本文对世界动作模型 (WAMs) 与传统视觉-语言-动作模型 (VLAs) 的鲁棒性进行了系统性对比研究。通过在 LIBERO-Plus 和 RoboTwin 2.0-Plus 两个基准测试上的实验证明,以 LingBot-VA 和 Cosmos-Policy 为代表的 WAMs 在面对光照、噪声和布局扰动时表现出远超 VLAs 的泛化能力。
TL;DR
在机器人控制领域,到底是让模型“读懂文字并看图说话”(VLA)更重要,还是让模型“预知未来并感知物理”(World Model)更重要?华为与多伦多大学的最新研究通过 RoboTwin 2.0-Plus 压力测试给出答案:世界动作模型 (WAMs) 在应对现实世界复杂干扰(光照、噪声、杂乱布局)时,凭借视频预训练带来的时空先验,展现出了远超传统 VLA 的鲁棒性。
1. 痛点:VLA 的“物理文盲”困境
目前的视觉-语言-动作模型(VLA)虽然在语义理解上表现出色,但其骨干网络多为在静态图文对上训练的 VLM。它们对物理世界的动力学(Dynamics)缺乏直观认知:
- 泛化瓶颈:一旦测试环境光照稍微变暗,或背景多了一个水杯,模型往往会因“由于没见过这种分布”而产生幻觉动作。
- 数据饥渴:为了获得鲁棒性,VLA 通常需要通过 Cross-embodiment 学习数万小时的多样化机器人数据。
相比之下,世界动作模型 (WAMs) 直接站在了“视频生成”这一巨人的肩膀上。
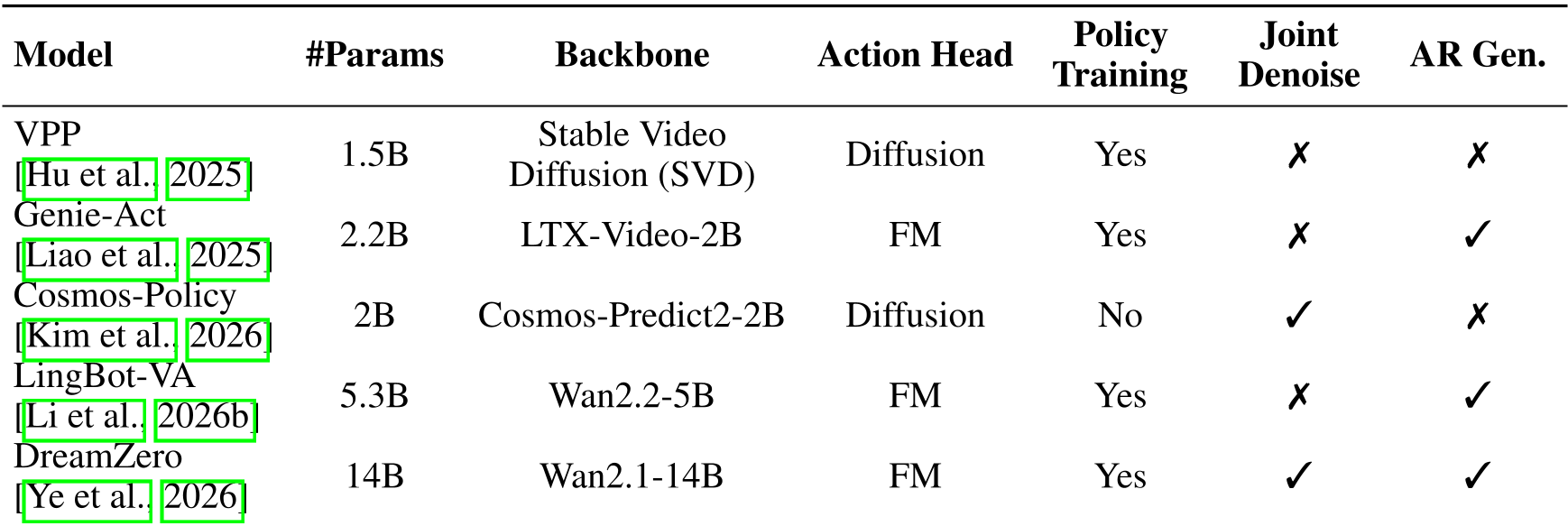
2. 核心机制:WAM 如何实现“预知未来”?
WAM 的核心逻辑是将机器人动作生成视为一种“受控的视频生成”问题。其工作流程通常分为两类:
- 联合去噪 (Joint Denoising):模型同时在潜在空间中对未来视频帧和机器人动作进行去噪(如 Cosmos-Policy)。
- 逆动力学解码 (IDM Decoding):先利用预测模型输出未来状态 ,再配合当前状态 通过一个小型的解码头得到动作 (如 LingBot-VA)。
这种设计的本质优势在于:视频预训练已经教会了模型什么是重力、什么是刚体碰撞、什么是物体的连贯运动。 即使输入图像有噪声,世界模型也能在内部潜空间里“脑补”出清晰的动作路径。

3. 实验对决:WAM vs. VLA 的巅峰博弈
研究团队在 LIBERO-Plus(单臂)和 RoboTwin 2.0-Plus(双臂 Aloha 环境)上进行了大规模基准测试,涵盖了相机位姿、光照、背景纹理、语言指令等 7 大类扰动。
关键发现 1:WAM 在视觉极端环境下几乎“免疫”
实验显示,在噪声(Noise)和杂乱布局(Layout)下,WAM 模型(如 LingBot-VA)的性能跌落远小于 π0.5。尤其是在“敲击方块”等任务中,当环境中出现大量干扰物体时,VLA 容易与障碍物碰撞,而 WAM 能准确识别物理占位并保持动作轨迹。
关键发现 2:VLA 靠“刷题”补救,WAM 靠“天赋”胜出
- π0.5 表现很强,但作者指出这归功于其训练数据中混入了海量的移动操纵和 Web 端多样化视频。
- WAM 则表现出更高的“数据效率”。在只用领域内少量数据训练的情况下,它在视觉扰动下的鲁棒性依然稳健。

4. 深度洞察:代价是什么?
尽管 WAMs 展现了强悍的泛化能力,但其落地仍面临一大难关:推理延迟 (Inference Overhead)。
- 由于核心是扩散模型 (Diffusion) 或流匹配 (Flow Matching),每一次动作生成都需要多次迭代去噪。
- 数据对比:π0.5 单步推理仅需 63ms,而 LingBot-VA 在某些环境下甚至需要 5 秒以上。这对于需要 50Hz 实时响应的精细操作任务来说,几乎是不可接受的。
5. 总结与展望
这篇文章为机器人社区提供了一个非常清晰的信号:显式的时空建模(World Modeling)不仅仅是用来做模拟器的,它直接提升了 Policy 的天花板。
未来的三个趋势:
- 混合架构:如 MOTUS 和 VLA-JEPA,尝试将视频预训练的辅助任务引入 VLA,以寻求平衡。
- 端到端加速:研究如何将 WAM 的去噪步数压缩到 1-3 步(One-step World Models)。
- 从语义到物理:机器人模型将从单纯的语言对齐转向更底层的物理规律对齐。
对研究者而言,如果你追求极致的稳定性,WAM 是目前最有潜力的方向;如果你需要立刻部署,通过大规模多样化数据增强的 VLA(如 π0.5)依然是当前的最优选。