本文提出了 VTAM (Video-Tactile Action Model),这是一种将高分辨率触觉感知集成到视频预测世界模型中的具身智能框架。通过在预训练视频 Transformer 中联合建模视觉与触觉 latents,VTAM 在处理薯片抓取、削皮和擦拭等复杂接触任务时,相比纯视觉基线 π0.5 实现了显著的性能提升。
TL;DR
在机器人操作中,视觉能告诉你“杯子在哪里”,但只有触觉能告诉你“杯子是否快要滑脱”。本文提出的 VTAM (Video-Tactile Action Model) 首次将触觉深度嵌入基于视频扩散的世界模型中。通过联合预测视频和触觉的变化趋势,VTAM 让机器人在面对易碎的薯片或需要持续力控的削皮任务时,展现出了远超 SOTA 视觉模型(如 π0.5)的稳定性,成功率提升幅度高达 80% 以上。
痛点深挖:为什么 VLA 模型总是“手没轻没重”?
当前的具身智能模型(VLA)主要依赖互联网规模的图像-文本对进行训练。虽然它们在语义理解上很强,但在物理交互上却存在致命伤:
- 视觉遮挡(Occlusion):当机械臂抓取物体时,手爪往往会挡住视线,模型无法通过视觉判断抓取力度。
- 接触动力学缺失:摩擦力、形变、滑动等微观现象在静态视觉中是不可见的。
- 模态崩塌(Modality Collapse):在训练多模态模型时,视觉信号往往占据主导,导致模型在优化过程中逐渐忽略了“微弱”的触觉梯度。
VTAM 的核心直觉在于:触觉不应仅仅是动作头的附加输入,而应是世界模型理解物理动态的核心一环。
核心方法:VTAM 的“通感”架构
VTAM 的架构设计精妙地平衡了高性能预训练权重的重用与新模态的引入。
1. 联合潜空间世界建模 (Joint Latent World Modeling)
VTAM 并未重新发明轮子,而是基于预训练的视频 VAE。它将三路输入(两个机位视角 + 一路 GelSight 触觉图像)映射到统一的 Latent Space。
- 架构亮点:采用 交替注意力(Alternating Attention) 机制。模型先在各模态内部进行自注意力(Self-Attention)以捕捉空间结构,然后进行跨视图注意力(Cross-View Attention)以实现视觉与触觉的动力学对齐。
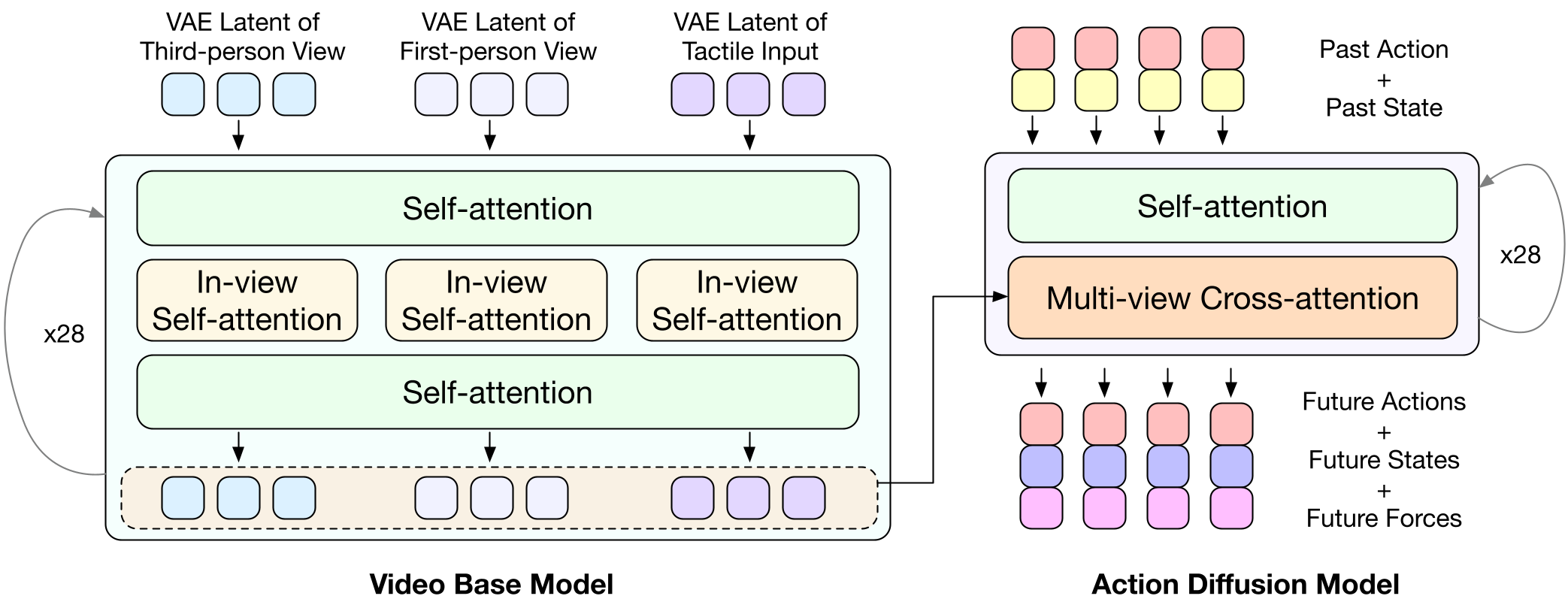 图 2:VTAM 架构概览。视频潜变量与触觉潜变量通过 Transformer 骨干网络进行联合动力学建模。
图 2:VTAM 架构概览。视频潜变量与触觉潜变量通过 Transformer 骨干网络进行联合动力学建模。
2. 变形感知正则化:虚拟力的妙用
为了防止模态崩塌,作者提出了一个天才的辅助任务:虚拟力预测。 利用光流法(Optical Flow),模型从触觉传感器的形变中提取出 三维辅助信号:
- 代表切向剪切力。
- 代表法向压缩力(通过流场的散度近似)。
在 Stage II 训练动作头时,模型不仅要预测 Action,还要预测这个“虚拟力”。这强迫模型在优化过程中必须关注触觉 Latent,极大稳定了训练。
实验战绩:让机器人学会“心细如发”
作者在三类极具挑战的任务上验证了 VTAM:
- 捏薯片 (Potato Chip Pick-and-Place):既不能捏碎,又不能掉落。
- 削皮 (Cucumber Peeling):需要维持恒定的法向力来剥开菜皮。
- 擦白板 (Whiteboard Wiping):在倾斜表面上维持稳定的压力。
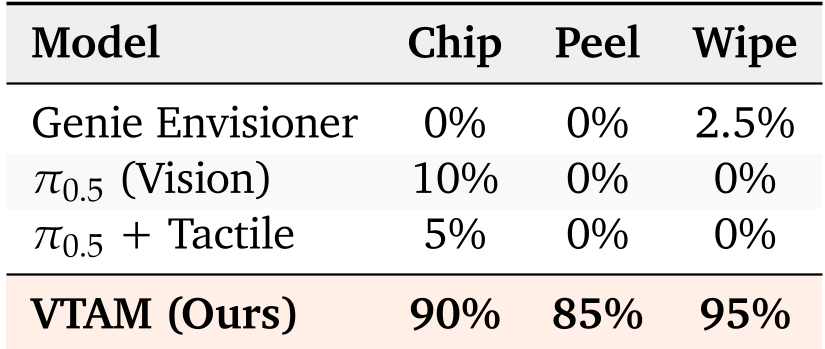 表 1:不同模型在各任务上的成功率对比。VTAM 在所有任务中均表现出显著优势。
表 1:不同模型在各任务上的成功率对比。VTAM 在所有任务中均表现出显著优势。
关键发现:
- 视觉是盲目的:π0.5 视觉模型在薯片任务上成功率仅为 10%,因为它无法感知何时该停手,常把薯片捏碎。
- 预测优于反应:相比于只在最后阶段耦合触觉的方法(Late-Fusion),VTAM 通过世界模型预判未来的触觉演变,使其对复杂接触的响应快且准。
深度洞察:具身智能的下一站
VTAM 的成功揭示了一个深刻的道理:真正的物理智能需要“闭环”的预测能力。通过将触觉信号引入扩散模型,VTAM 不仅学会了执行动作,更学会了“想象”动作对环境造成的物理反馈。
局限性 (Limitations): 目前 VTAM 仍依赖于高质量的触觉演示数据,且虚拟力的计算基于几何启发式方法,未来若能引入真正的物理力传感器数据进行多任务蒸馏,其通用性将进一步增强。
总结 (Takeaway): VTAM 证明了触觉是解决复杂物理交互瓶颈的关键。对于长序列、高精度的机器人任务,我们需要不仅仅是“看”世界的眼睛,更需要能“感知”物理规律的触觉。