本文提出了名为 Video-to-World 的新方法,旨在解决视频扩散模型(VDM)生成的帧序列在 3D 空间中不一致(Generative Drift)的问题。通过结合几何基础模型与非刚性 ICP 对齐技术,该方法成功将写实但不一致的视频转化为高质量、可实时探索的 3D Gaussian Splatting 世界。
TL;DR
视频扩散模型(VDM)生成的视频虽然好看,但在 3D 空间里往往是“扭曲”的。慕尼黑工业大学(TUM)的研究团队提出了 Video-to-World,一种通过非刚性几何对齐(Non-rigid Alignment)来修正 VDM 生成缺陷的方法。它不需要重新训练庞大的生成模型,仅靠重建侧的轻量级优化,就能将不一致的视频帧转化为高保真、可全向探索的 3D Gaussian Splatting 场景。
1. 痛点:为什么“写实”的视频无法直接变成 3D 世界?
目前的视频生成模型(如 Sora、Wan-2.2)具备极强的常识理解力,但它们在生成过程中存在一个致命伤:生成性漂移(Generative Drift)。这意味着当你让模型绕着一个物体转一圈时,物体的形状、位置甚至纹理会随着每一帧的生成发生细微的非刚性形变。
如果使用传统的 SFM 或刚性 3DGS 重建:
- 几何重叠:同一物体的表面在 3D 空间中会出现多层重影。
- 浮空伪影:由于相机参数与几何不匹配,背景中会出现大量类似云雾的漂浮碎片。
- 纹理模糊:为了强行拟合不一致的像素,优化过程会使纹理变得模糊。
2. 核心直觉:将不一致视为“非刚性运动”
作者的巧妙之处在于:既然视频帧之间是不一致的,与其强行用“刚性”的 3D 框架去套,不如把这些不一致看作是物体在进行微小的非刚性运动。
2.1 整体架构流程
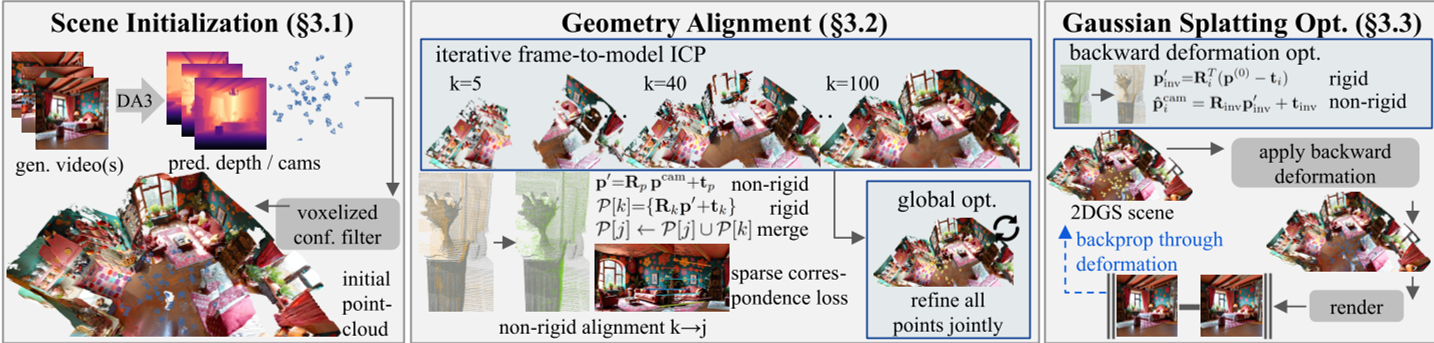
- 场景初始化:利用几何基础模型(GFM,如 DepthAnything-3)为每一帧估计深度和相机姿态,将其“提起”(Lift)为原始点云。
- 非刚性 ICP 对齐:这是本文的核心。作者通过一个 Hashgrid MLP 预测每个点的 Twist 坐标,将各帧点云非刚性地对齐到一个统一的 Canonical 空间。
- 逆变形渲染(Inverse Deformation Rendering):在最后的 Gaussian Splatting 优化阶段,高斯球分布在 Canonical 空间,但渲染时会先利用逆向变形网络将其变换回“有缺陷”的视频帧空间进行损失计算。这样既保留了视频的高保真纹理,又确保了 3D 结构的统一。
3. 实验战绩:化腐朽为神奇
在对比实验中,Video-to-World 展示了远超基线的 viewpoint stability。

- 一致性:在 WorldScore 评测中,相比于目前最强的 3DGS-MCMC 方法,其 3D 一致性和光度一致性分别从 60s 提升到了 80s 这一数量级。
- 视觉保真度:渲染图几乎保留了 VDM 生成的所有细节,消除了由于几何对齐不良导致的颗粒感。
消融分析 (Ablation Study)
作者证明,如果没有“逆变形(Inverse Deformation)”损失(即上图中的 no inv),即便点云对齐了,最终的渲染效果仍会因为强行拟合不一致的像素而变得极其模糊。

4. 深度洞察与总结
该工作的学术定位
Video-to-World 是对“视频生成驱动 3D 重建”这一路径的重要修补。在学界追求“One-step 3D 垂直生成”的同时,本文提醒我们:现有的高质量 VDM 已经包含了足够的几何先验,只是需要合适的“胶水”(非刚性配准)来消除其概率随机性带来的不一致。
局限性分析
尽管解决了几何偏移,但该方法仍无法处理 VDM 的瞬间幻觉(Hallucinations),例如原本没有的路灯在镜头转回来时突然出现。未来的研究方向可能需要引入鲁棒性损失函数(Robust Losses)来自动剔除这类“幻觉帧”。
结论:这项工作为机器人训练数据生成、VR/游戏场景快速建模提供了一种极具吸引力的插件化方案,真正让“视频即世界”成为了可能。