本文提出了 ViHOI,一种通过 2D 图像视觉先验增强 3D 人机交互(HOI)运动生成的扩散模型框架。该方法利用大语言视觉模型(VLM)提取任务特定的空间和语义先验,在多个基准数据集上达到了 SOTA 性能。
TL;DR
在 3D 人机交互(HOI)生成任务中,仅仅靠“搬箱子”这几个字,AI 很难猜出箱子有多大、手该抓哪。ViHOI 提出了一种创新的即插即用方案:利用 2D 图像作为视觉先验,通过大模型(VLM)提取物体的几何形状和交互逻辑,从而生成物理属性更真实、泛化能力更强的 3D 动作。
背景:文本生成的“信息贫血”
当前的运动生成模型(如 Motion Diffusion Model)主要面临两个瓶颈:
- 语义模糊性:文本注释(如 "pick up a box")缺乏具体的空间细节,导致模型在学习时陷入“一对多”的困境。
- 泛化瓶颈:面对训练集里没见过的物体,单纯靠文字无法重建精准的物理约束,容易出现“穿模”或“物体漂浮”。
为了解决这些问题,华南理工大学的研究团队提出了 ViHOI,其核心直觉是:一张高质量的 2D 交互参考图,胜过千言万语。
核心方法:VLM 驱动的先验提取系统
1. 层解耦策略 (Layer-decoupled Strategy)
作者发现 VLM(如 Qwen2.5-VL)的不同层对信息的敏感度不同:
- 视觉先验 (Visual Prior):从 LLM 的第 3 层提取。这一层保留了更丰富的几何细节和空间线索。
- 语义先验 (Textual Prior):从 LLM 的第 12 层提取。深层特征具有更强的逻辑理解力,确保动作符合文本指令。
2. Q-Former 适配器
提取出的 VLM 特征维度极高且长度不一。作者设计了一个基于 Q-Former 的适配器,通过可学习的 Query 将海量信息压缩成一个紧凑的 Prior Token,直接注入扩散模型的 Self-attention 层。
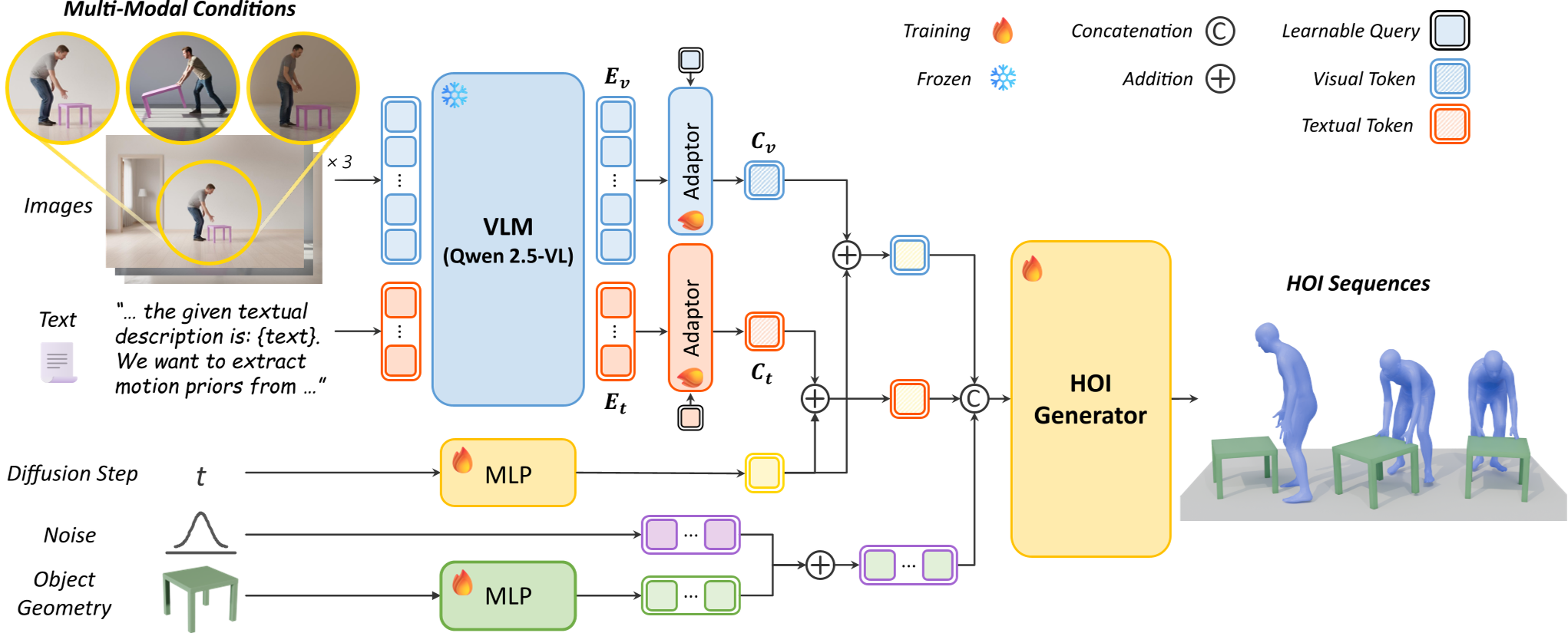 图 1:ViHOI 总架构图。左侧为基于 VLM 的先验提取器,右侧为融入视觉/文本先验的生成器。
图 1:ViHOI 总架构图。左侧为基于 VLM 的先验提取器,右侧为融入视觉/文本先验的生成器。
3. 推理时的“幻影”参考图
在训练时,模型使用 GT 动作渲染的图像;但在推理(Inference)时,用户通常没有图像。ViHOI 巧妙地引入了 T2I 模型(如 Nano Banana),先根据文本生成 2D 交互参考图,再将其输入 VLM。这一步利用了图像生成模型背后的“万物知识”,极大地提升了模型处理新奇物体的能力。
实验与结果:全方位碾压基线
研究团队在 FullBodyManipulation 和 BEHAVE 两个主流数据集上进行了测试:
- 精度跃升:在关键的 MPJPE(平均关节位置误差)指标上,ViHOI 配合 CHOIS 生成器达到了 14.97cm,远超传统方法。
- 物理合理性:接触精度(Cprec)和 F1 分数均有显著提升,有效解决了手部穿模问题。
- 未见物体的“神力”:即使测试集中出现了训练时从未见过的椅子或桌子,ViHOI 依然能保持稳定的生成质量。
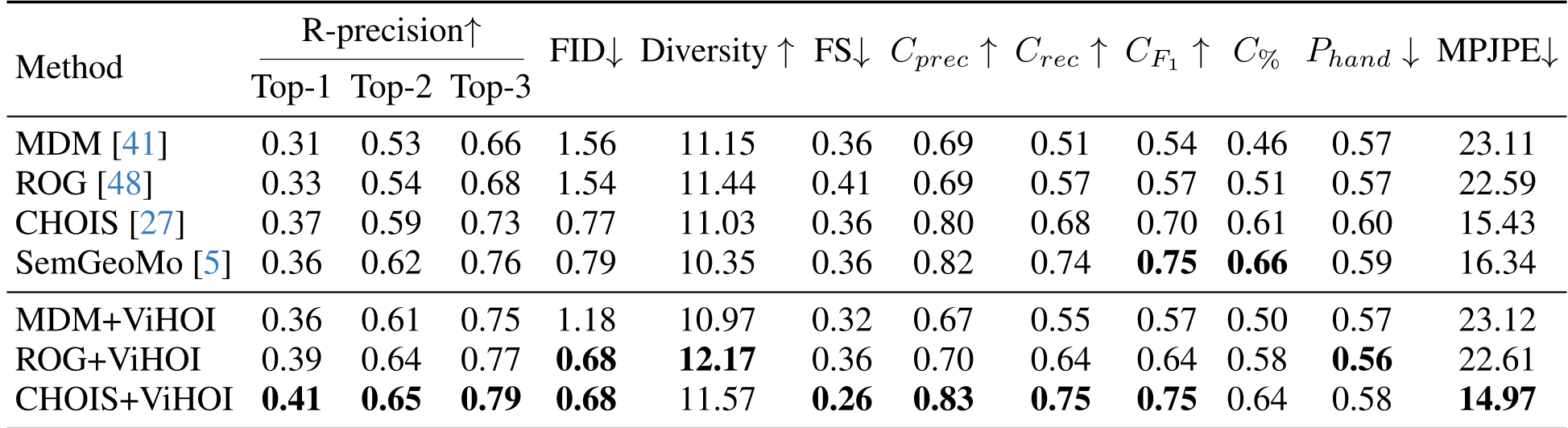 表 1:在不同基准模型上,加入 ViHOI 插件后性能均获得大幅增长,体现了其极强的通用性(Plug-and-play)。
表 1:在不同基准模型上,加入 ViHOI 插件后性能均获得大幅增长,体现了其极强的通用性(Plug-and-play)。
深度洞察
ViHOI 的成功在于它找到了 2D 视觉世界与 3D 动力学之间的“锚点”。它不要求精密的 3D 重建,而是通过 VLM 提取隐式的手-物关系(Affordance)。
局限性分析: 由于当前主流数据集缺乏精细的手指标注,ViHOI 暂时还无法生成极其精细的指尖操作(如弹钢琴或穿针引线)。这需要未来有更高质量的手部采集数据集支持。
总结
ViHOI 为 3D 交互动作生成提供了一个优雅且高效的新思路。它告诉我们,在大模型时代,不同模态之间的能量是可以相互转换的——通过 2D 图像的“看”,AI 终于学会了 3D 物理世界的“动”。
Takeaway: 视觉先验是解决机器人操作和虚拟数字人交互任务中“物理约束”难题的金钥匙。