本文提出了 SCRL (Selective-Complementary Reinforcement Learning),一种针对大语言模型推理任务的测试时强化学习 (TTRL) 框架。该方法通过“选择性正向伪标签”和“熵门控负向伪标签”相结合的策略,在无需外部标签的情况下,利用群体共识和生成不确定性显著提升了模型在 AIME、MATH 等挑战性数学竞赛题上的推理表现。
TL;DR
在没有标准答案的情况下,大模型如何通过“自编自演”不断变强?传统的测试时强化学习 (TTRL) 迷信“少数服从多数”,但在高难度题目面前,多数派往往也是错的。本文提出的 SCRL (Selective-Complementary Reinforcement Learning) 给出了一种更冷静的策略:如果看不准对错,宁可不强化(选择性正向标签),同时坚决放弃那些“又怪又乱”的错误尝试(熵门控负向标签)。
痛点深挖:多数投票的“暴政”
在大模型推理领域,多数投票 (Majority Voting) 被视为一种天然的伪奖励信号。然而,作者敏锐地观察到,这一逻辑在极难任务(如 AIME 竞赛题)中会彻底崩塌:
- 分布离散化:当问题太难,所有模型生成的答案可能都不一样,此时即便某个答案出现了 2 次,它也极可能是错的。
- 噪声放大:GRPO 等强化学习算法会对这些稀有的伪标签进行组内归一化,导致模型以极大的学习率去“猛练”一个错误的答案。
- 忽视负面信号:现有的 TTRL 几乎只关注“奖励对的”,却忘了“惩罚错的”也能帮助模型缩小搜索范围。
方法论详解:既要“精挑细选”,也要“去芜存菁”
SCRL 的核心架构由三部分组成,旨在构建一个风险厌恶型(Risk-Averse)的强化学习循环。
1. 选择性正向伪标签 (Selective Positive Pseudo-Labeling)
作者不再无条件相信第一名,而是给“多数派”设置了两道关卡:
- 置信度关卡 ():最高频答案的占比必须够高。
- 区分度关卡 ():第一名必须显著超过第二名(Margin)。 只有通过这两关,模型才会进行正向强化。否则,模型选择“弃权”,避免引入噪声。
2. 熵门控负向伪标签 (Entropy-Gated Negative Pseudo-Labeling)
这是本文最惊艳的设计。作者发现:识别错误比识别正确更容易。
- 不确定性度量:利用模型生成过程中的平均 Token 熵来定义轨迹的不确定性。
- 负面判别准则:如果一个答案出现频率极低(Low Support),且其轨迹熵高于平均水平(High Uncertainty),则判定其为“低质量错误”,赋予负奖励。
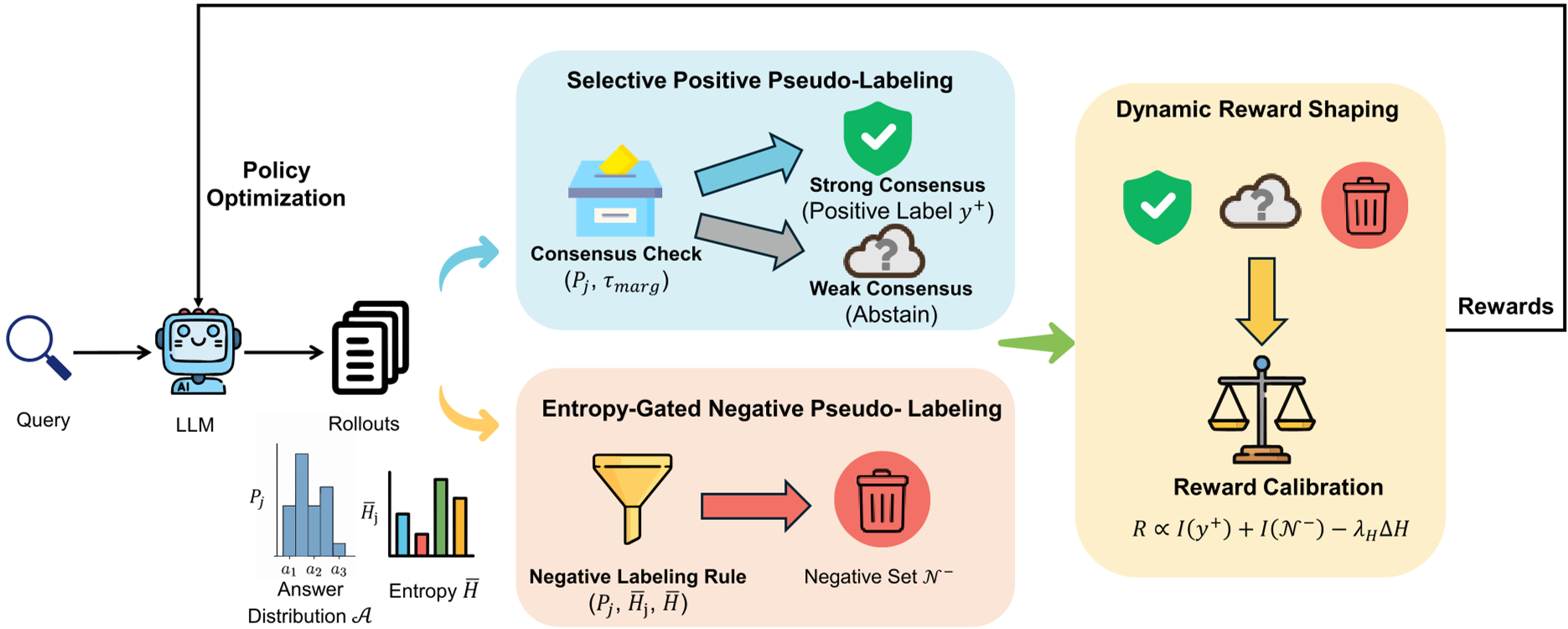 图 1:SCRL 框架概览。左侧展示了正向标签的筛选,右侧展示了基于熵门控的负向标签生成及动态奖励塑造。
图 1:SCRL 框架概览。左侧展示了正向标签的筛选,右侧展示了基于熵门控的负向标签生成及动态奖励塑造。
实验与结果:小样本下的逆袭
SCRL 在多个数学和逻辑竞赛数据集上展现了统治力,特别是在 Rollout Budget(采样数)受限 的情况下。
- 大幅度超越 SOTA:在 Qwen2.5-Math-7B 上,SCRL 在 AIME25 上的表现从 16.8% 飙升至 26.9%。
- 解决训练崩溃:在 Minerva 数据集上,传统的 TTRL 常因为噪声过大导致训练在中途崩盘(图中星号标记),而 SCRL 表现极其平稳。
 表 1:不同模型与采样预算下的性能对比。可以看到 SCRL 在 AIME25 和 Minerva 上的惊人提升。
表 1:不同模型与采样预算下的性能对比。可以看到 SCRL 在 AIME25 和 Minerva 上的惊人提升。
深度洞察:为什么熵是关键?
为什么负向标签这么管用?作者在消融实验中发现,如果不加“熵门控”,仅仅惩罚低频答案,效果会变差。这是因为有些“稀有答案”可能是模型通过艰苦思考得到的正确解。通过熵 (Entropy) 这一物理直觉,SCRL 成功区分了“灵光一现的独特见解(高置信度/低频)”和“胡言乱语的幻觉(高熵/低频)”。
总结与局限
SCRL 证明了在 Test-Time 阶段,负反馈 (Negative Feedback) 的引入是提升推理稳健性的关键。
局限性分析: 在 5.6 节的失败分析中,作者坦诚在 Minerva 这种极度依赖物理专业知识的任务上,如果基座模型(如 Qwen-3B)本身太弱,导致全场没有一个正确答案时,SCRL 的保守策略可能会导致“学习停滞”。这提示我们:TTRL 的天花板依然取决于模型初始的知识储备。
通过 SCRL,我们看到了一种向 OpenAI o1 类模型进化的路径:不仅要会“思考”,更要学会“如何通过统计特征自我过滤”。