本文推出了 WR-Arena,这是一个旨在评估世界模型(World Models, WMs)作为“下一代世界模拟器”能力的综合基准测试。该框架从动作模拟保真度、长程预测和模拟推理规划三个维度,对模型在复杂、多步交互环境中的表现进行了深度评估,并揭示了当前 SOTA 模型与人类水平推理之间的显著差距。
TL;DR
尽管 OpenAI 的 Sora 或 NVIDIA 的 Cosmos 被誉为“世界模拟器”,但它们真的理解物理因果并能辅助规划吗?MBZUAI 的 PAN 团队发布的 WR-Arena 基准测试给出了冷峻的答案:当前的 SOTA 模型在处理长程一致性和环境干预模拟方面依然存在显著短板。该基准从动作保真度、长程预测及模拟推理三大维度重定义了世界模型的评价标准,并指出 PAN 模型通过联合优化理解与控制,在实际规划任务中大幅领先。
背景定位
在学术坐标系中,WR-Arena 不仅仅是一个新的数据集,它是一次从“感知(Perception)”向“推理(Reasoning)”的评价范式转移。它挑战了“视觉保真度等于物理模拟能力”的流行假设,为下一代具身智能(Embodied AI)所需的内部模拟引擎树立了诊断性的指南针。
痛点深挖:视觉华丽不代表模拟真实
目前的世界模型评测存在两大误区:
- 单步跳跃:多数基准只看 $s o s'$ 的一瞬间预测,忽略了在多步指令下,模型是否会“忘了初心”或导致物体凭空消失。
- 被动预测:模型通常只是被动地补全视频,而非作为智能体的“思想实验”引擎去比较不同行动方案的后果。
作者指出,一个成熟的世界模型必须能够处理**反事实(Counterfactual)**模拟——即“如果我这样做,世界会发生什么?”,这正是当前模型最薄弱的环节。
方法论详解:WR-Arena 的三大支柱
1. 动作模拟保真度 (Action Simulation Fidelity)
这部分测试模型是否能听懂人话。例如,给一张厨房照片并下令“做一道菜”,模型能否生成一系列符合物理逻辑的图像序列?
- Agent Simulation:控制主体行为(保持背景稳定)。
- Environment Simulation:对环境进行干预(如:让晴天变暴雨),测试因果逻辑。
2. 长程预测 (Long-horizon Forecast)
这是评估 WMs 稳定性的金标准。作者引入了 Multi-round Smoothness (MRS) 指标,通过光流(Optical Flow)检测帧间加速度,惩罚由于误差累积导致的画面猛烈跳变(Jerks)。同时使用 Additive Penalty (AP) 指标,随着轮数增加呈指数级加重对一致性下降的惩罚。
3. 模拟推理与规划 (Simulative Reasoning and Planning)
这是该论文最精彩的部分:让 VLM 模型(如 GPT-4o 或 o3)作为规划者,而把世界模型作为“沙盒”。规划者提出几种策略,WM 模拟出对应的结果,最后再选出最优路径。如果 WM 模拟得一塌糊涂,规划者的表现就会大幅下降。
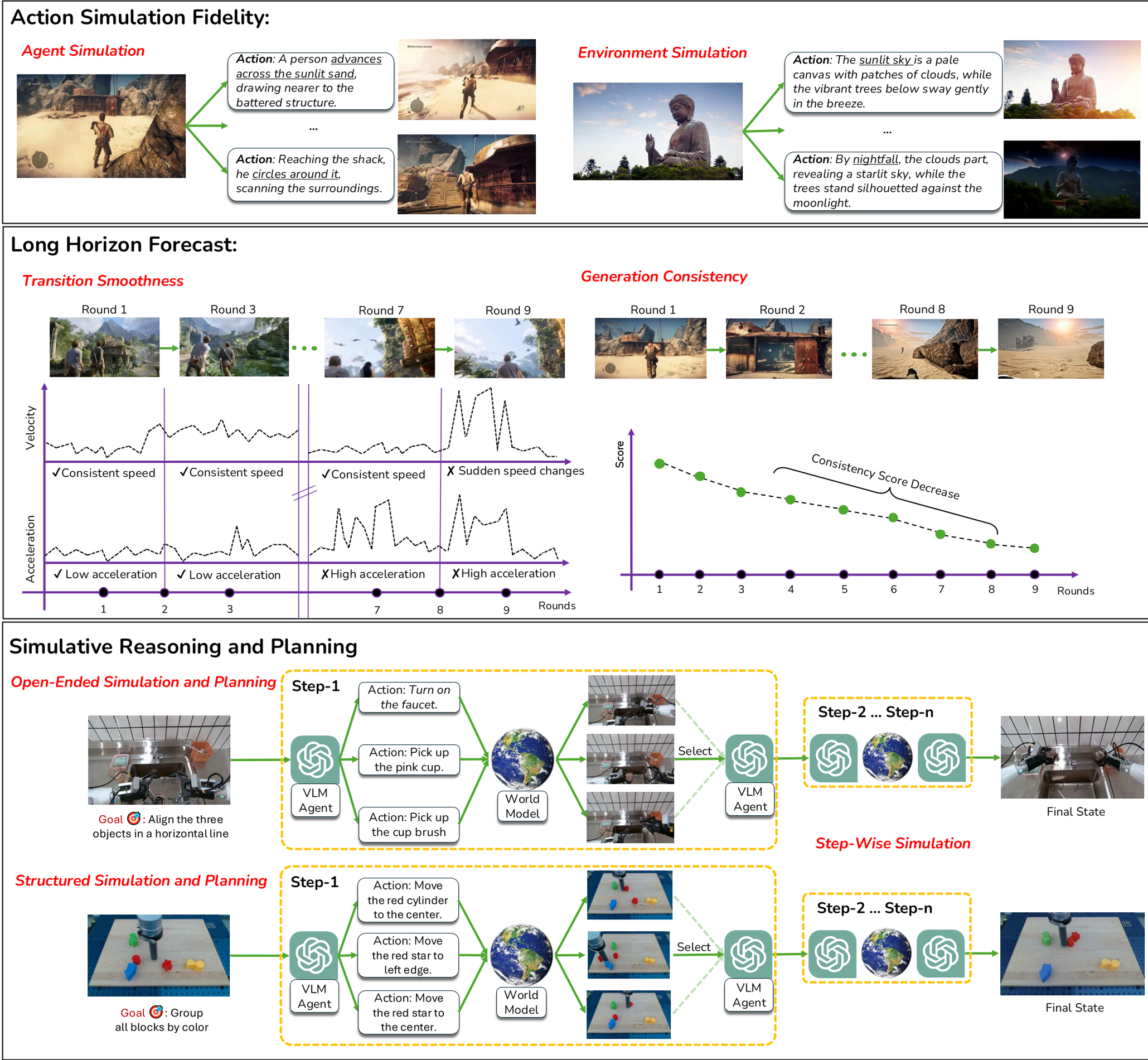 图 1:WR-Arena 的任务分类学。涵盖了从简单的手臂操作到复杂的驾驶场景干预。
图 1:WR-Arena 的任务分类学。涵盖了从简单的手臂操作到复杂的驾驶场景干预。
实验与结果:PAN 模型的反杀
研究团队对比了商业模型(KLING, MiniMax, Gen-3)和学术开源模型(Cosmos, V-JEPA2, PAN)。
- 一致性瓶颈:随着步骤增加,所有模型的表现都呈现单调下降,其中 WAN 2.1 下降最剧烈。
- 环境模拟是重灾区:所有模型在处理“场景级别干预”时的准确率均低于 60%,显示出模型对复杂因果链的理解仍然非常表面。
- PAN 的平衡性:PAN 模型在长程预测上表现最稳,这归功于其使用的自强制训练和将 VLM 先验与动作-状态对齐微调相结合的策略。
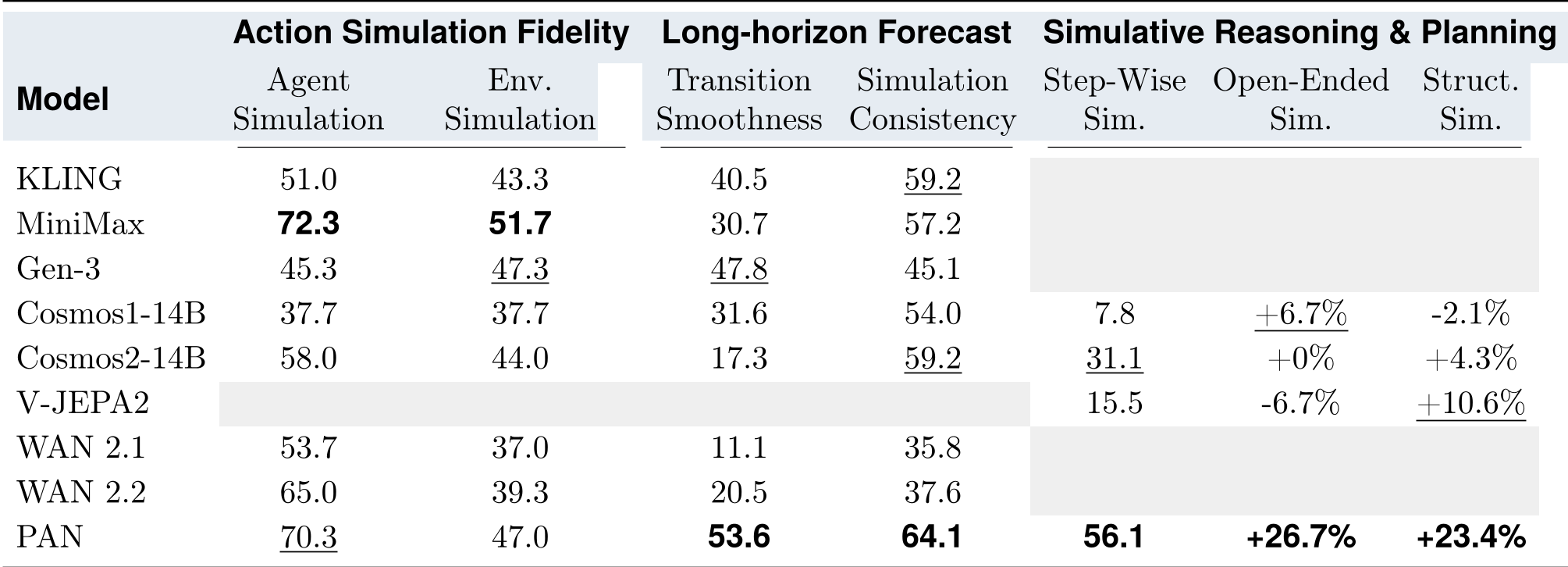 表 1:各维度表现对比。可以看到 PAN 在模拟推理(Simulative Reasoning)上为规划任务带来了 20% 以上的增益。
表 1:各维度表现对比。可以看到 PAN 在模拟推理(Simulative Reasoning)上为规划任务带来了 20% 以上的增益。
深度洞察与总结
核心贡献 (Takeaway)
- 定义了新深度:世界模型不只是“视频生成器”,它的本质是“推理引擎”。
- 指标创新:引入 MRS 解决了视频平滑度难以量化的难题。
- 范式建议:证明了联合优化“理解、预测、控制”优于将其视为独立模块。
局限性与挑战 (Limitations)
尽管 PAN 表现出色,但在处理高度动态或复杂的语义指令时,依然无法达到人类水平。模型对于“物理常识”的理解往往是统计学意义上的相关性,而非真正的因果推演。
未来展望
WR-Arena 为行业提供了一个诊断工具。未来的研究不应再盲目追求像素级的真,而应转向语义级别的准。能否在保证视觉质量的同时,通过更强的架构(如 SSMs 或更先进的 Transformer 变体)维持数分钟的逻辑自洽,将是通往物理 AI 的关键。