本文提出了首个基于离散扩散多模态大模型(DVLM)的 GUI 定位框架。通过适配 LLaDA-V 模型并引入“混合掩码调度(Hybrid Masking Schedule)”,该方法在多个 GUI 定位基准测试中展现出与自回归(AR)模型相当的竞争力,实现了单步动作(Action)与边界框(Bounding-box)的精准预测。
TL;DR
长期以来,GUI 代理(GUI Agents)一直被自回归(AR)模型统治。本文打破了这一现状,首次系统性地探索了离散扩散视觉语言模型(DVLMs)在 GUI 定位任务中的潜力。通过创新的混合掩码调度(Hybrid Masking),模型不仅在四个主流基准测试(Web, Mobile, Desktop)上达到了 SOTA 水平,更在空间推理的精确度上展现了扩散模型特有的“迭代精炼”优势。
核心动机:自回归的局限与扩散的直觉
在 GUI 定位任务中,模型需要根据指令(如 "点击搜索框")在屏幕截图上画出一个边界框 。
现有痛点:
- 单向依赖:自回归模型(如 Qwen2.5-VL)按顺序生成 Token,难以在生成坐标时同时兼顾全局上下文。
- 几何逻辑缺失:随机掩码策略在训练扩散模型时,会将所有 Token 视为独立个体,忽略了 作为点击锚点与 作为覆盖范围之间的强几何耦合。
作者敏锐地察觉到:如果能引导模型先确定“哪里需要点”,再以此为基础细化“框有多大”,就能大幅提升定位稳定性。
混合掩码调度:一种“由粗到细”的空间策略
本文最核心的贡献在于将训练过程分解为两个强交互阶段:
- 线性掩码阶段 (Linear Masking):遵循传统的 LLaDA-V 逻辑,让模型在随机噪声中学会识别动作类型(点击、悬停、输入)和初始位置锚点。
- 全确定性掩码阶段 (Deterministic Masking):这是关键突破。模型被强制在已知 的前提下,去“填空”剩下的边界框范围 。这种确定性的引导有效地强化了模型对条件概率 的建模。
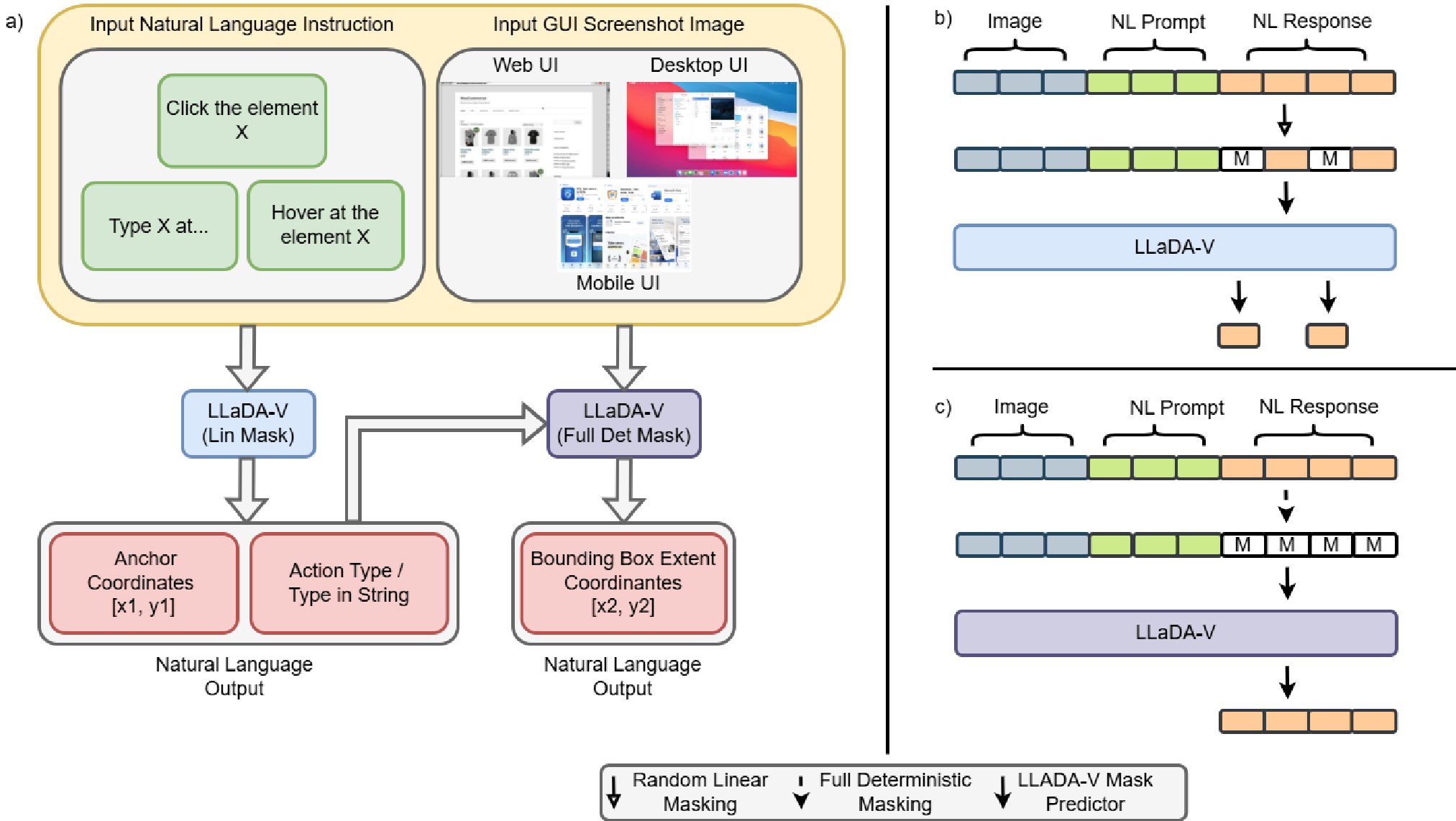 图 1:LLaDA-V 的 GUI 适配架构与两阶段混合掩码流程。
图 1:LLaDA-V 的 GUI 适配架构与两阶段混合掩码流程。
实验战绩:扩散模型也能刷榜
通过在 120K 条涵盖移动端、桌面端、Web 端的混合数据上进行训练,实验结果清晰地展示了扩散模型的优越性:
- 通用性显著增强:即使只在 Web 数据上训练,扩散模型在移动端(ScreenSpot)上也展现出了极佳的泛化能力。
- 混合掩码的奇效:相比默认的线性掩码,混合策略在 VisualWebArena 上的 SSR(步成功率)从 61.4% 暴涨至 67.5%。
- 推理平衡:作者发现,设置 64 步扩散、64 个生成长度是准确率与延迟(Latency)的最佳平衡点。
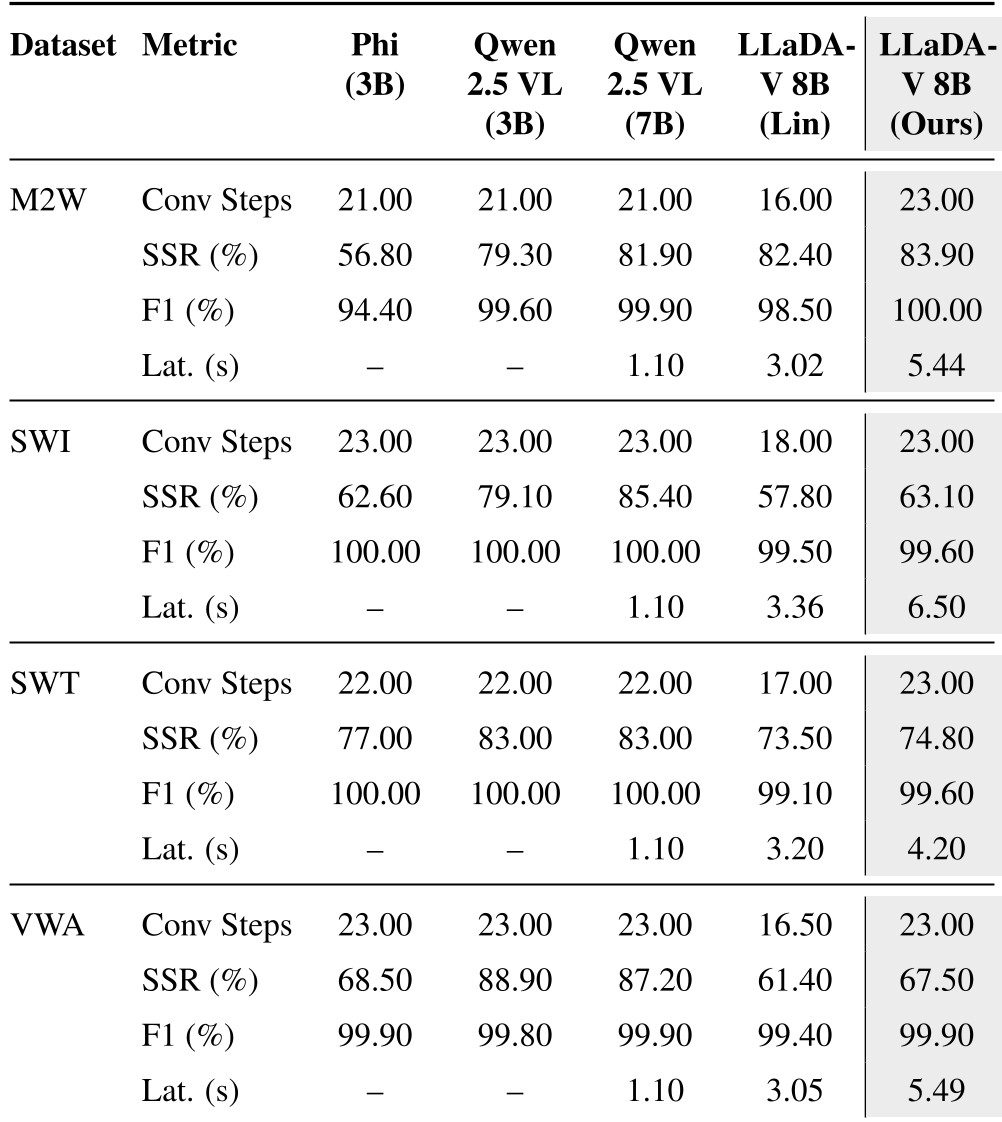 表 1:LLaDA-V 8B 与 Phi-3、Qwen 2.5 等自回归强基线的 SSR 与 F1 性能对比。
表 1:LLaDA-V 8B 与 Phi-3、Qwen 2.5 等自回归强基线的 SSR 与 F1 性能对比。
深度洞察:为什么扩散模型有效?
- 双向注意力的力量:与 AR 模型的单向注意力不同,扩散模型在每一步去噪时都能看到整个序列的上下文。对于坐标这种高度依赖结构信息的 Token 序列,双向视野能有效防止“一步错、步步错”的漂移现象。
- 低置信度重新掩码 (Low-confidence Re-masking):这是 LLaDA-V 的核心机制。在推理时,模型会保留足够自信的预测,而对不确定的 Token 进行重新去噪,这在本质上是一种基于不确定性的自我修正。
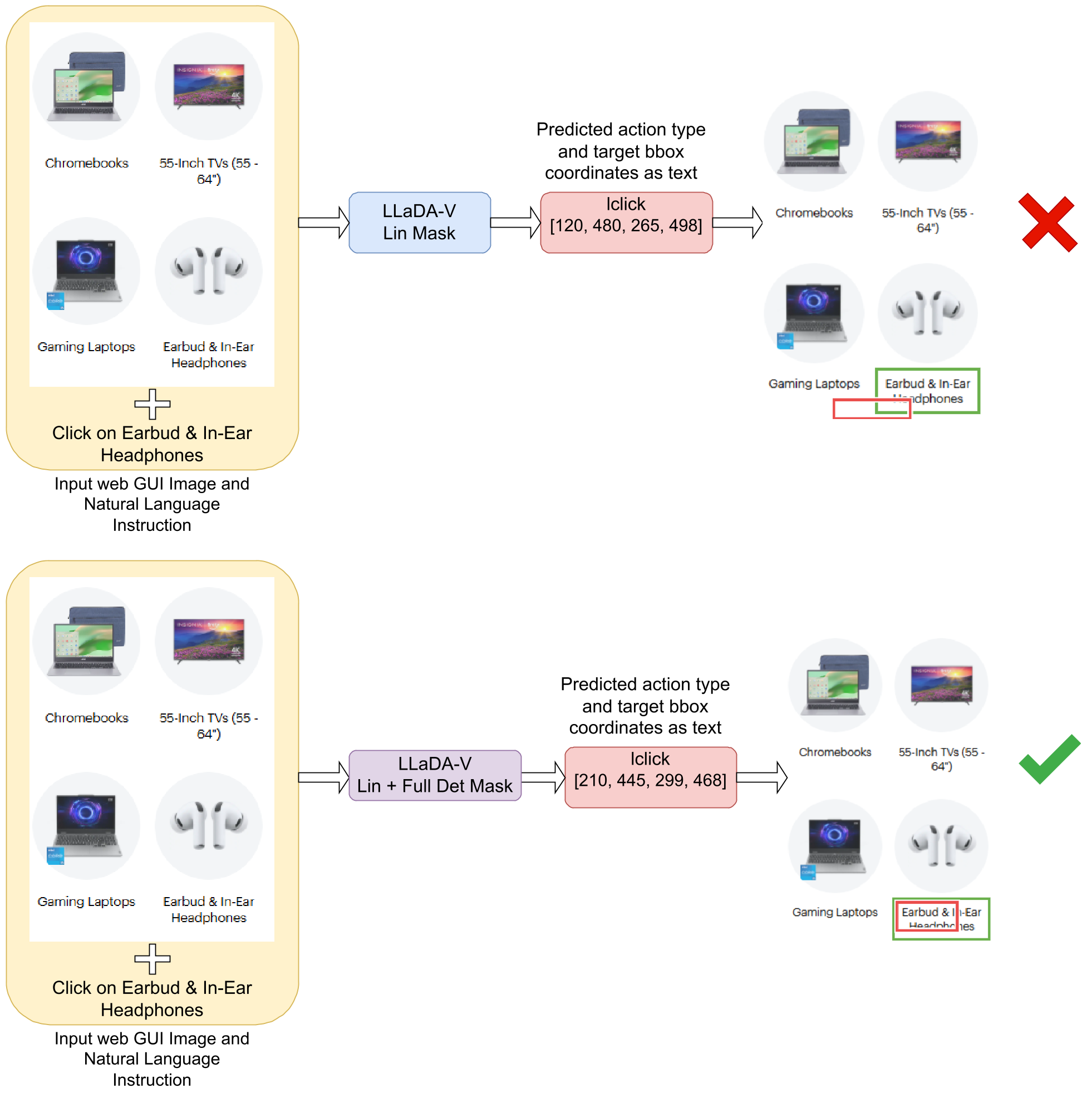 图 2:混合掩码解决了线性掩码下坐标微偏移的问题(红色为模型预测,绿色为真值)。
图 2:混合掩码解决了线性掩码下坐标微偏移的问题(红色为模型预测,绿色为真值)。
局限性与未来展望
尽管扩散模型在 GUI 定位上取得了成功,但其瓶颈依然存在:
- 延迟挑战:相比 AR 模型的单次解码,扩散模型的多次迭代导致其推理速度慢约 3-5 倍。
- 多步规划:目前仅限于单步 Action,如何处理复杂的长程决策链(Multi-turn Planning)仍是待攻克的难题。
总结:这篇文章不仅证明了离散扩散模型在视觉任务中的可行性,更通过对空间几何逻辑的深刻洞察,为构建下一代非自回归 GUI 代理提供了坚实的路径参考。