VLA-OPD introduces an On-Policy Distillation framework that bridges the gap between offline Supervised Fine-Tuning (SFT) and online Reinforcement Learning (RL) for Vision-Language-Action models. By leveraging a Reverse-KL objective, the student model learns from a frozen expert teacher's dense, token-level supervision on its own self-generated trajectories, achieving SOTA performance on LIBERO and RoboTwin2.0.
Executive Summary
TL;DR: VLA-OPD is a post-training framework that solves the "brittleness" of Vision-Language-Action (VLA) models by combining the speed of Supervised Fine-Tuning (SFT) with the robustness of Reinforcement Learning (RL). By using a Reverse-KL objective to distill knowledge from an expert teacher onto the student's own trajectory rollouts, the framework achieves near-expert performance with "vertical" convergence speeds and effectively eliminates catastrophic forgetting.
Positioning: This work moves beyond simple Behavior Cloning and sparse-reward RL, positioning itself as a highly efficient "alignment" tool for robotic foundation models, similar to how DPO or RLHF aligns LLMs.
The "Post-Training" Dilemma in Robotics
While pre-trained VLAs like OpenVLA possess broad semantic knowledge, they often fail during mission-critical execution. The community currently relies on two flawed tools:
- Offline SFT: Fast but "blind." Once the robot drifts slightly from the expert's path, it doesn't know how to recover, leading to the infamous compounding error problem.
- Online RL: Robust but "slow." Relying on binary "success/failure" signals (sparse rewards) is like trying to learn a complex dance while only being told "good" or "bad" at the very end of the performance.
Methodology: The Power of Reverse-KL
VLA-OPD fixes this by introducing On-Policy Distillation. Instead of relying on environmental rewards, it uses an "Expert Oracle" (Teacher) to provide a dense, token-level roadmap for the student.
The Three-Phase Cycle:
- Exploration: The student VLA acts in the environment, naturally drifting into "failure states."
- Correction: For every state—even the weird ones—the Teacher tells the student: "Here is what I would have done."
- Optimization: The student minimizes the Reverse-KL Divergence from the teacher.
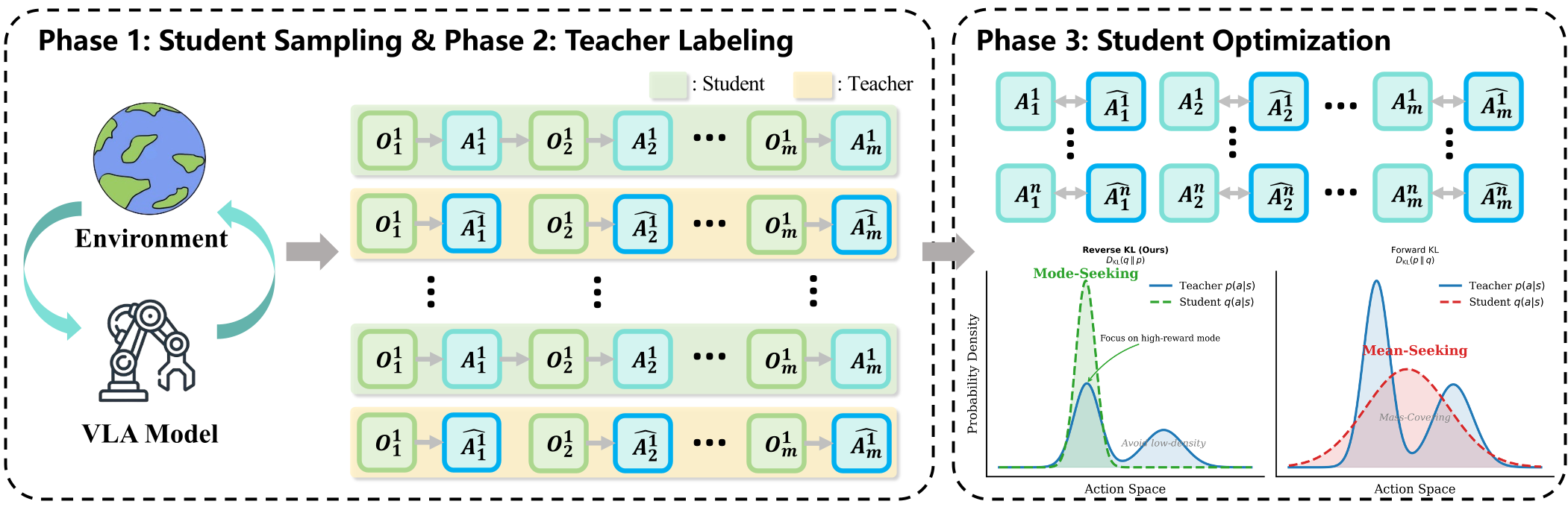
Why Reverse-KL?
The authors provide a sophisticated insight into divergence directions:
- Forward-KL (Mode-Covering): Forces the student to mimic the teacher's uncertainty. If the teacher is "unsure," the student becomes "hesitant," leading to Entropy Explosion.
- Hard-CE (Argmax Matching): Forces the student to track only the teacher's top choice. This kills diversity, leading to Entropy Collapse.
- Reverse-KL (Mode-Seeking): Allows the student to pick one "good" mode from the teacher and commit to it. This keeps the policy decisive while maintaining enough stochasticity for exploration.
Experimental Validation
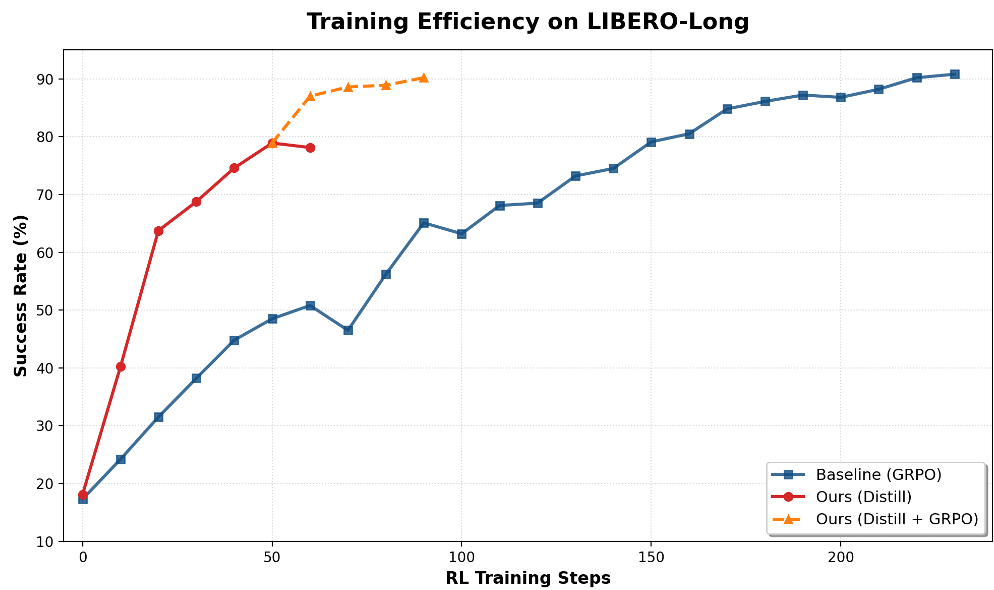
The results are striking, particularly in terms of Sample Efficiency.
1. Vertical Convergence
In the LIBERO-Object suite, VLA-OPD reaches a 90% success rate in a fraction of the time required by standard GRPO (on-policy RL). It’s not just an improvement; it’s a categorical shift in training speed.
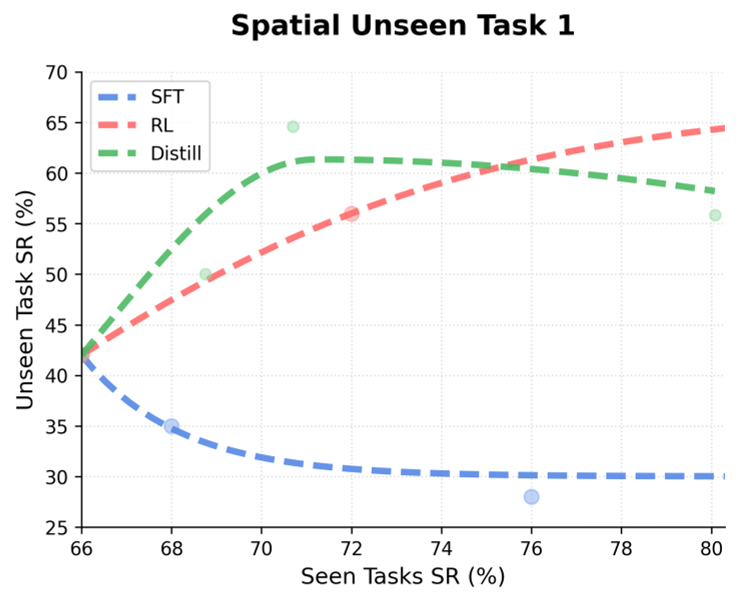
2. Solving Catastrophic Forgetting
A major headache in VLA tuning is that learning a new skill often "erases" the model's general capabilities. VLA-OPD remains in a "safe" distributional neighborhood by updating on its own active manifold, effectively preserving pre-trained skills better than offline SFT.
Critical Analysis & Perspective
Insights:
The core value of VLA-OPD is decoupling exploration from optimization. By using a teacher to "label" the student's messy exploration, we no longer need the environment to provide the signal. This is a game-changer for tasks where rewards are hard to define.
Limitations:
- Teacher Dependency: The method assumes a high-quality teacher is available. While single-task experts are easier to train than generalists, you still need a "source of truth."
- Inference Overhead: Querying a large teacher model during the student's training can be computationally expensive (mitigated in the paper by using smaller group sizes ).
Conclusion
VLA-OPD proves that for the next generation of generalist robots, we don't need more data as much as we need better alignment. By using Reverse-KL to bridge SFT and RL, the authors have provided a robust blueprint for continuous foundation model improvement.