本文推出了 vla-eval,这是一个专为具身智能领域设计的统一评估框架。它通过 WebSocket+msgpack 协议和 Docker 镜像实现了模型推理与仿真环境的彻底解耦,目前支持 13 种主流机器人仿真基准测试(如 LIBERO, CALVIN)和 6 种 SOTA VLA 模型(如 OpenVLA, π0)。
TL;DR
在视觉-语言-动作(VLA)模型研究火热的今天,如何公平、高效地评估模型已成为行业瓶颈。vla-eval 是一款类似大模型界 lm-eval 的开源工具包,通过 Docker 容器化隔离 和 高性能并行推理,将原本需要一整天的测试压缩到了 18 分钟内,并支撑起了涵盖 657 项结果的 VLA 全球排行榜。
痛点深挖:为何 VLA 模型复现这么难?
当前的机器人学习(Robot Learning)领域面临着严重的“环境地狱”:
- 依赖冲突:LIBERO 需要 Python 3.8,而 ManiSkill2 却定死在 Python 3.10,两者几乎无法在同一个 Conda 环境中共存。
- 黑箱参数:许多论文不会告知你它们使用了哪组 Observation Normalization(归一化统计量),或者机器人是在哪一个瞬间判定任务成功的。
- 效率极低下:单次线性运行 2,000 个 Episode 需要消耗十几个小时,研究员的一半时间都浪费在了等待进度条上。
核心架构:解耦与协议标准化
vla-eval 的核心设计哲学是 Client-Server 架构。
- 模型端 (Model Server):在宿主机运行,通过一个简单的
predict()接口暴露服务。 - 环境端 (Benchmark Suite):每个 Benchmark(如 CALVIN, RoboCasa)都封装在独立的 Docker 镜像中,内置了所有的物理引擎(PyBullet, SAPIEN)和资源文件。
- 通信层:使用基于 WebSocket 的 msgpack 协议,像调用微服务一样进行“观察-动作”循环。
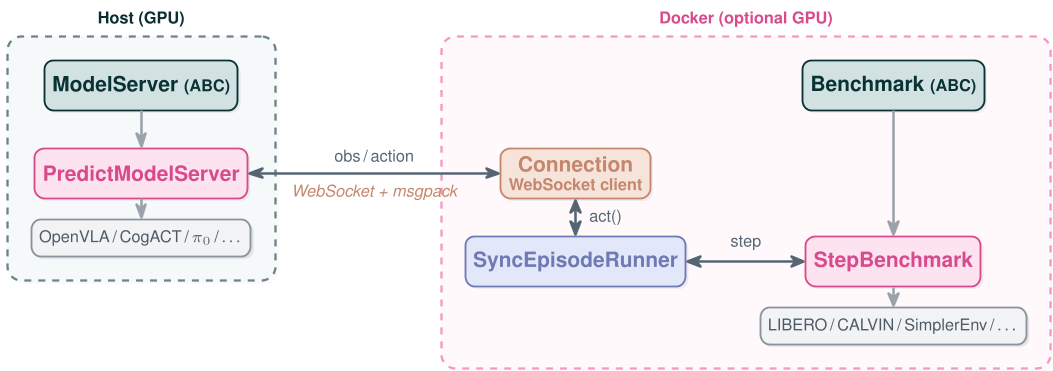 图 1:vla-eval 的系统架构,模型与环境通过 Docker 彻底隔离
图 1:vla-eval 的系统架构,模型与环境通过 Docker 彻底隔离
并行黑科技:从 14 小时到 18 分钟
为了解决速度问题,作者提出了**需求/供给匹配(Demand/Supply)**的并行化方案:
- Episode Sharding:将 2,000 个任务分发到 N 个并行的 Docker 容器中。
- Batch Inference:利用 GPU 的并发能力,跨环境收集观察值,一次性丢给模型进行批处理预测。
在 H100 上,通过调整分片数 $N=50$ 和 Batch Size $B=16$,吞吐量提升了 47 倍。
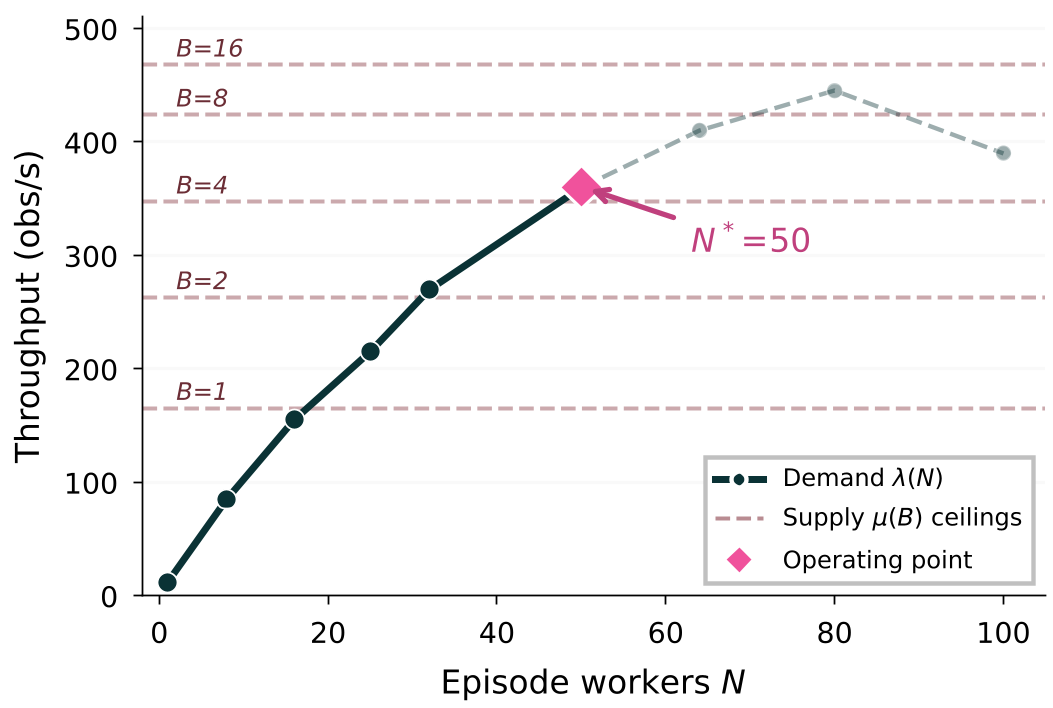 图 2:随分片数增加,环境吞吐量 λ 与模型供给能力 μ 的平衡曲线
图 2:随分片数增加,环境吞吐量 λ 与模型供给能力 μ 的平衡曲线
深度洞察:揭秘“沉默的性能杀手”
在对 CogACT 模型进行审计时,作者发现了两个极其容易被忽视的实验陷阱:
- 终止语义歧义 (Ambiguous Termination):在某些环境中,
terminated标志代表瞬间成功(如方块刚刚碰在一起),如果此时立刻停止,机器人随后的惯性可能会撞倒方块导致失败。正确的做法是强制运行到最大步数。 - 隐蔽的归一化 (Hidden Normalization):CALVIN 等基准需要训练集特定的均值/方差来处理机器人状态。如果这些硬编码参数没写在论文里,复现者的性能会直接崩盘。
 表 1:使用 vla-eval 复现的数值与原论文高度一致,验证了框架的可靠性
表 1:使用 vla-eval 复现的数值与原论文高度一致,验证了框架的可靠性
总结与未来展望
vla-eval 不仅仅是一个工具,它更是一套具身智能评估的科学协议。
- 排行榜效应:作者统计发现,81% 的 VLA 模型只在一个基准上测过。这说明跨场景的稳健性(Robustness)目前远未达标。
- 局限性:目前仅支持仿真环境,尚未覆盖真机(Real-robot)和更复杂的运动质量评估。
对于开发者来说,现在只需 vla-eval serve 和 vla-eval run 两条命令,即可开始一段标准化的具身智能科研旅程。
Takeaway: 正如 ImageNet 之于 CV,一套统一且高效的测评框架将极大地加速通用机器人大模型的演进。