本文提出了 Vision Hopfield Memory Network (V-HMN),一种受大脑启发的视觉基础骨干网络,核心通过集成层级化现代 Hopfield 存储模块与预测编码(Predictive Coding)驱动的迭代精益更新,完全取代了传统的 Self-attention 或 SSM 机制,在多项 CV 任务中达到 SOTA。
TL;DR
传统的 Vision Transformer (ViT) 和 Mamba 虽然强大,但本质上都是极度依赖数据的“黑盒”。本文提出的 V-HMN 另辟蹊径,抛弃了 Self-attention,将联想记忆 (Associative Memory) 和预测编码 (Predictive Coding) 作为核心,不仅在小样本场景下吊打 ViT,更在可解释性和鲁棒性上展现了类脑计算的天然优势。
痛点深挖:为什么我们需要“记忆”?
目前的深度学习模型大多是“单向直觉派”:输入图像,经过层层卷积或注意力,最后给出一个预测。这种机制错过了大脑处理信息的两个关键特征:
- 联想检索:人类看到模糊的轮廓就能通过记忆补全细节。
- 迭代修正:大脑不断产生预测,并根据感知反馈的“预测误差”来纠正认知。 缺乏这些机制导致模型在数据稀缺时极易崩溃,且难以解释其决策依据。
核心方法:V-HMN 的类脑架构
V-HMN 不再把记忆看作插件,而是将其作为骨干网络的“核心动力”。
1. 局部与全局双重存储层级
每个 HMN Block 都由两条路径组成:
- Local Window Memory:通过提取 $k imes k$ 的局部邻域,在类平衡的存储库(Memory Bank)中检索最匹配的局部原型(Prototypes)。这类似于卷积的感受野,但它是通过“补全”而非单纯的加权平均。
- Global Template Path:全局池化后生成场景查询,检索宏观语义原型。
2. 预测编码驱动的迭代精益 (Iterative Refinement)
这是 V-HMN 的核心数学直觉。给定特征 $z$ 和检索到的记忆原型 $m$,更新公式为: $$z^{(t+1)} = z^{(t)} + \beta (m - z^{(t)})$$ 这里的 $(m - z^{(t)})$ 本质上是预测误差。模型通过迭代,不断尝试减小这个误差,使当前的表示向记忆中存储的“标准模式”靠拢。
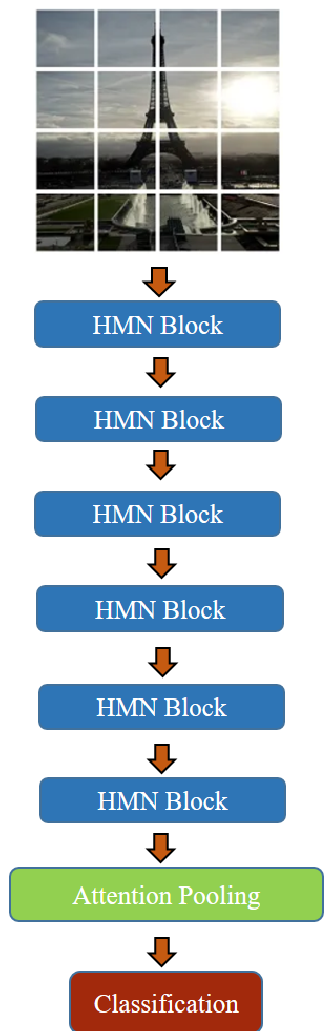 图 1:V-HMN 块结构(左)与整体骨干网络(右)的系统设计。可以看到存储检索完全取代了 Self-attention。
图 1:V-HMN 块结构(左)与整体骨干网络(右)的系统设计。可以看到存储检索完全取代了 Self-attention。
实验战绩:数据效率的跨越式提升
V-HMN 最惊人的表现在于数据效率。在仅使用 10% 标注数据时,其性能远超同等规模的 ViT、Swin 和 Mamba:
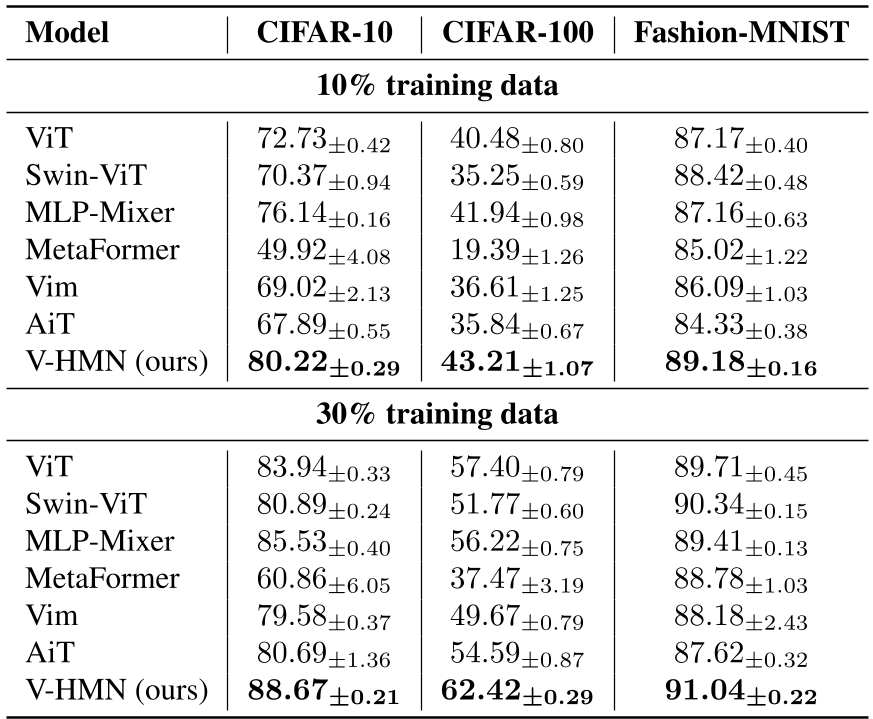 表 1:在不同数据比例下的性能对比。注意在极低数据量下,V-HMN 的领先幅度高达 7%-10%,显示了存储原型作为 Inductive Bias 的巨大威力。
表 1:在不同数据比例下的性能对比。注意在极低数据量下,V-HMN 的领先幅度高达 7%-10%,显示了存储原型作为 Inductive Bias 的巨大威力。
此外,通过可视化可以发现,V-HMN 真正实现了“决策透明”:我们可以清晰地看到模型在处理一个汽车图片时,到底从记忆库中调用了哪些“车轮”和“车身”的原型。
 图 2:局部与全局记忆检索的可视化。模型能够精准定位同类物体的局部对应关系(如不同车辆的底盘结构)。
图 2:局部与全局记忆检索的可视化。模型能够精准定位同类物体的局部对应关系(如不同车辆的底盘结构)。
深度洞察:为什么它更鲁棒?
通过消融实验(Ablation Study)发现,迭代次数 $t$ 是关键。即使只进行 1 次迭代,模型在面对遮挡(Occlusion)和噪声时的鲁棒性也会大幅增强。这是因为 Hopfield 动力学天然具有“吸引子”特性,能够将偏离轨道的噪声输入拉回到记忆中的稳定状态。
总结与局限
V-HMN 证明了以存储为中心的架构在视觉任务中不仅可行,而且在特定维度上(如样本效率、可解释性)优于注意力机制。
- 局限性:目前 Memory Bank 的维护依赖于 Ring Buffer 的更新策略,在大规模类别扩展时,存储库的管理复杂度可能会增加。
- 未来展望:这种“检索-精益”的范式值得推广到多模态领域,特别是长尾分布的数据集。
资深主编点评:V-HMN 不仅仅是一个刷榜的模型,它更深远的意义在于将联想记忆(Hopfield)从一种“池化工具”提升到了“通用骨干”的高度。它不仅让我们看到了效率提升,更给了我们一个观察 AI 决策过程的窗口。