This paper presents a comparative robustness study between Vision-Language-Action (VLA) models and World Action Models (WAMs). By evaluating them on the LIBERO-Plus and RoboTwin 2.0-Plus benchmarks under seven types of perturbations, the study discovers that WAMs (like LingBot-VA and Cosmos-Policy) generally generalize better to visual noise and layout changes due to spatiotemporal priors from video pretraining.
TL;DR
Is the secret to a smarter robot a language model or a video generator? This paper conducts a rigorous stress test of Vision-Language-Action (VLA) models versus the emerging World Action Models (WAMs). The verdict: WAMs are significantly more robust to visual "chaos" (noise, lighting, distractors) because they've "watched" the world move through internet-scale video, but they are currently too slow for lightning-fast real-world reactions.
Problem & Motivation: The "Fragility" of VLAs
Most current robot brains (VLAs) are built on top of Vision-Language Models like CLIP or Llama. While these models are great at identifying a "red mug," they are notoriously fragile. A slight change in lighting, a bit of sensor noise, or a few extra objects on a table can cause a VLA to fail because it doesn't truly understand the physics of motion—it only predicts the next "token" or action based on static visual patterns.
The authors argue that we need World Models: systems that explicitly predict how the environment changes. By pretraining on millions of videos, these models develop a "Physical Intuition" that allows them to ignore noise and focus on the dynamics of the task.
Methodology: Repurposing Video Generators
The core innovation of WAMs is treating robot control as a future-state prediction task. Instead of just mapping Image -> Action, a WAM does:
- State Prediction:
(Current Image, Instruction) -> Predicted Future Image. - Action Decoding: Using the predicted future to guide the actual robot movement.
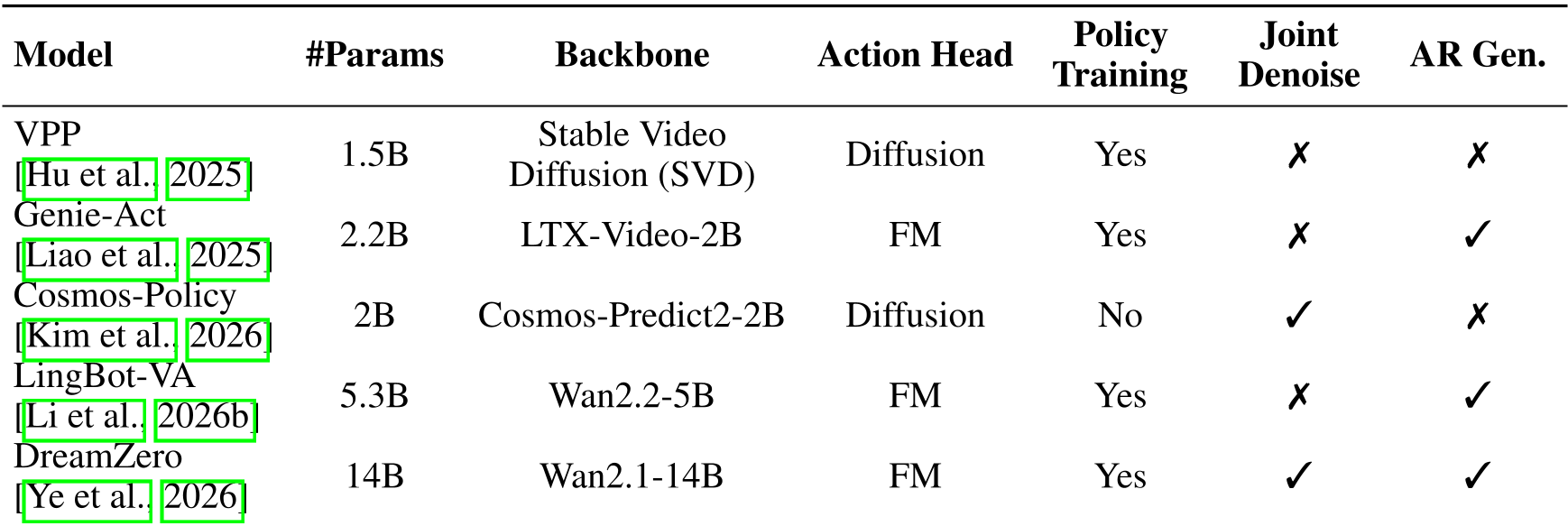
The study compares specialized models like Cosmos-Policy and LingBot-VA against heavyweights like π0.5. While VLAs like π0.5 require massive amounts of diverse robotic data to learn robustness, WAMs inherit much of this "for free" from their video-generation backbones.
Experiments: Performance Under Fire
The researchers used RoboTwin 2.0-Plus and LIBERO-Plus, benchmarks that introduce "perturbations" like fog, glass blur, and dramatic side-lighting.
Key Result 1: WAMs Win on Visual Noise
In tasks involving heavy sensor noise (N3) or cluttered layouts, WAMs consistently outperformed VLAs. LingBot-VA reached a 74.2% overall success rate on the bimanual RoboTwin benchmark, far surpassing the 58.6% of π0.5.

Key Result 2: The Geometry Achilles' Heel
Interestingly, WAMs are not universally better. When the camera viewpoint or the robot's starting position changed significantly, WAMs struggled. This suggests that while video pretraining helps with "what things look like when they move," it doesn't necessarily help with 3D spatial reasoning or geometric shifts.
The "Speed Tax": The Runtime Reality
The biggest barrier to WAM adoption is latency. Because WAMs rely on diffusion or flow-matching processes to "imagine" the future, they are computationally expensive.
- π0.5: 63ms per inference.
- LingBot-VA: Up to 5.2 seconds per inference.
A robot that takes 5 seconds to "think" between moves is useless in a dynamic environment where it might need to catch a falling object or navigate a crowded room.

Critical Analysis & Conclusion
This paper provides a sobering look at the current state of Robotic AI.
- The Takeaway: If you want a robust robot in a messy environment and have high-end GPUs to spare, WAMs are the way to go.
- The Limitation: WAMs are currently "too heavy." The industry needs to focus on distillation (shrinking these models) and improving geometric grounding (helping them understand 3D space, not just 2D video pixel transitions).
The future likely lies in Hybrid Models—VLA frameworks (like VLA-JEPA or MOTUS) that incorporate "world model" auxiliary tasks during training without inheriting the full inference weight of a massive video generator.