本文提出了 Video-CoE,一个专为视频事件预测(VEP)设计的 Chain of Events 范式。通过构建细粒度的时序事件链并结合两阶段训练(CoE-SFT 和 CoE-GRPO),在 FutureBench 和 AVEP 等基准测试中超越了 GPT-4o 和 Qwen2.5-VL-72B,刷新了 SOTA 纪录。
TL;DR
预测视频中下一步会发生什么是计算机视觉的圣杯任务。阿里巴巴 AMAP 团队发现,即便最强的 MLLM(如 GPT-4o)在视频事件预测(VEP)上也经常“翻车”。本文提出的 Video-CoE (Chain of Events) 范式,通过强制模型先梳理事件线索再做预测,配合创新的强化学习奖励机制,让模型不再瞎猜,预测准确率暴涨 20% 以上。
1. 痛点:为什么 MLLM 是“近视眼”且“爱走捷径”?
在自动驾驶、安防预警等场景中,Video Event Prediction (VEP) 至关重要。但作者通过对 Qwen, Kimi, GPT 等主流模型的系统评估发现,MLLM 在此任务上表现糟糕,原因有二:
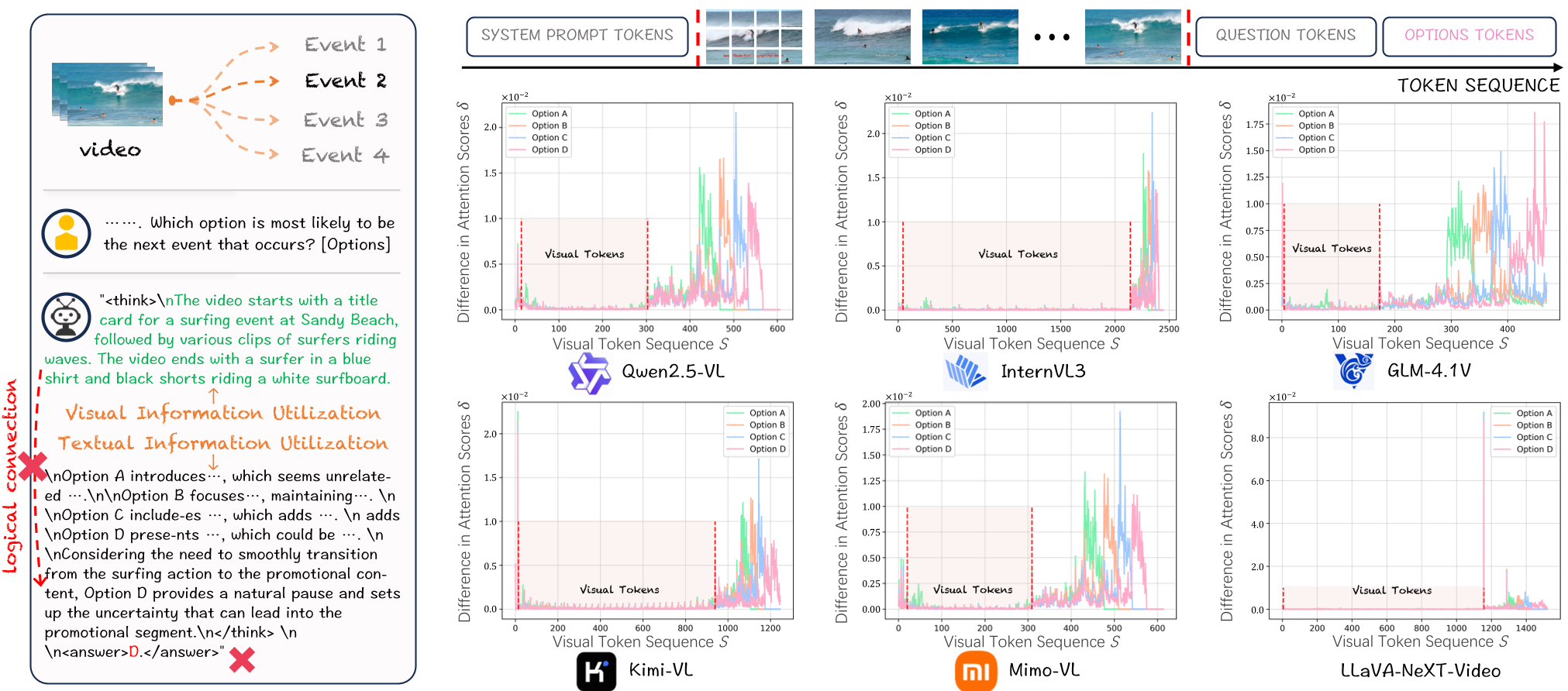
- 视觉冷落 (Visual Bias):实验证明,模型在做选择时,对视觉 Token 的注意力权重远低于文本 Token。相比理解视频,它们更喜欢从题目文字中寻找“听起来合理”的答案。
- 因果断层:现有的 SFT 数据(如选项分析)没有教会模型如何建立“当前观测”到“未见未来”之间的逻辑链路。
2. Methodology:打造“事件链”逻辑
为了解决上述问题,Video-CoE 引入了 Chain of Events (CoE) 范式。
核心直觉
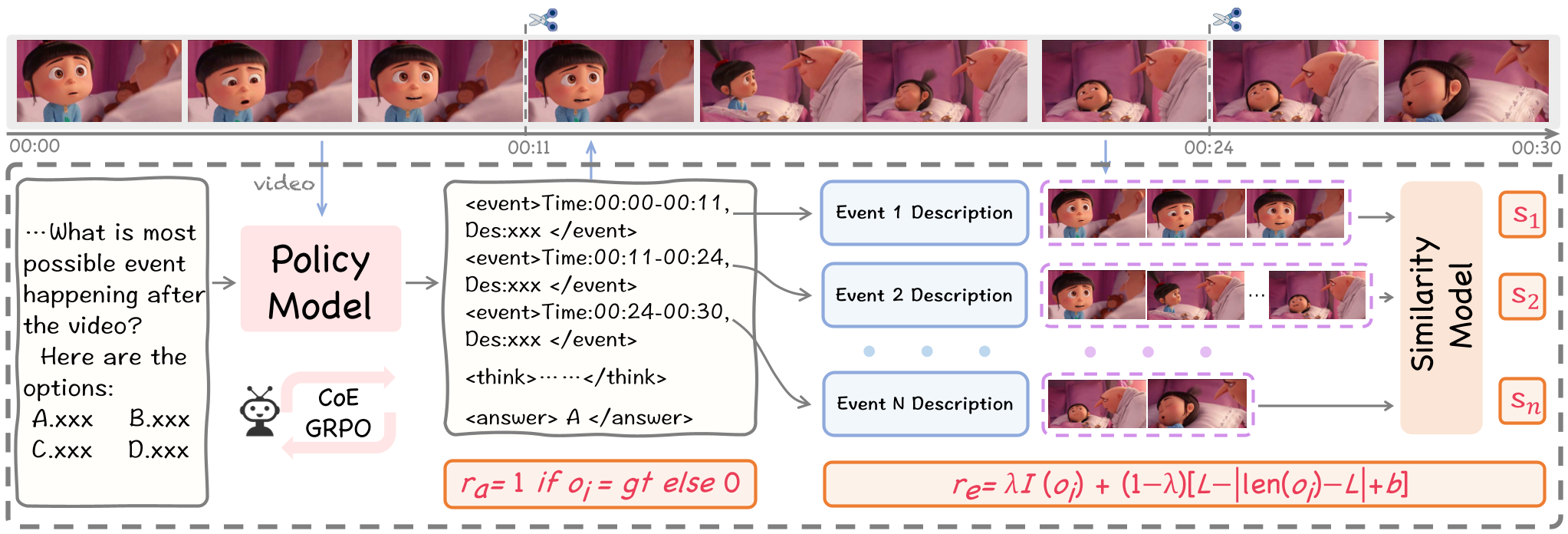
既然模型不看视频,那就通过任务定义强迫它看。模型必须输出 Event = <event> Time: [start-end], Des: [description] </event> 格式的内容,形成一个有时序、有语义的事件链(EC)。
两阶段强化:SFT + GRPO
- CoE-SFT (逻辑热身):利用目前最强的 Qwen2.5-VL-72B 生成高质量的逻辑推理链数据,训练模型如何从已知视频内容推导出未来事件,解决“冷启动”问题。
- CoE-GRPO (能力解锁):这是本文的神来之笔。借鉴了 DeepSeek-R1 的逻辑,作者设计了三种奖励激励模型:
- 准确性奖励 (ra):猜对了给分。
- 格式奖励 (re):按要求的 <event> 标签输出、控制长度给分。
- 相似度奖励 (rs):最为关键。利用 VideoCLIP 或 CLIP 模型计算模型生成的描述与对应时间戳视频切片的余弦相似度。这从底层杜绝了奖励作弊(Reward Hacking),强制模型生成的每一句描述都必须与视频画面对得上。
3. 实验战绩:全线超越 GPT-4o
在 FutureBench 和 AVEP 两个主流榜单上,Video-CoE 展现了统治级的实力:
- 性能飞跃:在 Qwen2.5-VL-7B 基础上,Video-CoE 将 FutureBench 的 AVG 分数从 52.94 提升到了 75.00,甚至超越了 72B 规模的模型和 GPT-4o。
- 视觉回流:注意力分析显示,CoE 显著提升了模型对视觉 Token 的关注度(Winning Rate 达到 77% 以上),证明模型确实在通过“看”视频来推断未来。

4. 深度洞察:为什么这种范式有效?
Video-CoE 的成功在于它改变了 MLLM 处理时序信息的方式。传统的模型是“全量吞入、模糊输出”,而 CoE 将长视频解析为离散的符号化事件。
相似度奖励 (Similarity Reward) 的引入解决了 MLLM 训练中最头疼的内容对齐问题。通过强制模型提取时间戳并做内容对齐,它无意中增强了模型的时序定位 (Temporal Localization) 能力。即使在 Open-set(无选项直解)的情况下,Video-CoE 的胜率依然遥遥领先。
5. 总结与反思
Video-CoE 证明了:逻辑推理不是空中楼阁,它必须扎根于细粒度的感知之上。
局限性:目前事件链的结构还比较单一(线性结构),未来如果能扩展到复杂的事件图(Event Graph)或引入因果推断(Causal Inference),MLLM 在动态世界中的理解能力将再上一个台阶。
主编点评 scale 虽然是 LLM 的第一驱动力,但在特定细分任务中,精妙的逻辑引导(Inductive Bias)和多重对齐的强化学习反馈,依然能产生“以小博大”的奇迹。