本文提出了 VISER 系统,一种利用人类视觉显著性(Human Saliency)指导深度学习训练的开集虹膜演示攻击检测(PAD)方法。通过引入去噪后的眼动追踪热图作为先验知识,该方法在处理未见的攻击类型时表现出极强的鲁棒性,显著优于传统的交叉熵训练和基于 DINOv2 的基座模型。
TL;DR
在虹膜防伪(PAD)领域,如何让模型像人类专家一样敏锐地识别“未见过”的假眼?圣母大学(University of Notre Dame)的研究团队通过 VISER 系统证明:眼动追踪(Eye Tracking)数据中蕴含的生理视觉直觉,比精细的手动标注更能提升模型的泛化能力。 实验表明,利用去噪后的注视热图引导模型训练,其开集检测性能远超 DINOv2 等视觉大模型。
痛点深挖:为什么 AI 容易被“未见的攻击”欺骗?
当前的虹膜 PAD 系统大多处于“闭集”思维,即在 A 攻击上训练,在 A 攻击上测试。然而,现实世界中的攻击手段层出不穷(如新型义眼、特殊纹理隐形眼镜等)。传统的深度学习模型往往会捕捉到与攻击本质无关的伪影,导致在面对未知攻击类型(Open-set)时彻底失效。
此前,学术界尝试通过人类标注来引入“归纳偏置(Inductive Bias)”,但存在一个致命缺陷:手动点击(Motor Saliency)是一种二阶意识表现。 当你用鼠标画框时,你的大脑已经经过了过滤和规划,损失了大量下意识捕捉到的细微纹理信号。
核心动机:捕捉“生理本能”
作者认为,眼动注视(Visual Saliency) 是第一阶生理信号,直接反映了大脑处理视觉刺激的原始反馈。通过将这种“专家直觉”注入模型,可以强制 AI 关注那些真正具有辨别力的区域。
方法论详解:VISER 的炼金术
VISER 的核心流程是将 DenseNet-121 作为 BackBone,并在损失函数中加入了一个特殊的显著性分支。
1. 显著性引导 Loss
模型不仅要预测“真/假”,还要让其生成的 Class Activation Map (CAM) 与人类的注视热图尽可能一致。公式表达为: $$L_{total} = L_{XENT}(y, \hat{y}) + \lambda \cdot MSE(CAM, Saliency_{human})$$
2. HDBSCAN 去噪处理
眼动仪捕获的数据包含大量的噪声(如微动眼跳、注意力分散等)。作者引入了 HDBSCAN(基于层次密度的聚类算法),过滤掉孤立的、不稳定的注视点,提取出最核心的视觉注意力簇。
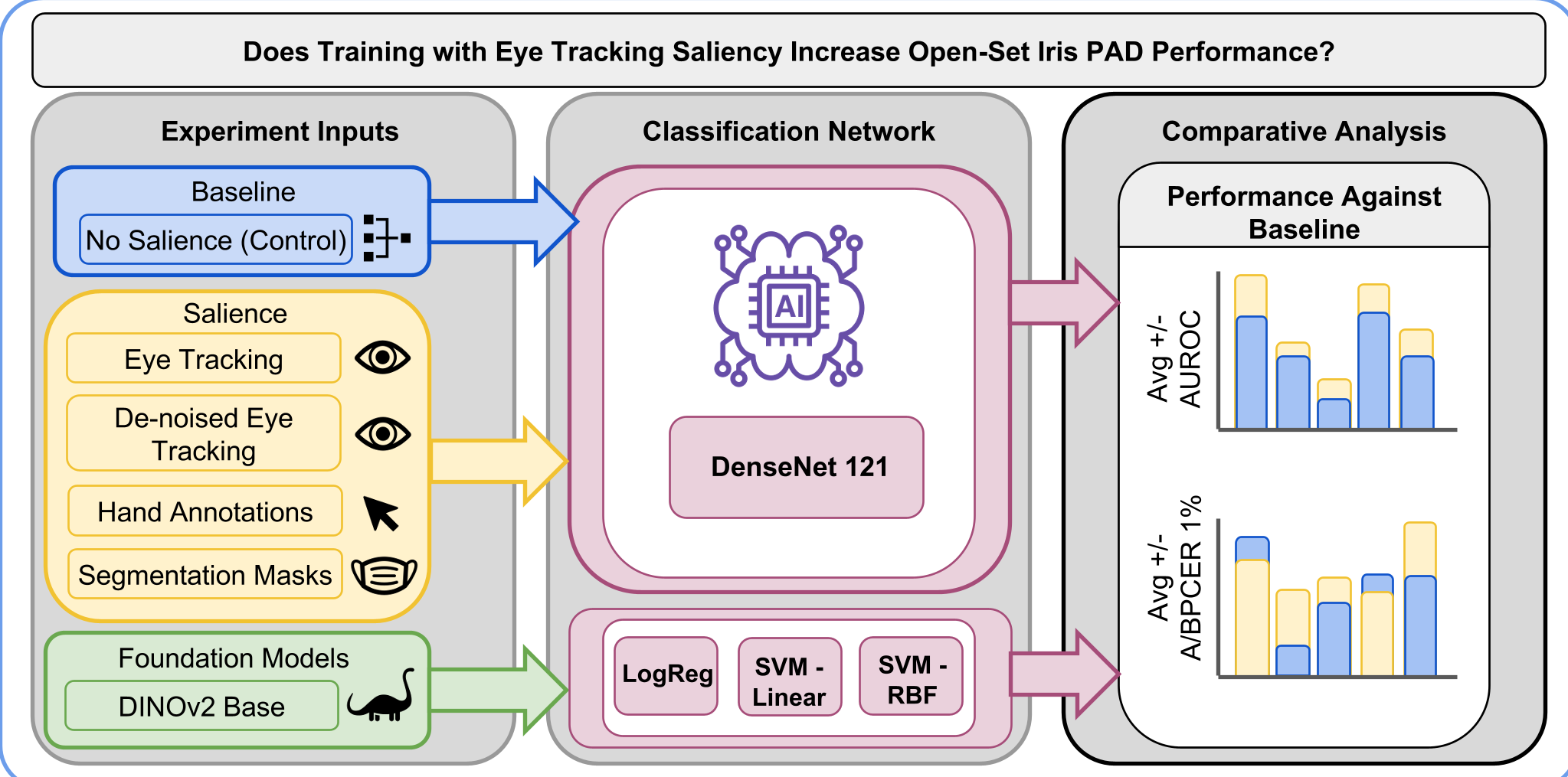 图 1:VISER 实验流水线:对比了分割掩码、手动标注、眼动追踪以及大模型嵌入多种模态。
图 1:VISER 实验流水线:对比了分割掩码、手动标注、眼动追踪以及大模型嵌入多种模态。
3. 第一印象 vs. 全程关注
研究发现,人类在判断真伪时的“第一印象”(Initial 2 seconds)往往能抓住最本质的缺陷。VISER 专门提取了这一阶段的数据进行实验。
实验与结果:吊打 SOTA 与大模型
研究采用“留一攻击法”测试泛化性,涵盖了打印攻击、合成攻击、义眼攻击等 7 大类别。
关键发现:
- 眼动数据完胜手动标注:手动标注(Hand Annotations)对于 APCER 指标几乎没有正面贡献,甚至可能引入干扰。
- 去噪是关键:经过 HDBSCAN 去噪后的“第一印象”热图(De-noised Initial ET)在所有指标上达到了最优(AUROC +6.08%)。
- 大模型的局限性:虽然 DINOv2 在闭集表现良好,但在真开集环境下,其特征嵌入对于某些特定攻击类型(如纹理隐形眼镜)的辨别力依旧不如经过显著性引导的轻量级模型。
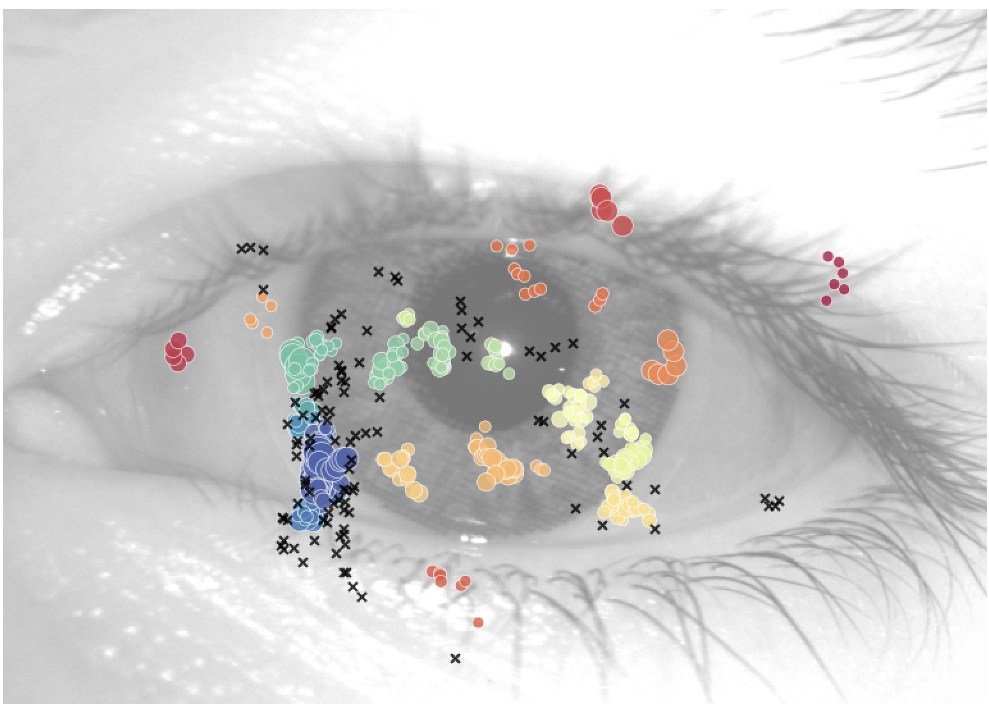 图 2:使用 HDBSCAN 对眼动轨迹进行聚类去噪的示例,黑色叉号为被过滤的噪声。
图 2:使用 HDBSCAN 对眼动轨迹进行聚类去噪的示例,黑色叉号为被过滤的噪声。
深度洞察:为什么这很重要?
VISER 的成功揭示了生物特征识别领域的一个本质:AI 的瓶颈不在于网络更深,而在于“看”问题的角度不对。
- 运动规划瓶颈(Motor Bottleneck):这解释了为什么以往通过外包众包得到的标注对模型提升有限。
- 开集泛化:人类视觉系统天生具备处理“异常”的能力,通过注视点指导,模型学会了放弃寻找特定的攻击模式,转而去学习“正常的虹膜应该长什么样”的深层流形(Manifold)。
结论与展望
VISER 证明了生理视觉先验在提升 AI 鲁棒性方面的巨大潜力。尽管获取眼动数据比常规标注昂贵,但在安全等级极高的场景下(如边境检查、离岸金融支付),这种“专家经验的无损迁移”是通往可信 AI 的必经之路。
未来方向: 如何在没有眼动仪的情况下,通过合成或模拟的方式生成高质量的类人眼动热图?这将是该领域下一个令人兴奋的突破点。