本文提出了 Vega,一种统一的视觉-语言-世界-动作(Vision-Language-World-Action)模型,旨在实现能够遵循自然语言指令的个性化自动驾驶。通过将扩散模型的生成能力与自回归大语言模型的理解能力相结合,Vega 在 NAVSIM 榜单上取得了 SOTA 的规划性能。
TL;DR
清华大学与 GigaAI 联合推出了 Vega,这是一个能够精准遵循自然语言指令的自动驾驶 VLA 模型。Vega 的核心突破在于不仅能“听懂”指令进行驾驶,还能“预见”未来——它通过统一的 Integrated Transformer 架构,将未来图像生成(World Modeling)与轨迹规划(Action Planning)结合,利用视觉生成的稠密信号解决了传统模仿学习中动作监督稀疏的难题。
背景定位:从“模仿专家”到“听从指令”
目前的自动驾驶模型大多是在模仿人类专家的平均水平,就像是一个只会按固定套路开车的“老司机”。但在现实中,我们往往需要更具灵活性的驾驶:
- “前面有急事,在保证安全的情况下尽量超车。”
- “在那棵树旁边靠边停一下。”
- “在这个路口等红灯变绿后再直行。”
现有的 VLA 模型(如 DriveGPT4, LMDrive)大多只能处理闭集的简单命令,面对这些开放且复杂的个性化需求往往显得力不从心。此外,直接从高维图像映射到简单的坐标点轨迹,存在严重的“信息断层”。Vega 的出现,正是为了补齐这块短板。
核心动机:用“世界模型”填补监督鸿沟
作者认为,模型之所以无法精准执行指令,是因为动作轨迹(Action)的监督信号太单一了。相比之下,预测未来会发生什么(Image Generation) 提供了像素级的、极其丰富的监督信号。这种“看图说话”+“预见未来”的能力,能迫使模型真正理解指令、车辆动作与环境变化之间的因果关系。
技术详解:Vega 的三位一体架构
Vega 并没有简单地堆叠模型,而是采用了一种优雅的 Integrated Transformer 设计:
- 统一序列建模:模型将图像 Token、指令文本 Token 和带噪声的动作/图像 Token 拼接成一个长序列。
- 混合自回归与扩散 (AR-Diffusion):
- 使用自回归(Autoregressive)方式处理视觉和语言的理解。
- 使用扩散(Diffusion)方式生成更加高保真、连续的动作轨迹和未来帧图像。
- Mixture of Transformers (MoT):为了避免不同任务(理解 vs 生成)之间的参数干扰,Vega 引入了 MoT 架构,为不同模态分配专门的 Transformer 权重。
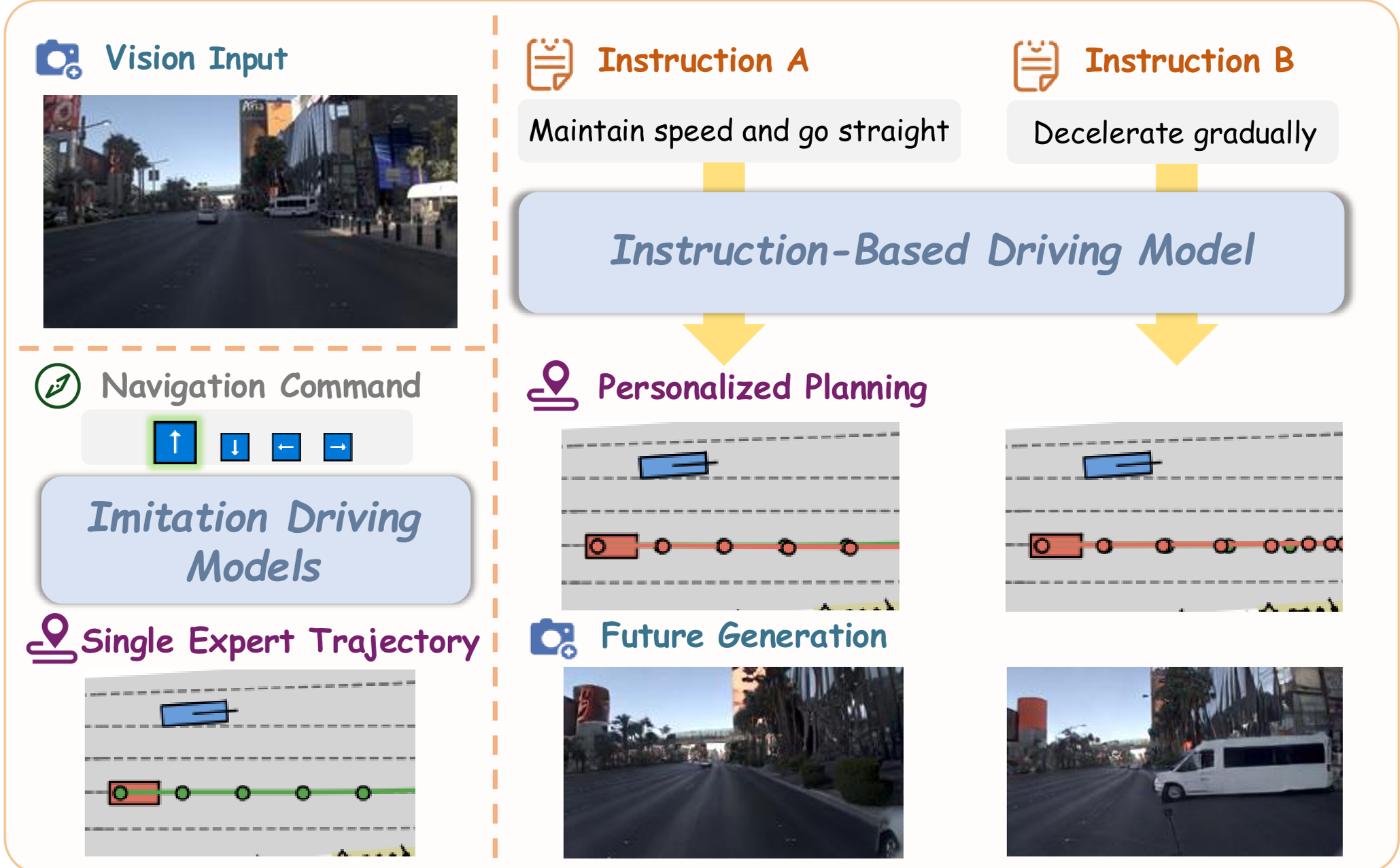
图注:Vega 的统一架构,输入历史图像、动作和当前指令,输出预测的动作序列和未来视觉画面。
实验战绩:NAVISM 榜单的新标杆
Vega 在权威的 NAVSIM 模拟器上进行了详尽测试。
- 量化指标:在 NAVSIM v2 上,Vega 的 EPDMS 得分为 86.9,显著优于传统的 TransFuser 和多模态大模型基线。
- 消融实验:实验(Table 3)显示,如果去掉“预测未来帧”的任务, planning 的得分会大幅下降。这验证了作者的直觉:学习生成未来,真的能帮模型学好规划。

图注:Vega 在不同指标(碰撞率、舒适度、进度等)上均展现出了均衡且优异的表现。
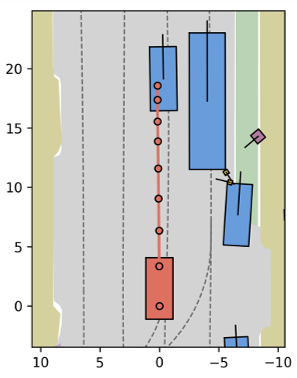
定性观察:它真的听懂了吗?
博文中展示了多个有趣的 Case(见图 5 和图 6)。例如,在同一个十字路口,如果你给它指令“减速停车”,Vega 预测的轨迹会明显缩短,且生成的未来图像中车辆保持静止;如果你说“稳行跟车”,它则会生成平滑的向前移动轨迹。这种指令-动作-视觉的高度一致性,标志着 VLA 模型在自动驾驶领域的进化。
深度洞察与展望
Vega 的成功揭示了未来自动驾驶的一个核心趋势:端到端模型不再仅仅是输入图像输出动作,而是进化为能够理解世界物理规律的“大驾驶模型(Large Driving Model)”。
局限性:尽管 Vega 表现出色,但目前的推理成本仍然较高(需要多次扩散去噪),此外对于侧向和后方视野的理解仍有提升空间。
启示:对于开发者而言,Vega 提供了一个重要思路——当你觉得模型由于任务太简单(如回归坐标)而导致泛化能力差时,不妨给它增加一个更难的任务(如重建未来像素),这种“降维打击”式的辅助监督往往能带来惊喜。
关键词:#CVPR2026 #自动驾驶 #VLA模型 #世界模型 #扩散模型 #Vega