO 训练范式概览。左侧展示了从预训练到策略优化的转变。
- 首步随机化 (1-step SDE):仅在第一步注入高斯噪声,提供必要的探索空间和可计算的概率密度。
- 剩余步确定化 (Remaining Steps ODE):后续步骤保持确定性计算,不仅降低了信用分配(Credit Assignment)的难度,还确保了视频的时序相干性。
2. 引入 GRPO 与可验证奖励
VAMPO 采用了 DeepSeek 等大模型中常用的 GRPO (Group Relative Policy Optimization) 算法。通过对一组候选生成的奖励进行归一化,模型能够更稳定地向“高奖励”轨迹靠拢。奖励函数结合了 L1 距离和余弦相似度,直接在隐空间对齐预测与真实的视觉演化轨迹。
实验与结果:不仅更准,而且更“丰富”
在最具挑战性的 CALVIN ABC→D(跨场景泛化)任务中,VAMPO 刷新了多项记录。
 表 1: 与 SOTA 方法在 CALVIN 环境下的对比,展示了 VAMPO 在长序列任务中的优势。
表 1: 与 SOTA 方法在 CALVIN 环境下的对比,展示了 VAMPO 在长序列任务中的优势。
深度分析:Vision-Action Coupling 作者引入了一个有趣的度量——有效秩 (Effective Rank, ER)。研究发现,经过 VAMPO 优化的模型,其 Jacobian 矩阵(动作/视觉)的有效秩显著提高。这意味着下游的动作生成模型(AGM)在决策时,会考虑更多互相独立的视觉特征维度,即“视觉-动作耦合”变得更加丰富且鲁棒。
现实世界的考验
VAMPO 在 Agibot Genie 01(元化机器人双臂平台)上进行了验证。在“杂乱环境下抓取苹果”和“双臂协作搬运瓶子”任务中,VAMPO 展现了极强的空间推理能力,即使在背景和光照发生变化的现实场景中,依然能生成精准的引导表征。
 图 2: 在真实机器人平台上的任务表现。
图 2: 在真实机器人平台上的任务表现。
深度洞察与总结
VAMPO 的成功在于它精准捕捉到了“预测质量”与“控制质量”之间的鸿沟。
优点:
- 架构无感:无需修改任何 VPM 或 AGM 的模型结构。
- 高效稳定:Hybrid 采样器解决了扩散模型强化学习中常见的训练不稳和计算开销问题。
局限性:
- 奖励函数目前仍依赖于专家演示的隐空间对齐,这限制了其在完全无标注数据上的自我进化能力。
未来展望: 这种将生成式模型作为“策略”进行后训练的思路,可能会推广到更多需要高精度物理推理的领域,如端到端自动驾驶中的轨迹预判。