本文提出了 VP-VLA,一种解耦的高级推理与低级控制双系统框架。该方法通过引入“视觉提示”(Visual Prompting)作为接口,利用 System 2 Planner 生成空间锚点(如十字准星和边界框),引导 System 1 Controller 执行精确动作,在 Robocasa 和 SimplerEnv 仿真中分别实现 5% 和 8.3% 的成功率提升。
TL;DR
针对 Vision-Language-Action (VLA) 模型在复杂空间推理和分布外(OOD)场景中表现疲软的问题,香港科技大学与中大的研究团队提出了 VP-VLA。该框架借鉴人类认知的“双系统”理论,利用预训练 VLM 作为 System 2 进行高层规划,并生成十字准星(Crosshair)与边界框(Bounding Box)等视觉提示作为物理坐标锚点,指导 System 1 执行器完成精准操作。
痛点深挖:单体 VLA 的“黑盒”困境
目前的具身智能模型(如 RT-2, OpenVLA)大多采用 Monolithic(单体)架构。这种设计试图让一个神经网络同时学会:
- 理解指令(“把那个红色的苹果放进篮子”);
- 空间理解(苹果在哪里?篮子在坐标系什么位置?);
- 运动控制(机械臂该如何移动、绕开障碍物并精准抓取)。
实验表明,这种架构极易死记硬背训练数据中的颜色或位置分布,一旦遇到没见过的物体或稍微变动的背景,性能就会断崖式下跌。作者发现,甚至把指令换成无意义的乱码,某些模型的表现居然不变——这说明模型根本没有真正理解空间语义,而是在“盲目预测”。
核心方法:VP-VLA 双系统架构
为了打破这一现状,VP-VLA 引入了基于 Visual Prompting 的解耦机制:
1. System 2 Planner (慢思考)
由高性能 VLM(如 Qwen3-VL)担任。它不负责直接控制,而是负责“出谋划策”。
- 事件驱动分解:它只在关键节点(如夹爪状态改变)被触发,将长指令分解为子任务(如“先抓取瓶子”,“再放入微柜”)。
- 视觉接口生成:识别出当前目标物体和目标位置后,模型调用 SAM3 在图像上叠加视觉标记。
2. 视觉提示接口 (The Interface)
这是本文的灵魂设计。与其让控制器从千万个像素中寻找目标,不如直接在图像上“画重点”:
- 十字准星 (Crosshair):标记交互锚点。
- 边界框 (Bounding Box):定义空间约束范围。
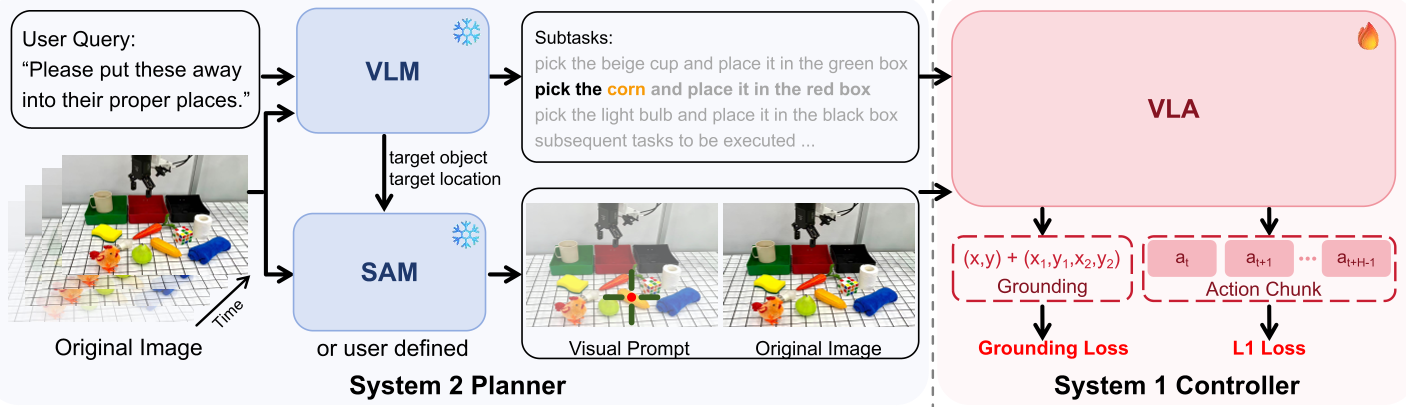
3. System 1 Controller (快思考)
负责高频执行。它接受原始观测 + 视觉提示图像,将任务从“猜测意图”降维打击为“视觉追踪”。
训练中的秘密:辅助对齐 (Auxiliary Grounding)
为了防止模型忽视这些视觉提示,作者引入了一个辅助 Grounding 目标:在关键帧训练时,强迫模型输出提示框的离散坐标。这确保了模型内部表示层与视觉提示保持高度的一致性。
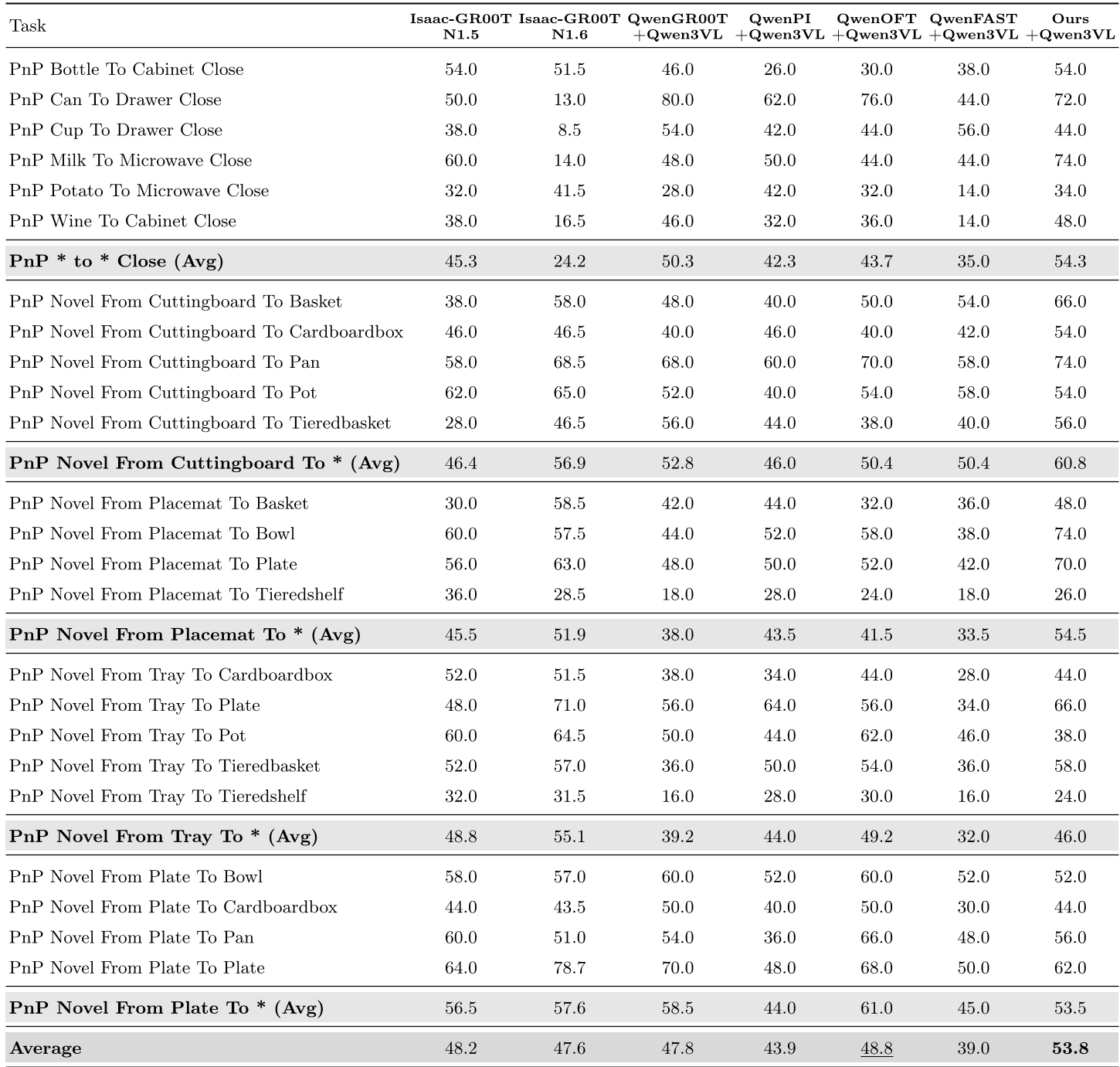
实验与结果:全方位碾压
VP-VLA 在仿真和现实世界中均表现出了极高的统治力:
- 仿真环境:在 Robocasa 厨房任务中,平均成功率达到 53.8%,在涉及“抓取、移动并关门”这类多步复杂任务时,优势尤为明显。
- 现实泛化:在“垃圾分类”实验中,当遇到训练集中未见的物体(如被捏扁的魔方、新颜色的鞋子)时,基线模型性能大幅下降,而 VP-VLA 凭借视觉提示的引导,依然保持了 85% 以上的成功率。
深度洞察
VP-VLA 的成功本质上是将泛化性交给了预训练好的强力 VLM(System 2),而将精准性交给了通过大量机器人轨迹训练的控制器(System 1)。通过“画重点”的方式,它大幅降低了底层控制器的推理负担。
局限性:目前 System 2 的触发依赖于夹爪状态等物理事件,未来若能实现更加自主、基于不确定性的主动规划触发,系统的自适应能力将进一步增强。
总结
VP-VLA 证明了:在走向通用机器人的道路上,结构化的中间表征(如视觉提示)比纯端的端到端黑盒更具潜力和透明度。这种“所见即所标,标到即做到”的思路,为未来长程、复杂的家用机器人任务提供了一个极具参考价值的范式。