本文推出了 Wan-Weaver,一个采用混合 Transformer (MoT) 架构的多模态生成统一模型。通过将交错生成任务解耦为“规划 (Planner)”与“视觉化 (Visualizer)”,该模型在不依赖真实交错数据的情况下,实现了长推理性文本与高度一致性图像的交错生成,性能比肩顶级商用模型 Nano Banana。
TL;DR
在多模态领域,让模型“读懂”图文不难,但让它像人类博客作家一样“创作”出逻辑严连、图文对应的长篇交错内容却极难。阿里巴巴通义实验室与清华大学联合提出的 Wan-Weaver 给出了一套优雅的解法:既然高质量交错数据少,那就把任务拆开——让 Planner 学习“怎么写和怎么配图”,让 Visualizer 学习“怎么根据配图描述画出一致的画”。
核心动机:为何交错生成如此之难?
多模态统一模型(Unified Multi-modal Models)的研究目前大多集中在“单向输出”上。即便像 GPT-4o 这样的模型,在处理多轮交错输出时也常常出现:
- 视觉不一致:第一张图的猫是橘色的,第二张变成了花猫。
- 逻辑断层:文字描述了某个场景,但配图却牛头不对马嘴。
- 训练不稳:Autoregressive(自回归)训练和 Diffusion(扩散)训练目标的量级与分布差异巨大,强行联合训练往往会导致模型“顾此失彼”。
方法论:解耦与协作的艺术
Wan-Weaver 的架构核心是 MoT (Mixture-of-Transformers),由两名专门的“专家”组成:
1. 规划专家 (Planner):文本代理的力量
作者引入了 Textual-proxy (文本代理) 概念。与其寻找稀缺的交错图文对,不如利用强大的 VLM 将图像转换成一段极其详尽的描述性文字(放在 <imagine> 标签内)。
- 作用:让模型在语言空间内学习何时该“插图”,以及插什么样的图。
- 直觉:由于 LLM 对文本序列的建模能力远超图像 Token,这种方式能极大地提升长程逻辑的一致性。
2. 视觉专家 (Visualizer):参考引导的一致性
为了解决“橘猫变花猫”的问题,Wan-Weaver 的 Visualizer 在训练时加入了大量的 Reference-guided data。
- 密集提示词上下文窗口 (DPCW):通过特定的 Attention Mask,让 Visualizer 不仅看当前的 Dense Prompt,还能回溯之前生成的文案和图像特征。
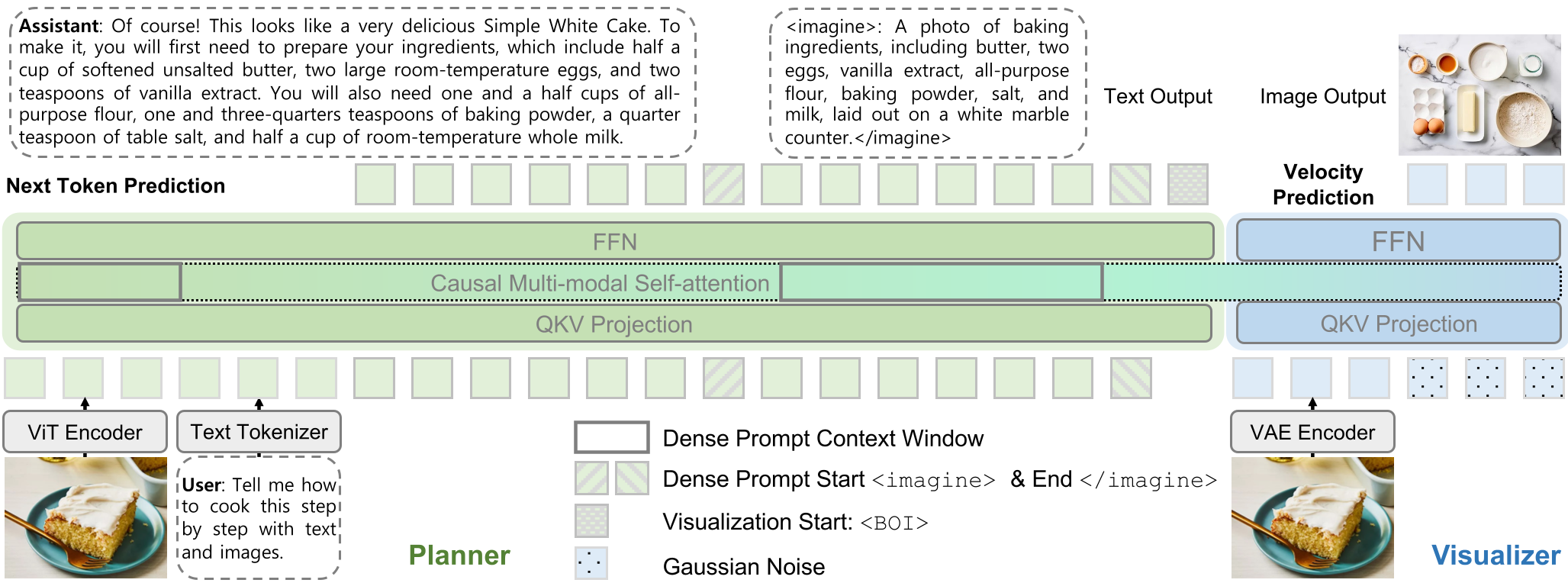 图 1:Wan-Weaver 推理流程。Planner 负责规划逻辑和生成密集 Prompt,Visualizer 在 DPCW 的引导下实现高一致性图像合成。
图 1:Wan-Weaver 推理流程。Planner 负责规划逻辑和生成密集 Prompt,Visualizer 在 DPCW 的引导下实现高一致性图像合成。
实验战绩:开源界的新标杆
作者构建了 WeaverBench,涵盖了百科、美食、旅游、教育等 15 个真实使用场景。
- 性能对比:在与 Emu3, SEED-X 以及集成的 GPT-4o+DALL-E 3 方案对比中,Wan-Weaver 在提示词遵循度(Prompt Adherence)和叙事协调性上均处于领先地位。
- 稳定性:如下方的消融实验曲线所示,解耦训练(橙色线)的 Loss 下降比联合训练(蓝色线)平滑且快速得多,证明了模态隔离训练的优越性。
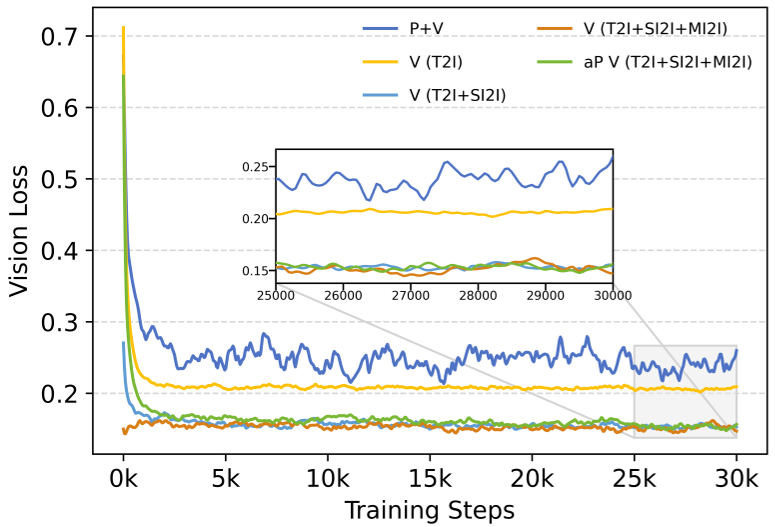 图 2:不同训练策略的收敛曲线。解耦训练不仅效率更高,且避免了模态冲突导致的振荡。
图 2:不同训练策略的收敛曲线。解耦训练不仅效率更高,且避免了模态冲突导致的振荡。
深度洞察:不仅仅是生成
Wan-Weaver 最令人惊喜的一点在于,即使强化了生成能力,其理解能力 (Understanding) 并未退化。在 MMMU 和 MathVista 榜单上,它依然保持了与 Qwen2.5-VL 原始模型相近的水平。
这带来了一个重要的行业启示:多模态生成的关键或许不在于模态的强行融合,而在于如何让语言模型作为“大脑”进行高质量的跨模态语义规划。
局限性与展望
尽管表现强劲,Wan-Weaver 目前在自动适配分辨率(目前需手动或固定设置)以及超长序列下的显存增量上仍有改进空间。此外,作者也提到,“生成辅助理解”的逆向增强效应目前还不明显,这或许是迈向下一代 AGI 的下一个突破口。
总结:Wan-Weaver 为我们展示了在有限数据下,如何通过精巧的任务解耦和数据工程,让 AI 真正具备“图文并茂”的创作才华。