本文提出了 VLA-OPD (On-Policy VLA Distillation),一个将离线监督微调 (SFT) 的效率与在线强化学习 (RL) 的鲁棒性相结合的后训练框架。该方法通过在学生策略自生成的轨迹上引入教师模型的 Token 级深度监督,在 LIBERO 和 RoboTwin2.0 基准测试中显著提升了生成策略的采样效率和闭环鲁棒性。
TL;DR
在具身智能(Embodied AI)领域,Vision-Language-Action (VLA) 模型的后训练一直处于“快而不稳”的 SFT 和“稳而极慢”的 RL 之间。香港科技大学(广州)团队提出的 VLA-OPD (On-Policy VLA Distillation) 框架,通过让学生模型在真实环境采样(On-policy),并利用专家模型进行 Token 级的 Reverse-KL 蒸馏,实现了精度、效率与泛化性的完美平衡。
1. 痛点深挖:为什么你的机器人总是“出门就撞墙”?
目前的 VLA 模型训练主要面临两大顽疾:
- 分布偏移 (Distribution Shift):离线 SFT 就像是“看录像学开车”,一旦学生在实际运行中犯了一点小错(进入了 Demo 没覆盖的状态),由于没见过如何纠错,错误会迅速累积导致崩溃。
- 稀疏奖励的梦魇:在线强化学习(如 GRPO)试图通过自探索解决偏移,但机器人任务往往只有“成功/失败”这种二进制奖励。要在数亿参数的模型中靠这种微弱信号找到最优路径,算力开销和时间成本超乎想象。
此外,传统的蒸馏方法也存在缺陷:Forward-KL 强迫学生去覆盖教师所有的可能性,导致面对不确定状态时表现迟疑(熵爆炸);Hard-CE 则只学最高概率动作,导致学生失去多样性(熵塌陷)。
2. 核心机制:VLA-OPD 的“闭环对齐”
VLA-OPD 的直觉非常清晰:让学生大胆去试,让老师实时纠错。
架构解析
该框架包含三个关键阶段:
- 阶段 1:在线采样 (Exploration):学生模型 πθ 亲自下场收集轨迹。这会自动触发模型分布外的未知状态,将“盲区”转化为“已知区”。
- 阶段 2:教师打分 (Correction):冻结的专家老师 πtea 对学生访问的每一个状态给出动作概率分布。
- 阶段 3:众数寻求优化 (Mode-seeking Update):使用反向 KL 散度(Reverse-KL)最小化两者差异。
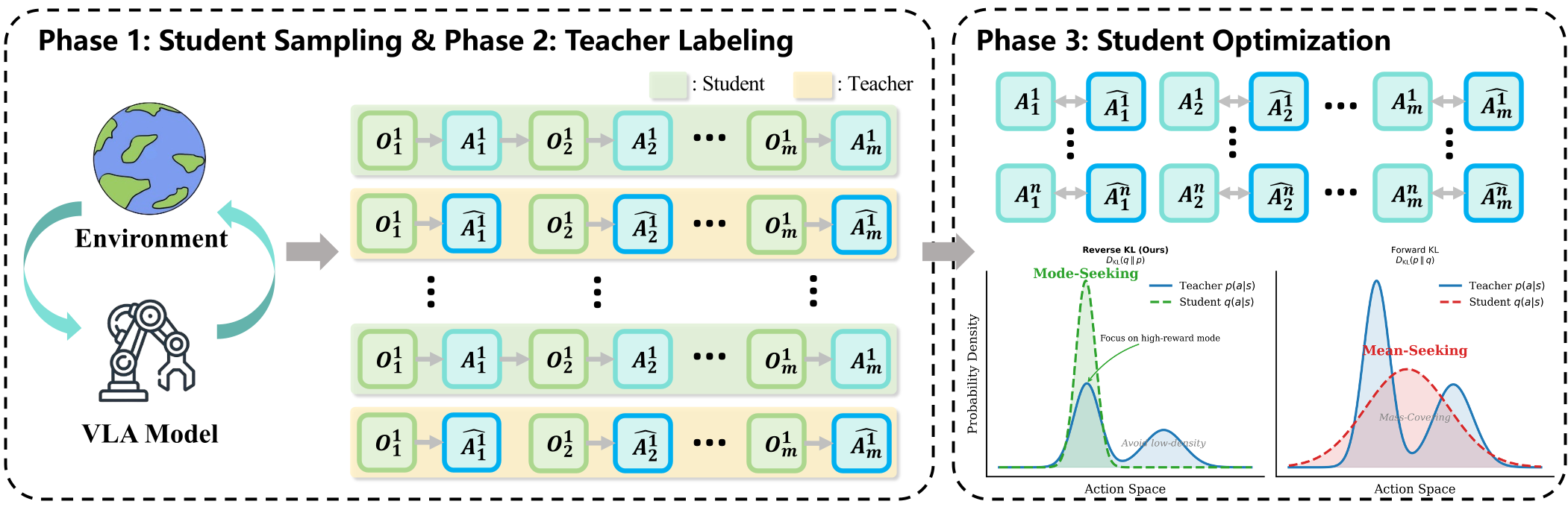
为何选择 Reverse-KL?
这是本文最具学术价值的 Insight。Reverse-KL 具有 Zero-forcing 属性。在老师由于不确定而给出模糊、扁平的分布时,学生只需精准命中其中一个有效的“众数”(Mode),而不需要涵盖所有长尾噪声。这保证了模型决策的果断性(Decisiveness)。
3. 实验战绩:垂直起飞的效率
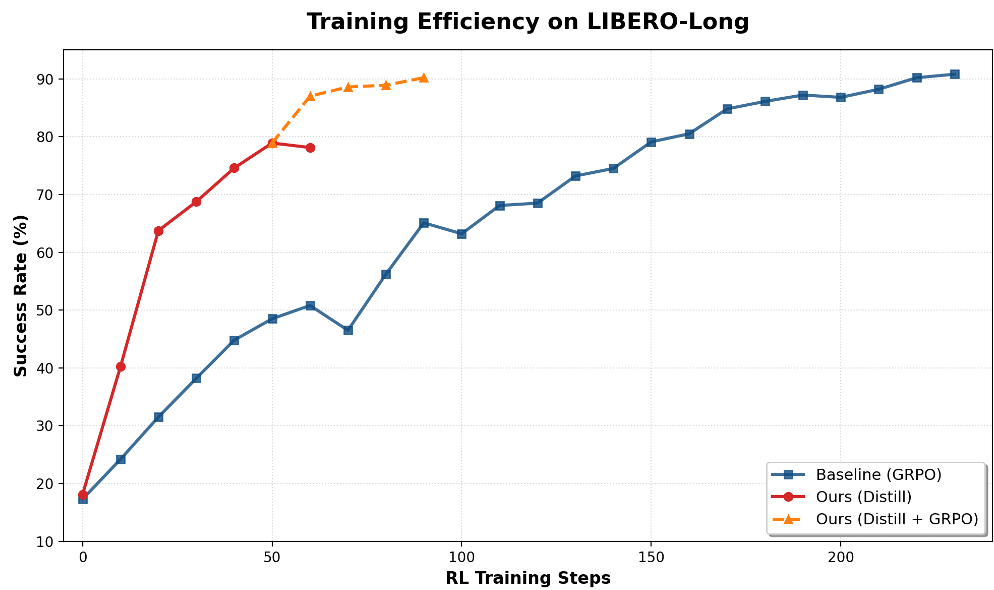
3.1 惊人的采样效率
在 LIBERO-Object 任务中,VLA-OPD 展示了“垂直式”的增长曲线。
- 极速收敛:仅需 10 个 Step 即可超过 90% 成功率,而传统的 GRPO 仍然在低位徘徊。
- 突破上限:配合 GRPO 进行后置微调,可以达到 95.3% 的 SOTA 战绩。
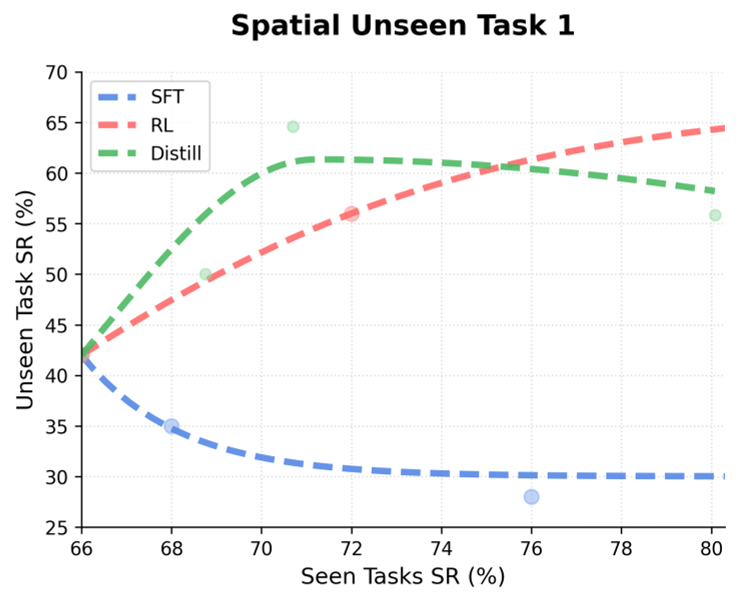
3.2 告别“灾难性遗忘”
通过 Seen-Unseen 权衡分析图(Figure 3)可以发现,离线 SFT 在掌握新任务的同时,旧任务能力会迅速坍塌。而 VLA-OPD 能够保持在图表的右上方,这说明在线蒸馏能更好地保护模型在预训练阶段习得的通用知识(General capabilities)。
4. 深度洞察:消融实验的启示
作者通过对比发现,G(组采样大小) 的选择对稳定性有影响。虽然较大的 G(如 8)能降低梯度方差,但实验表明即使 G=2,模型依然能稳定提升至 80% 以上。这意味着在算力有限的情况下,该框架依然具备极强的实用性。
5. 总结与展望
VLA-OPD 成功的核心在于它意识到:具身智能的精髓不在于模仿轨迹,而在于纠错能力的迁移。
- 优势:极高的采样效率、不丢失通用性、鲁棒的在线闭环表现。
- 局限性:依然依赖一个高性能的 Teachers,尽管目前专家模型已较易获得。
这项工作为未来“边跑边学”的在线机器人学习提供了一个极为高效的标准范式。对于希望将大模型落地到真实工厂、家庭环境的开发者来说,这种“在线纠错蒸馏”的思想是绕不开的必经之路。
本文由资深学术技术主编深度解读,转载请注明出处。